

AI 대형 모델의 ‘중국어 세금’: 중국어가 영어보다 토큰을 더 많이 소비하는 이유는?
Opus 4.7이 막 출시된 직후, X(트위터)에서는 항의가 빗발쳤다. 어떤 이는 단 한 차례의 대화로 세션 할당량을 모두 소진했다고 했고, 또 다른 이는 동일한 코드를 실행하는 데 드는 비용이 지난주보다 두 배 이상 급등했다고 불평했다. 심지어 어떤 사용자는 200달러짜리 Max 구독료를 결제한 지 두 시간도 채 안 돼 제한에 도달한 스크린샷을 공유했다.
독립 개발자 BridgeMind는 클로드(Claude)가 세계 최고의 모델이자 동시에 가장 비싼 모델이라고 인정했다. 그의 Max 구독은 두 시간도 채 안 돼 한도에 도달했지만, 다행히도—그는 두 개를 구입했다.|출처: X@bridgemindai
Anthropic의 공식 가격은 변함없다. 입력 토큰 1백만 개당 5달러, 출력 토큰 1백만 개당 25달러다. 그러나 이번 버전은 새로운 토크나이저(tokenizer)를 도입했으며, 동시에 Claude Code의 기본 effort 수준을 ‘high’에서 ‘xhigh’로 상향 조정했다. 이 두 가지 변화가 겹치면서, 동일한 작업에 소비되는 토큰 수가 기존의 2배에서 최대 2.7배까지 증가했다.
이 논의들 속에서 나는 중국어와 관련된 두 가지 주장에 주목했다. 첫 번째는 “새 토크나이저 하에서 중국어는 거의 오르지 않았고, 중국어 사용자들은 이번 가격 인상을 피해 갔다”는 것이었다. 두 번째는 더 흥미로운데, 바로 “고문(고대 중국어)이 현대 중국어보다 오히려 토큰을 덜 소비하므로, AI와 고문으로 대화하면 비용을 절약할 수 있다”는 주장이었다.
첫 번째 주장은 클로드가 중국어를 위해 특정 최적화를 수행했다는 것을 암시하지만, Anthropic의 공식 발표 문서에는 중국어 관련 조정 사항은 전혀 언급되어 있지 않다.
두 번째 주장은 설명하기가 더욱 어렵다. 고문은 인간 독자에게 분명히 현대 중국어보다 이해하기 어려운데, 인간에게 더 복잡한 텍스트가 어떻게 AI에게는 더 쉬울 수 있을까?
그래서 나는 테스트를 진행했다. 상업 뉴스, 기술 문서, 고문, 일상 대화 등 다양한 유형의 22개 평행 텍스트를 준비해 클로드 4.6 및 4.7, GPT-4o, Qwen 3.6, DeepSeek-V3 등 총 5개 토크나이저에 동시에 입력하고, 각 텍스트가 각 모델에서 소비하는 토큰 수를 측정해 수평 비교를 실시했다.

테스트 텍스트:
1. 일상 대화(여행, 포럼 도움 요청, 글쓰기 요청) — 중영문
2. 기술 문서(파이썬 문서, Anthropic 문서) — 중영문
3. 뉴스(NYT 정치 뉴스, NYT 경제 뉴스, 애플 공식 성명서) — 중영문
4. 문학 작품(『출사표』, 『도덕경』) — 중영문 및 고문
테스트 결과, 두 주장 모두 부분적으로 검증되었지만, 실제 상황은 소문보다 훨씬 복잡했다.
중국어 세금(Chinese Tax)
먼저 결론부터 말하자면:
1. 클로드와 GPT에서는 중국어가 항상 영어보다 비쌌다.
2. Qwen과 DeepSeek에서는 중국어가 오히려 영어보다 저렴했다.
3. Opus 4.7에서 발생한 토크나이저 업그레이드는 인플레이션을 거의 전부 영어에서만 발생시켰고, 중국어는 거의 변동이 없었다.
구체적인 수치를 살펴보자. 클로드 Opus 4.7 이전의 전체 모델군(즉 Opus 4.6, Sonnet, Haiku)은 동일한 토크나이저를 사용한다. 이 토크나이저 하에서는 중국어의 토큰 소비량이 동일한 양의 영어 콘텐츠보다 전반적으로 높았으며, 중국어 대비 영어(cn/en) 토큰 비율은 1.11×에서 1.64× 사이였다.
가장 극단적인 사례는 NYT 스타일의 경제 뉴스에서 나타났다. 동일한 내용의 중국어 버전은 영어 버전보다 토큰을 64% 더 소비해, 곧 64% 더 많은 비용을 부담해야 했다.
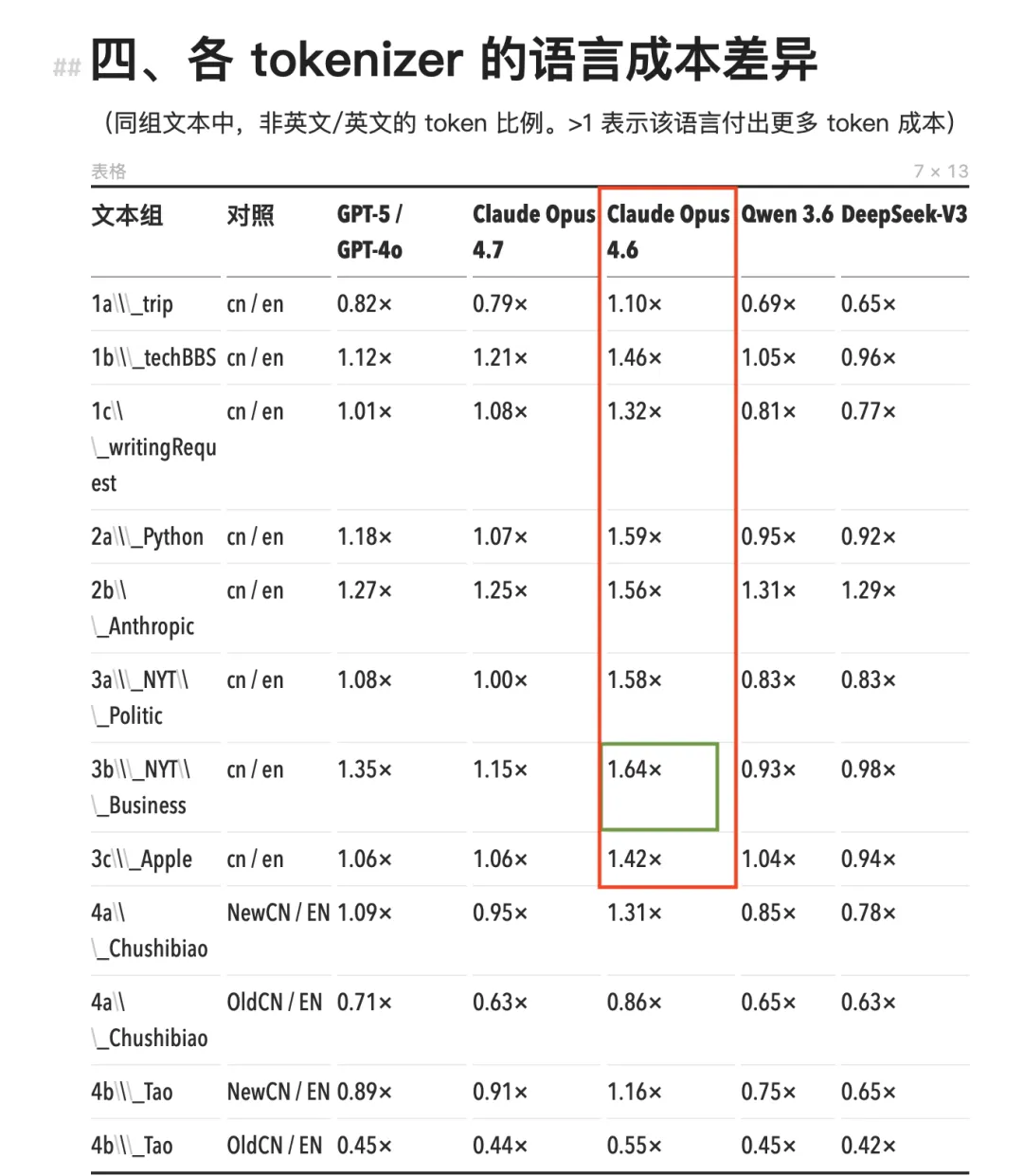
Opus 4.6 및 이전 클로드 모델에서 중국어 토큰 소비량은 타 모델 대비 현저히 높았다(적색 박스)
가장 극단적인 사례는 NYT 스타일의 경제 뉴스에서 나타났다: 동일한 내용의 중국어 버전은 영어 버전보다 토큰을 64% 더 소비한다(녹색 박스)
GPT-4o의 o200k 토크나이저는 다소 나은 편이다. cn/en 비율은 대부분 1.0×~1.35× 범위에 머무르며, 일부 시나리오에서는 1 미만이기도 하다. 중국어는 여전히 전반적으로 다소 비싸지만, 클로드 대비 격차는 훨씬 작다.
국산 모델인 Qwen 3.6과 DeepSeek-V3의 데이터는 정반대다. 두 모델 모두 cn/en 비율이 넓은 범위에서 1 미만을 기록했는데, 이는 동일한 콘텐츠에 대해 중국어 버전이 영어 버전보다 오히려 토큰을 덜 소비한다는 의미다. DeepSeek은 최저 0.65×까지 기록하여, 동일한 문장의 중국어 버전이 영어 버전보다 3분의 1 저렴하다.
Opus 4.7의 새 토크나이저 인플레이션은 거의 전부 영어에서만 발생했다. 영어 토큰 수는 1.24×~1.63×까지 팽창했으나, 중국어는 대부분 1.000×를 유지하며 거의 변화가 없었다. 앞서 언급된 영어권 개발자들의 요금 폭탄은 중국어 사용자들에게는 실제로 느껴지지 않았다. 이유는 중국어가 기존 토크나이저에서 이미 단일 문자 단위로 분할되어 있어, 추가로 쪼갤 여지가 극히 적었기 때문일 가능성이 크다.
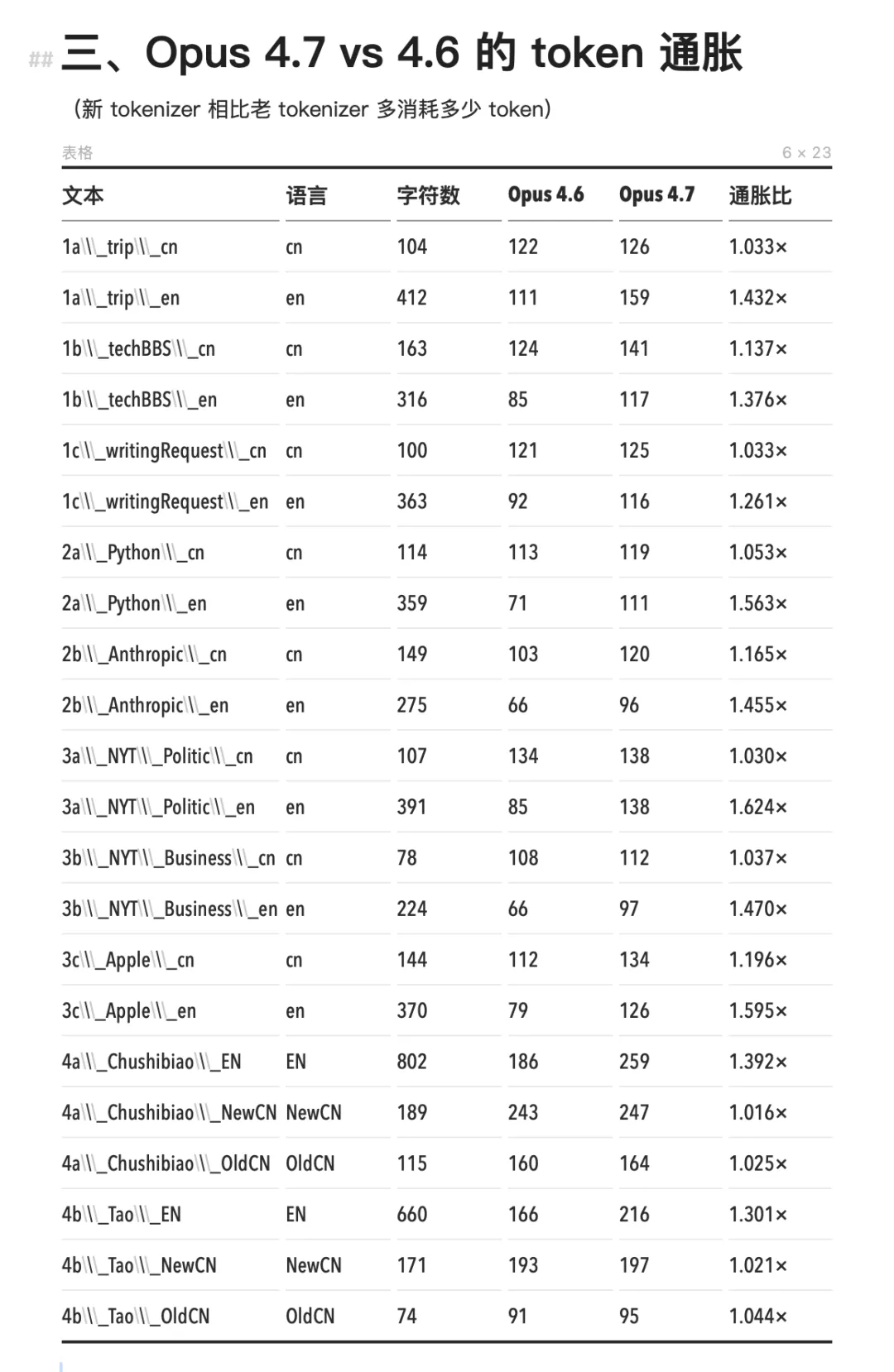
Opus 4.7 대비 4.6에서, 영어는 더 많은 토큰을 소비하게 되었고, 중국어는 변하지 않았다
테스트 과정에서 나는 또 하나의 사실에 주목했다. 토큰 소비량의 차이는 단순히 요금 문제에 그치지 않고, 작업 공간의 크기 자체에 직접적인 영향을 준다. 예를 들어, 동일한 200k 토큰 컨텍스트 윈도우를 사용할 때, 구버전 클로드 토크나이저로 중국어 자료를 입력하면, 영어 자료보다 40%~70% 적은 양의 콘텐츠만 담을 수 있다.
같은 종류의 작업, 예컨대 AI에게 긴 문서를 분석하거나 회의록을 요약하도록 요청할 경우, 중국어 사용자는 모델에 제공할 수 있는 자료량이 적고, 모델이 참조할 수 있는 컨텍스트도 짧아진다. 결국 더 많은 비용을 지불하면서도, 더 작은 작업 공간을 얻게 된다.
네 가지 데이터를 함께 보면, 자연스럽게 다음과 같은 질문이 떠오른다:
왜 동일한 내용이라도 언어를 바꾸면 토큰 수가 달라지는가? 왜 클로드와 GPT에서는 중국어가 비싸고, Qwen과 DeepSeek에서는 오히려 저렴한가?
그 해답은 앞서 여러 차례 언급된 개념인 토크나이저(tokenizer)에 숨어 있다.
한 글자는 몇 조각으로 쪼개질 수 있을까?
모델이 어떤 텍스트를 읽기 전에, 토크나이저를 통해 입력을 하나하나의 토큰으로 분할한다. 토크나이저를 AI의 ‘레고 블록 절단기’라고 상상해 보라. 당신이 한 문장을 입력하면, 이 기계는 해당 문장을 표준화된 레고 블록(즉 토큰)으로 잘라낸다. AI 모델은 텍스트 자체를 보지 않고, 오직 블록의 번호만 인식한다. 당신이 사용한 블록 수만큼 요금을 지불한다.
영어의 분할 방식은 직관에 부합한다. 예를 들어 ‘intelligence’는 거의 확실하게 하나의 토큰이고, ‘information’도 마찬가지로 하나의 토큰이다. 즉, 단어 하나가 곧 요금 청구 단위다.

하지만 중국어는 여기서 문제가 생긴다. 동일한 문장 “인공지능이 전 세계 정보 인프라를 재구성하고 있다”를 GPT-4의 cl100k 토크나이저와 Qwen 2.5 토크나이저에 각각 입력하면, 분할 결과가 완전히 다르다.
GPT-4는 거의 모든 한자(중국어 문자)를 개별 토큰으로 분할한다. 반면 Qwen은 ‘인공지능’이라는 네 글자를 하나의 토큰으로 인식한다.
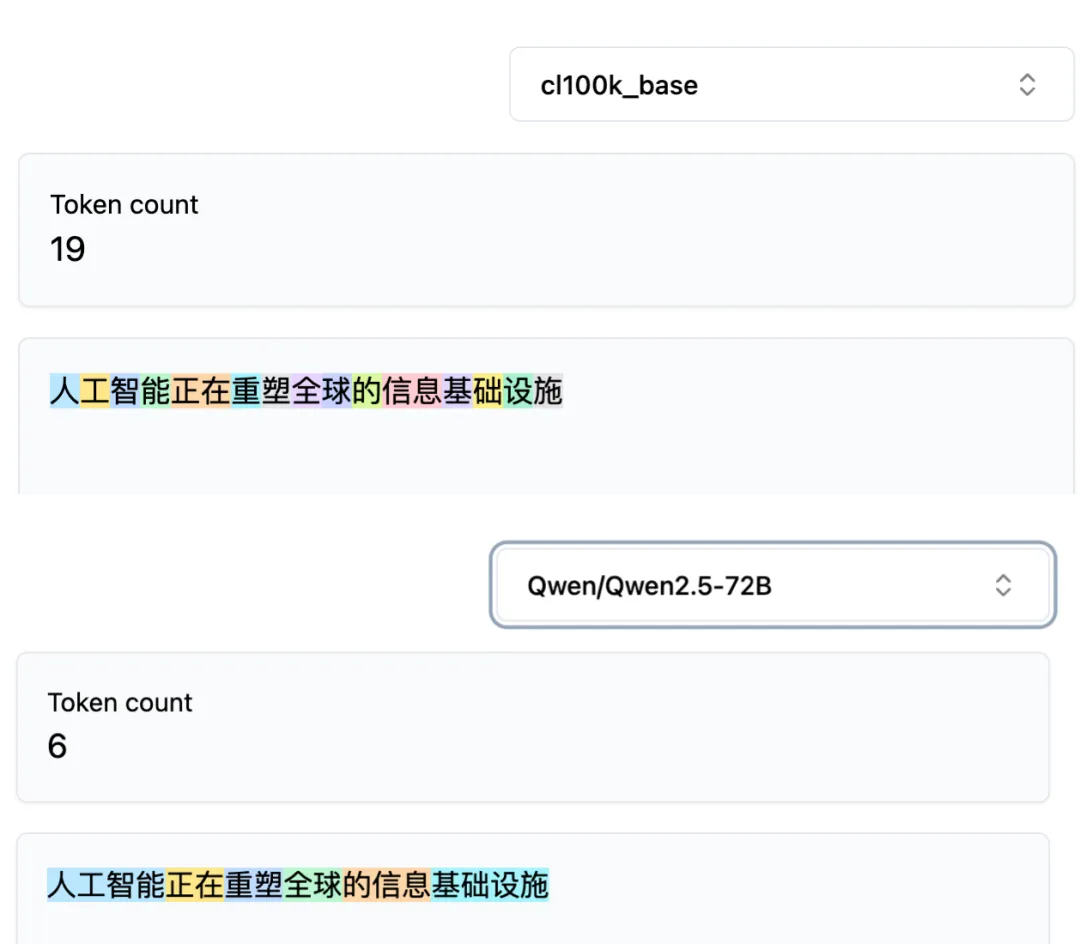
16자로 된 동일한 문장에서, GPT-4는 19개의 토큰을, Qwen은 단 6개의 토큰만 생성한다.
왜 이런 식으로 분할될까? 그 이유는 BPE(Byte Pair Encoding)라는 알고리즘에 있다.
BPE는 훈련 코퍼스(corpus) 내에서 어떤 문자 조합이 가장 빈번하게 등장하는지를 통계적으로 분석한 후, 빈도가 높은 조합을 하나의 토큰으로 병합해 어휘집(vocabulary)에 포함시킨다.
GPT-2 시대에는 훈련 코퍼스의 대부분이 영어였다. 영문자 조합(th, ing, tion 등)은 반복적으로 등장해 빠르게 토큰으로 병합되었다. 반면 중국어 문자는 당시 코퍼스 내 등장 빈도가 너무 낮아 어휘집 순위에 진입하지 못했고, 결국 원시 바이트 단위로 처리되는데, 한 글자가 UTF-8 인코딩 기준 3바이트를 차지하므로, 3개의 토큰으로 분할되었다.

BPE는 훈련 코퍼스 내 문자 조합 빈도에 따라 병합 여부를 결정한다. 영어 중심의 코퍼스 하에서는 중국어 UTF-8 바이트가 한 글자 단위로 병합되지 못한다
이후 GPT-4의 cl100k 어휘집은 확대되었고, 일반적으로 자주 쓰이는 한자는 어휘집에 포함되기 시작해, 한 글자가 보통 1~2개 토큰으로 줄어들었다. 하지만 전체 효율은 여전히 영어보다 낮다.
GPT-4o의 o200k 어휘집에서는 중국어 효율이 다시 한 번 향상되었다. 이것이 첫 번째 데이터에서 GPT-4o의 cn/en 비율이 클로드보다 낮은 이유다.
Qwen과 DeepSeek은 국산 모델로서, 처음부터 대량의 일반 한자와 고빈도 어휘를 한 글자 또는 한 단어 단위로 어휘집에 포함시켰다. 즉, 한 글자가 하나의 토큰으로 처리되어 효율이 두 배 이상 향상된다.

동일한 문장이 서로 다른 토크나이저 하에서 분할된 결과를 보여주는 도식
이것이 바로 그들의 cn/en 비율이 1 미만이 될 수 있는 이유다. 한자의 평균 정보 밀도는 본래 영어 단어보다 높으며, 토크나이저가 한자를 인위적으로 분쇄하지 않을 때 이 천연적인 우위가 발현된다.
따라서 앞선 네 가지 데이터 간 차이의 근본 원인은 모델 능력이 아니라, 토크나이저 어휘집 내에서 중국어에 얼마나 많은 공간을 할당했느냐에 달려 있다.
클로드와 초기 GPT의 어휘집은 영어를 기본값으로 구성되었고, 중국어는 나중에 ‘끼워 넣은’ 형태였다. 반면 Qwen과 DeepSeek의 어휘집은 설계 단계부터 중국어를 기본 언어로 간주하였다. 이 출발점의 차이는 토큰 수, 요금, 컨텍스트 윈도우 크기까지 전방위적으로 전달된다.
고문은 정말 더 저렴할까?
다시 처음의 두 번째 소문으로 돌아가자: 고문이 현대 중국어보다 토큰을 덜 소비한다.
데이터는 이 주장을 확인해주었다. 테스트 결과, 고문 샘플의 cn/en 비율은 전부 1 미만이었으며, 다섯 개 토크나이저 모두에서 일관되게 나타났다. 동일한 내용의 고문 버전은 대응되는 영문 번역본보다 오히려 토큰 수가 적었다.
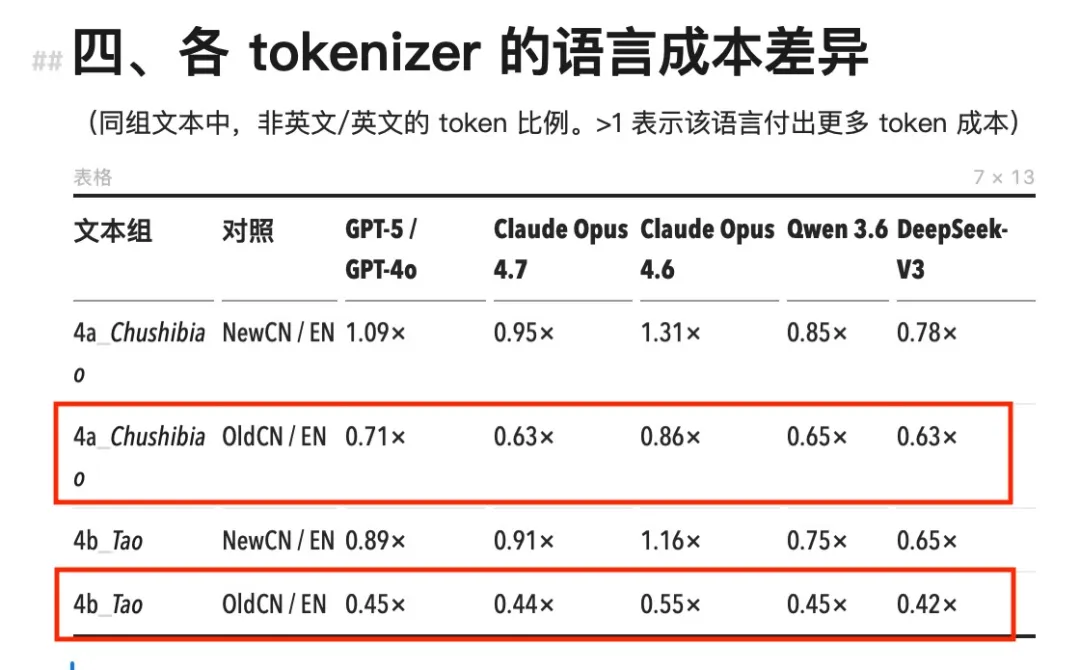
모든 모델에서 고문은 현대 중국어보다도, 심지어 영어보다도 더 적은 토큰을 소비한다
그 이유는 복잡하지 않다. 고문은 극도로 간결한 표현을 사용한다. “학이불사즉망, 사이불학즉태”는 단 12자이다. 이를 현대 중국어로 번역하면 “단지 학습만 하고 생각하지 않으면 혼란스러워지고, 단지 생각만 하고 학습하지 않으면 곤경에 빠진다”로, 글자 수가 두 배로 늘어나고 따라서 토큰 수도 자연스럽게 두 배로 증가한다.
더불어 고문에서 자주 쓰이는 글자(之, 也, 者, 而, 不 등)는 어느 토크나이저 어휘집에서도 독립된 위치를 차지하므로, 바이트 단위로 분할되지 않는다. 따라서 고문은 인코딩 측면에서 실제로 매우 효율적이다.
하지만 여기에 함정이 있다.
고문은 인코딩 단계에서 토큰을 아끼지만, 모델의 추론 부담은 줄지 않는다. ‘망(罔)’이라는 한 글자에 대해, 모델은 해당 문맥에서 그것이 ‘혼란’, ‘속임’, 혹은 ‘없음’ 중 어느 의미인지 판단해야 한다. 현대 중국어는 이 의미를 26자로 명확히 서술할 수 있지만, 고문은 그 정보를 압축해 모델에게 추론을 맡긴다. 비유하자면, ZIP 파일은 용량이 작지만, 압축 해제에는 더 많은 계산 자원이 필요하다.
토큰은 아꼈지만, 추론 비용은 오히려 증가하고, 이해 정확도도 떨어진다. 이 계산은 결코 이득이 아니다.
고문이라는 사례는 나로 하여금 토큰 수 자체가 그리 많은 것을 말해주지 못한다는 사실을 깨닫게 했다. 그러나 이 방향으로 더 생각해보면, 내가 이전에 간과했던 또 다른 층이 있다.
앞서 언급했듯, GPT-2 시대의 토크나이저는 ‘인(人)’이라는 글자를 UTF-8 바이트 3개로 분할했고, 이후 GPT-4의 어휘집 확대로 일반 한자는 한 글자 한 토큰으로 줄어들었으며, Qwen은 더 나아가 ‘인공지능’ 네 글자를 하나의 토큰으로 병합했다.
직관적으로 이것은 계속해서 개선되는 과정이다: 병합할수록 효율이 높아지고, 모델도 더 잘 이해할 것 같기 때문이다.
그러나 정말 그럴까? 우리가 한자를 어떻게 익히는지를 한번 떠올려보자.
한자는 표의문자이며, 현대 한자 중 80% 이상은 형성자(의미를 나타내는 부수)와 성성자(발음을 나타내는 부수)로 구성된 형성자다. ‘수변(氵)’은 물과 관련된 글자들이 많고, ‘목변(木)’은 식물과 관련된 글자들이 많으며, ‘화변(火)’은 열과 관련된 글자들이 많다. 부수는 인간이 한자를 익힐 때 가장 기본적인 의미 단서이며, ‘焱’이라는 글자를 처음 보는 사람도 삼화(三火)를 보고 그것이 ‘불’과 관련 있음을 추론할 수 있다.
부수는 인간이 한자를 익힐 때 가장 기초적인 의미 단서이므로, 사람은 먼저 구조를 통해 의미 범주를 추론한 후, 문맥과 결합해 구체적 의미를 파악한다.

화화, 화염, 광염. 서면어와 인명에서 흔히 쓰이며, ‘빛’과 ‘뜨거움’을 상징한다.
하지만 토크나이저 어휘집에서 ‘焱’이라는 글자는 단순한 번호에 불과하다. 예를 들어 그것이 38721번이라고 가정해 보자. 이 번호는 어휘집 내 하나의 인덱스 위치를 가리키며, 모델은 이를 통해 일련의 숫자 벡터를 찾아 ‘焱’이라는 글자를 표현한다.
번호 자체는 이 글자의 내부 구조에 대한 어떠한 정보도 담고 있지 않다. 38721과 38722의 관계는, 모델 입장에서 1과 10000의 관계와 다를 바 없다. 따라서 ‘한자의 구조’라는 정보층은 완전히 캡슐화되고 만다. 삼화(三火)가 겹쳐 있다는 사실은 번호 내에는 존재하지 않는다.
물론 모델은 방대한 훈련 데이터를 통해 ‘焱’, ‘염(炎)’, ‘작(灼)’이 유사한 문맥에 자주 등장한다는 것을 간접적으로 배울 수는 있지만, 이 방법은 부수 정보를 직접 활용하는 것보다 훨씬 간접적이다.
그렇다면 모델은 분할된 바이트들 속에서 부수와 유사한 구조적 단서를 ‘보게’ 되어, 이후 계산 단계에서 이를 다시 조합할 수 있을까? 이 길은 토큰 수는 많고 비용은 높지만, 어쩌면 의미 이해 측면에서는 불투명한 번호 하나를 바로 집어넣는 것보다 오히려 더 효과적일지도 모른다?
2025년 MIT Press의 『Computational Linguistics』에 게재된 논문(『Tokenization Changes Meaning in Large Language Models: Evidence from Chinese』)이 바로 이 질문에 답했다.
조각 속에서 부수가 자라난다
논문 저자인 데이비드 해슬렛(David Haslett)은 역사적 우연을 하나 발견했다.
1990년대 유니코드 연맹(Unicode Consortium)이 한자에 UTF-8 인코딩을 부여할 때, 그 배열 순서는 부수를 기준으로 분류해 배치했다. 동일한 부수를 가진 한자는 UTF-8 인코딩이 인접해 있었다. ‘차(茶)’와 ‘경(莖)’은 모두 ‘초두(艹)’를 포함하며, 그 UTF-8 바이트 시퀀스는 동일한 바이트로 시작한다. ‘하(河)’와 ‘해(海)’는 모두 ‘수변(氵)’을 포함하므로, 바이트 시퀀스 역시 동일한 바이트로 시작한다.
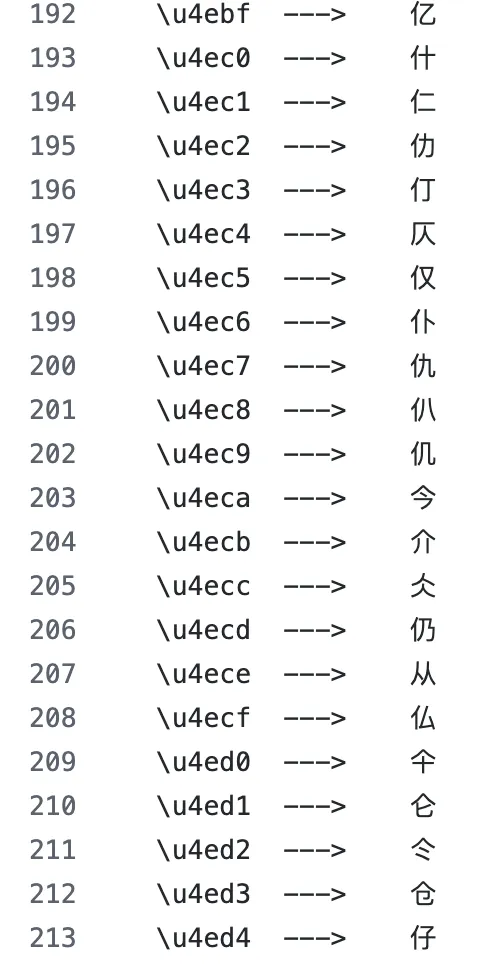
UTF-8은 일부 부수 순서에 따라 한자를 정렬하며, 동일한 부수를 가진 글자들은 인코딩이 인접하다|출처: Github
이는 토크나이저가 한자를 세 개의 UTF-8 바이트 토큰으로 분할할 때, 동일한 부수를 가진 한자는 첫 번째 토큰을 공유한다는 것을 의미한다. 모델은 훈련 과정에서 이러한 공유된 바이트 패턴을 반복적으로 접하며, ‘첫 번째 토큰이 같은 글자들은 종종 동일한 의미 범주에 속한다’는 규칙을 학습할 수 있다. 이는 기능적으로 인간이 부수를 통해 의미를 판단하는 과정과 유사하다.
해슬렛은 이를 검증하기 위해 세 가지 실험을 설계했다.
첫 번째 실험은 GPT-4, GPT-4o, Llama 3에게 “차(茶)와 경(莖)은 동일한 의미 부수를 가지고 있는가?”라고 물었다.
두 번째 실험은 두 한자의 의미 유사도를 평가하도록 했다.
세 번째 실험은 ‘다른 하나를 고르기’라는 배제 과제를 수행하도록 했다.
각 실험은 두 변수를 통제했다: 두 한자가 실제로 동일한 부수를 공유하는지, 그리고 두 한자가 토크나이저 하에서 첫 번째 토큰을 공유하는지. 이 2×2 설계를 통해 부수 효과와 토큰 효과 각각의 영향을 분리해낼 수 있었다.
세 실험의 결론은 일치했다: 한자가 여러 토큰으로 분할될 때(GPT-4의 구 토크나이저 하에서는 89%의 한자가 다중 토큰으로 분할됨), 모델이 공유 부수를 인식하는 정확도가 더 높았다. 반면 한자가 단일 토큰으로 인코딩될 때(GPT-4o의 신 토크나이저 하에서는 57%만 다중 토큰), 정확도가 하락했다.
즉, 앞선 가설은 성립했다. 한자를 조각내는 것은 비용 면에서 확실히 비효율적이지만, 조각난 바이트 시퀀스 속에는 부수의 흔적이 남아 있고, 모델은 실제로 그로부터 무언가를 배우고 있었다. 반대로 한자를 전체 토큰으로 인코딩하면 비용은 낮아지지만, 부수 정보는 불투명한 번호 하나에 캡슐화되어, 모델은 바이트 시퀀스를 통해 더 이상 이 단서를 얻을 수 없게 된다.
단, 이 결론은 문자 형태와 관련된 세부 의미 작업에 한정되며, 모델 전반의 중국어 이해력, 논리 추론력, 장문 생성 능력의 하락과 동일시해서는 안 된다. 또한, 실험에서 비교된 GPT-4와 GPT-4o는 토크나이저 차이 외에도 모델 아키텍처, 훈련 코퍼스, 파라미터 수 등에서 상당한 차이가 있으므로, 정확도 변화를 100% 분할 입자도(tone granularity) 조정에 기인한다고 단정할 수 없다.
이 발견은 공학적 측면에서도 검증되었다. 2024년 GPT-4o를 대상으로 한 연구에서, GPT-4o의 신 토크나이저가 특정 중국어 문자 조합을 하나의 긴 토큰으로 병합한 후, 모델이 오히려 오해를 일으키는 사례가 관찰되었다. 연구진이 전문 중국어 분할기로 이 긴 토큰들을 다시 분해해 모델에 입력했을 때, 이해 정확도가 회복되었다.
현재 글로벌 대규모 언어 모델(Large Language Model) 업계의 주류 합의는, 목표 언어에 특화된 전체 단어/전체 글자 토크나이저가 모델 전반의 성능을 크게 향상시킨다는 것이다. 전체 단어/전체 글자 인코딩은 토큰 비용을 대폭 감소시키고, 컨텍스트 윈도우 내 유효 정보량을 높이며, 시퀀스 길이를 단축하고, 추론 지연을 줄이며, 장문 처리의 안정성을 향상시킨다. 논문에서 발견된 세부 작업상의 우위는, 대부분의 중국어 NLP 시나리오에서 얻는 성능 이득을 상쇄하지 못한다.
그럼에도 불구하고 이 발견은 거대 시스템에서 가장 다루기 어려운 문제 중 하나를 정확히 찌른다: 당신은 설계한 부분은 최적화할 수 있지만, 자신이 갖고 있음을 알지 못하는 부분은 최적화할 수 없다. 유니코드 연맹이 부수 순서로 인코딩을 정렬한 것은 인간의 검색 편의를 위한 것이었고, BPE가 한자를 바이트 단위로 분할한 것은 한자가 코퍼스 내에서 등장 빈도가 너무 낮았기 때문이었다. 서로 관련 없는 두 공학적 결정이 우연히 겹쳐, 아무도 계획하지 않은 의미 전달 채널을 만들어냈다.
그런 다음, 차세대 엔지니어들이 토크나이저를 ‘개선’해 한자를 전체 글자 토큰으로 병합할 때, 그들은 자신이 존재조차 모르던 그 길을 동시에 지워버린다. 효율은 향상되고, 비용은 낮아지지만, 어떤 것들은 조용히 사라진다. 그리고 당신은 심지어 오류 메시지조차 받지 못한다.
따라서 이 문제는 단순히 ‘AI에서 중국어 사용자가 더 많은 비용을 부담한다’는 판단보다 훨씬 복잡하다. 모든 토크나이저는 어떤 기본값을 위해 최적화되며, 그 대가가 다른 곳에 숨어 있다.
린위탕(Lin Yutang)
중국어가 서양 기술 인프라에 적응하는 데 치르는 대가는 AI 시대에 시작된 것이 아니다.
2025년 1월, 뉴욕 거주자 넬슨 펠릭스(Nelson Felix)가 페이스북의 타자기 애호가 그룹에 몇 장의 사진을 올렸다. 그는 아내의 조부 유물 속에서 한자로 가득 찬 타자기를 발견했으나, 그 정체를 알지 못했다. 곧 수백 개의 댓글이 쏟아졌다.

넬슨 펠릭스의 질문: ‘명쾌 타자기(Ming Kwai Typewriter)는 가치가 있나요?’|출처: Facebook
스탠퍼드대학 한학자 토머스 S. 머래니(Thomas S. Mullaney)는 사진을 보자마자 그것을 알아보았다. 그것은 린위탕이 1947년에 발명한 ‘명쾌 타자기’의 유일한 프로토타입으로, 약 80년간 행방이 묘연했던 것이다. 같은 해 4월, 펠릭스 부부는 이 타자기를 스탠퍼드 대학 도서관에 판매했다.
명쾌 타자기가 해결하고자 했던 문제는 오늘날 토크나이저가 직면한 문제와 구조적으로 동일하다: 서양 언어를 위해 설계된 기술 인프라에 중국어를 어떻게 효율적으로 통합할 것인가?
1940년대 영문 타자기는 26개의 알파벳 키를 갖추고 있었고, 키 하나당 글자 하나로 간단하고 직접적이었다. 반면 중국어는 수천 개의 일반 한자를 갖고 있어, 키 하나당 한 글자 방식은 불가능했다. 당시 중국어 타자기는 거대한 자판(글자판)으로 구성되어 있었고, 수천 개의 활자들이 배열되어 있었으며, 타자원은 손으로 하나씩 활자를 골라야 했고, 분당 10여 자밖에 칠 수 없었다.

1899년 미국 선교사 쉐빌로 디벨로 Z. 셰필드(Devello Z. Sheffield)가 발명한 중국어 타자기는 최초의 중국어 타자기 기록이다|출처: Wikipedia
린위탕은 12만 달러의 연구개발비를 투입해 거의 파산 직전까지 몰렸고, 뉴욕의 칼 E. 크럼(Carl E. Krum) 사에 72개 키만 갖춘 중국어 타자기를 의뢰했다. 그 작동 원리는 한자를 자형 구조에 따라 분해해 상형 키로 글자 위쪽 부수를 선택하고, 하형 키로 아래쪽 부수를 선택한 후, ‘마법의 눈(magic eye)’이라는 작은 창에 후보 글자를 표시하고, 숫자 키로 선택하는 방식이었다. 분당 40~50자, 8,000여 개의 일반 문자를 지원했다.

(좌) 투명 유리 창이 바로 ‘마법의 눈’; (우) 명쾌 타자기 내부 구조|출처: Facebook
조원임(Chao Yuanren)은 이렇게 평가했다: “중국인이든 미국인이든, 조금만 배우면 이 키보드를 익힐 수 있다. 나는 이것이 우리가 필요로 하는 타자기라고 생각한다.”
기술적으로 명쾌 타자기는 혁신이었지만, 상업적으로는 실패했다.
린위탕이 레밍턴(Remington)사 임원들에게 시연할 때 기계가 고장나자 투자자들의 관심이 사라졌고, 고가의 제작비와 개인 자금 고갈로 양산은 사실상 불가능해졌다. 1948년, 린위탕은 프로토타입과 상업 권리를 머건탈러 주조기계회사(Mergenthaler Linotype)에 매각했다. 이 회사는 결국 양산을 포기했고, 프로토타입은 1950년대 회사 이전 당시 한 직원이 롱아일랜드 자택으로 가져가 사라졌다가, 2025년에 다시 세상에 모습을 드러냈다.
머래니는 『중국어 타자기(The Chinese Typewriter)』라는 책에서 하나의 판단을 내린다. 그는 명쾌 타자기가 ‘실패하지 않았다’고 본다. 1940년대 제품으로서는 분명 실패했지만, 인간-기계 상호작용 패러다임으로서는 승리했다는 것이다.
린위탕은 중국어 ‘타자’를 처음으로 ‘검색 + 선택’ 방식으로 바꿨다. 세 줄의 키 조합으로 글자 부수를 정위하고, 후보 글자 중에서 선택하는 방식. 이는 오늘날 모든 현대 중국어 입력법의 근본 논리다. 창jie(창걸), 오비(오피), 소고우(소구) 음성 입력법에 이르기까지, 모두 명쾌 타자기의 후예라 할 수 있다.

『중국어 타자기』, 저자: 머래니|출처: Douban
이 80년을 넘긴 타자기와 오늘날 우리가 끊임없이 논의하는 토크나이저는, 어딘가에 역사적 규칙을 은밀히 품고 있다. 중국어는 언제나 하나의 문제에 직면해 있다:
로마자 기반의 인프라에 어떻게 접속할 것인가?
흥미로운 점은, 이 탐색 과정에서 비인위적 우연이 가득하다는 것이다. 유니코드 연맹이 인간 검색 편의를 위해 정한 정렬 방식과, BPE 알고리즘이 무심코 수행한 분할이 겹쳐, 신경망의 블랙박스 속에서 인간의 한자 인식 과정이 재현된 것이다. 그리고 엔지니어들이 ‘중국어 세금’을 없애기 위해 의도적으로 한자를 다시 맞춰 붙이고 비용을 낮출 때, 우연히 탄생한 그 의미 전달 채널도 함께 닫혀버린다.
역사는 일직선의 진화 궤도가 아니라, 다양한 제약 조건의 압박 속에서 끊임없이 변형되는 유체다.
어떤 능력은 설계된 것이고, 어떤 능력은 단지 우연히 삭제되지 않았을 뿐이다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News













