

黄仁勲 COMPUTEX 2024 キーノート講演全文実録:我々は現在、コンピューティングのインフレーション期を迎えている
TechFlow厳選深潮セレクト
黄仁勲 COMPUTEX 2024 キーノート講演全文実録:我々は現在、コンピューティングのインフレーション期を迎えている
台北で開催された「COMPUTEX 2024」において、NVIDIA CEOのジェンスン・フアンは、同社の加速コンピューティングおよびジェネレーティブAI分野における最新の成果を発表した。
編集:有新

6月2日夜、台北で開催されたComputeX 2024において、NVIDIA CEOのジェンスン・フアンは、同社が加速コンピューティングおよび生成AI分野で達成した最新の成果を披露し、今後のコンピューティングとロボティクス技術の発展ビジョンを示しました。

この講演では、AI基盤技術から将来のロボット、各業界における生成AIの応用に至るまで幅広く紹介され、NVIDIAがコンピューティング技術の変革を推進する上で成し遂げた卓越した成果が全面的に展示されました。

フアン氏は、「NVIDIAはコンピュータグラフィックス、シミュレーション、AIが交差する地点に位置しており、ここが当社の魂です。今日ご覧いただいたすべてのものはシミュレーションによって作られています。それは数学、科学、コンピュータサイエンス、そして驚異的なコンピュータアーキテクチャが融合したものです。これらはアニメーションではなく、自社で一貫して制作されたものであり、すべてOmniverse仮想世界に統合されています」と述べました。
加速コンピューティングとAI
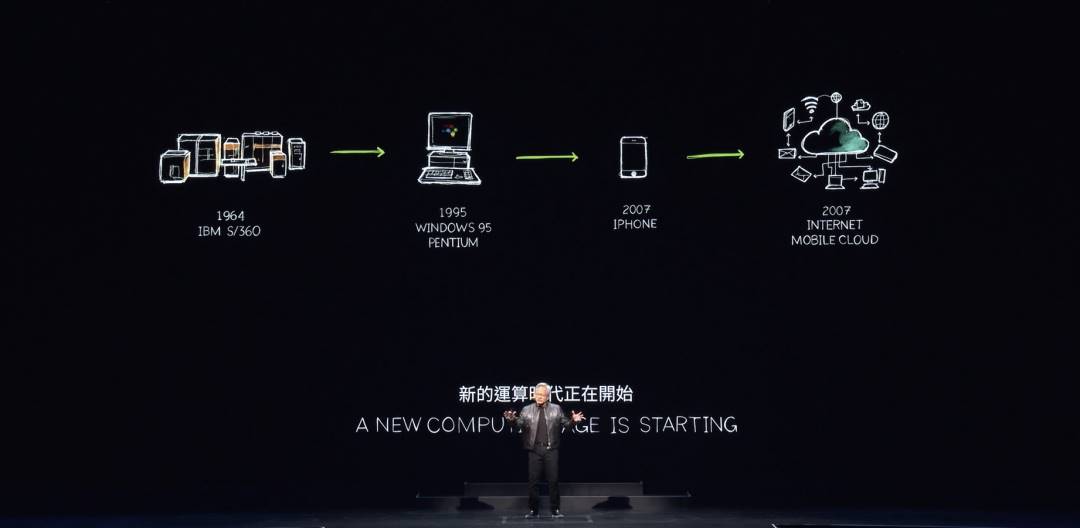
フアン氏は、「私たちが目にするすべての基盤となるのは、加速コンピューティングとOmniverse内で動作するAIという二つの基本技術です。これらの計算の原動力がコンピュータ業界を再構築します。コンピュータ業界の歴史は60年ありますが、その多くは1964年、つまり私が生まれた翌年にすでに発明されていたのです」と語りました。
IBM System 360は、中央処理装置(CPU)、汎用コンピューティング、オペレーティングシステムによるハードウェアとソフトウェアの分離、マルチタスク処理、I/Oサブシステム、DMA、および今日使用されているさまざまな技術を導入しました。アーキテクチャ互換性、後方互換性、シリーズ互換性など、現代のコンピュータに関する知識のほとんどは、1964年にすでに説明されていました。もちろん、PC革命によりコンピューティングは民主化され、個人の手元や家庭に届けられました。
2007年、iPhoneがモバイルコンピューティングをもたらし、コンピュータをポケットに入れる時代が始まりました。それ以来、あらゆるものが接続され、モバイルクラウドを通じて常に稼働しています。この60年間で、実際に起こった主要な技術的変革、すなわちコンピューティングの構造的転換は数回しかありませんでした。しかし、今まさに、またそのような変革が起きようとしています。

現在、二つの根本的な変化が起きています。第一に、コンピュータ業界のエンジンであるプロセッサ、すなわちCPUの性能向上が著しく鈍化しています。一方で、必要な計算量は指数関数的に急速に増加し続けています。もし処理需要、つまりデータ処理量が指数関数的に増加し続ける一方で性能が伸びなければ、計算インフレが発生します。実際、すでにその兆候が見られます。世界中のデータセンターが消費する電力量は大幅に増加しており、計算コストも上昇しています。我々はまさに計算インフレの真っ只中にいるのです。
当然ながら、このような状況は長く続きません。データ量は引き続き指数関数的に増加し続けますが、CPUの性能向上はかつてのようには回復しません。そこで、より優れた方法があります。ここ約20年間、NVIDIAは加速コンピューティングの研究を続けてきました。CUDAはCPUを補助し、特定の処理を専用プロセッサにオフロードして高速化します。実際、その性能は非常に優れており、CPUの性能向上が遅れ、最終的には大きく停滞する中で、すべてを加速すべきであることが明らかになっています。

フアン氏は、「大量の処理を必要とするすべてのアプリケーションはいずれ加速されるでしょう。もちろん、近い将来にはすべてのデータセンターが加速されることになります。現在、加速コンピューティングは非常に理にかなっています。あるアプリケーションを見てみましょう。ここで『100t』は100単位の時間、たとえば100秒または100時間を表します。実際、現在100日間かけて実行しているAIアプリケーションの研究が行われていることもご存知でしょう。
『1Tコード』とは逐次処理が必要なコードのことで、シングルスレッドCPUが極めて重要になる部分です。OSの制御ロジックは非常に重要で、命令を一つずつ順番に実行する必要があります。しかし、コンピュータグラフィックス処理のように完全に並列処理可能なアルゴリズムも多く存在します。コンピュータグラフィックス、画像処理、物理シミュレーション、組合せ最適化、グラフ処理、データベース処理、そしてディープラーニングで有名な線形代数など、これらのアルゴリズムは並列処理によって非常に効果的に高速化できます。
そのため、CPUにGPUを追加するアーキテクチャが発明されました。専用プロセッサにより、非常に時間がかかるタスクを極めて高速に処理できます。両プロセッサが協調して動作し、それぞれ自律的かつ独立して動作することで、元々100単位の時間を要するタスクをわずか1単位の時間に短縮でき、速度は信じられないほど向上します。性能は100倍に向上する一方で、消費電力は約3倍、コストは約1.5倍にしかなりません。これはPC業界でもずっと行われてきたことで、1000ドルのPCに500ドルのGeForce GPUを追加すれば、性能が飛躍的に向上します。データセンターでも同様で、10億ドルのデータセンターに5億ドル相当のGPUを追加すると、突然それがAI工場に変貌します。このような現象が世界中で実際に起きています。
節約できるコストは非常に驚異的です。1ドルあたり60倍のパフォーマンス向上が得られ、速度は100倍に向上する一方、消費電力は3倍、コストは1.5倍に抑えられます。この節約効果は信じがたいほど大きく、金額で換算することも可能です。
多くの企業がクラウド上のデータ処理に数億ドルを費やしていることは明らかです。こうしたプロセスが加速されれば、数億ドルの節約が可能になることは想像に難くありません。これは、汎用コンピューティングの分野で長期間にわたってインフレが続いてきたためです。

ついに加速コンピューティングの時代が到来し、長年損失として蓄積されてきた膨大な無駄を回収できるようになりました。システムから解放される浪費も多数あります。これにより、費用とエネルギーの両面での大幅な節約が実現します。だからこそ、フアン氏は「買うほど、節約できる」とよく言うのです。
フアン氏はまた、「加速コンピューティングは確かに非凡な成果をもたらしますが、簡単ではありません。なぜこれほどコスト削減が可能なのに、長い間誰もこれをしなかったのでしょうか?理由は、それが非常に難しいからです。Cコンパイラに通すだけで、突然アプリケーションが100倍速くなるようなソフトウェアは存在しません。そんなことが可能なら、とっくにCPU自体が改造されています。
実際には、ソフトウェアを完全に書き直す必要があります。これが最も困難な部分です。CPU上で書かれたアルゴリズムを、加速可能で並列実行できるように再表現するために、ソフトウェアをまったく新たに作り直さなければならないのです。このようなコンピュータサイエンスの課題は極めて困難です。

フアン氏は、「過去20年間、NVIDIAは世界中の利用を容易にしてきました。特に有名なのが、ニューラルネットワーク処理のためのディープラーニングライブラリcuDNNです。また、流体力学や他の多くの用途に使えるAI物理ライブラリもあります。ニューラルネットワークが物理法則に従うように設計されています。また、Arial Ranという優れたライブラリもあり、これはCUDAで高速化された5G無線通信で、インターネットのようなネットワークを定義・加速することが可能です。この能力により、すべての通信事業者をクラウドコンピューティングプラットフォームと同じタイプのプラットフォームに変えることができます。
cuLITHOは、チップ製造で最も計算負荷が高い部分――マスクの作成――を処理できる計算リソグラフィープラットフォームです。TSMCはcuLITHOを生産に使用しており、多大なエネルギーと資金を節約しています。TSMCの目標は、スタックを加速することで、さらなるアルゴリズムやより微細で狭いトランジスタ向けの計算に備えることです。ParabricksはNVIDIAのゲノム解析ライブラリで、世界最高のスループットを誇ります。cuOptは、組合せ最適化やルート計画の最適化に使う驚異的なライブラリで、非常に複雑な巡回セールスマン問題を解決できます。
科学者たちは、この問題を解決するには量子コンピュータが必要だと広く考えていました。しかしNVIDIAは、加速コンピューティング上で動作するアルゴリズムを開発し、極めて高速に動作させることで、23の世界記録を樹立しました。cuQuantumは量子コンピュータのシミュレーションシステムです。量子コンピュータを設計するにはシミュレータが必要です。量子アルゴリズムを設計するにも量子シミュレータが必要です。量子コンピュータがまだ存在しない中で、どうやってそれらを設計し、アルゴリズムを作り出せるでしょうか?その答えは、今日世界最速のコンピュータ、もちろんNVIDIA CUDAを使用することです。NVIDIAはその上に、量子コンピュータをシミュレートできるシミュレータを持っています。これは世界中の数十万人の研究者が利用しており、主要な量子コンピューティングフレームワークすべてに統合され、科学スーパーコンピューティングセンターで広く使われています。
cuDFは、驚異的なデータ処理ライブラリです。データ処理は現在、クラウド支出の大部分を占めています。これらすべてを加速すべきです。cuDFはSpark、Pandas、新しいPolars、そしてグラフ処理データベースライブラリNetworkXといった、世界中で主流に使われるライブラリを加速しています。これらはほんの一例にすぎず、他にも多くのライブラリがあります。
フアン氏は、「エコシステムが加速コンピューティングを活用できるようにするため、NVIDIAはこれらのライブラリを作らなければなりませんでした。もしNVIDIAがcuDNNを作らなければ、CUDAがあっても、世界中のディープラーニング研究者がそれを簡単に使えるようにはならなかったでしょう。CUDAとTensorFlow、PyTorchで使われるアルゴリズムとのギャップは大きすぎるからです。それはまるで、OpenGLなしでコンピュータグラフィックスを行うこと、あるいはSQLなしでデータ処理を行うようなものです。こうした特定分野向けのライブラリこそがNVIDIAの宝物であり、合計350種類あります。これらのライブラリがあるからこそ、NVIDIAはこれほど多くの市場を開拓できたのです」と述べました。
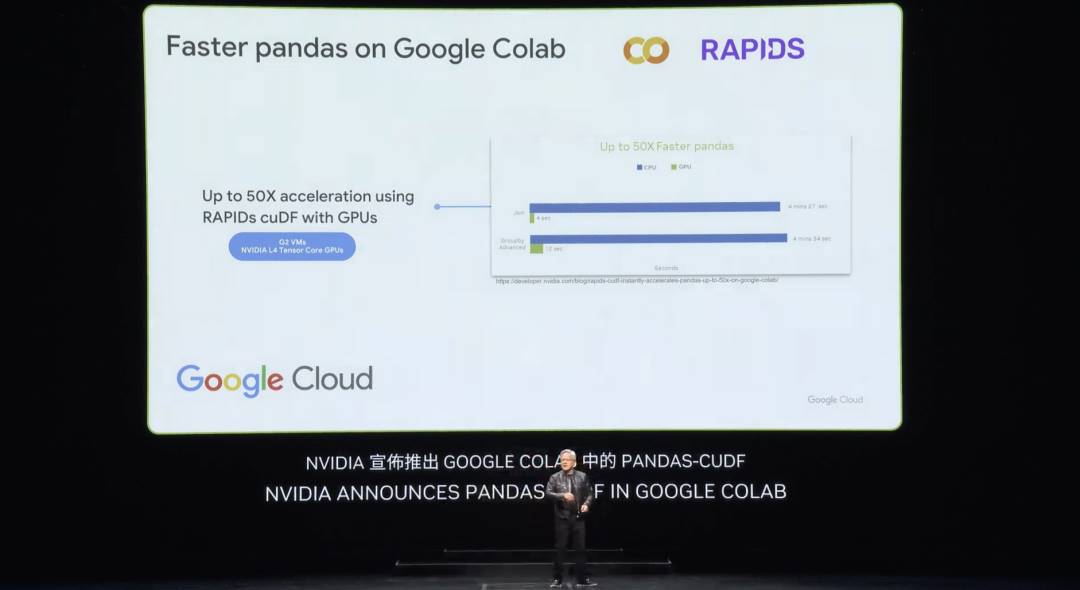
先週、Googleはクラウド上でPandasを加速することを発表しました。Pandasは世界で最も人気のあるデータサイエンスライブラリです。多くの読者が既にPandasを使っているでしょう。全世界の1000万人のデータサイエンティストが使い、毎月1億7千万回ダウンロードされています。データサイエンティストにとっての電子表計算ソフトとも言えます。今や、Google CloudのColabプラットフォームで、cuDFが加速したPandasをワンクリックで利用できるようになりました。その加速効果は本当に驚異的です。
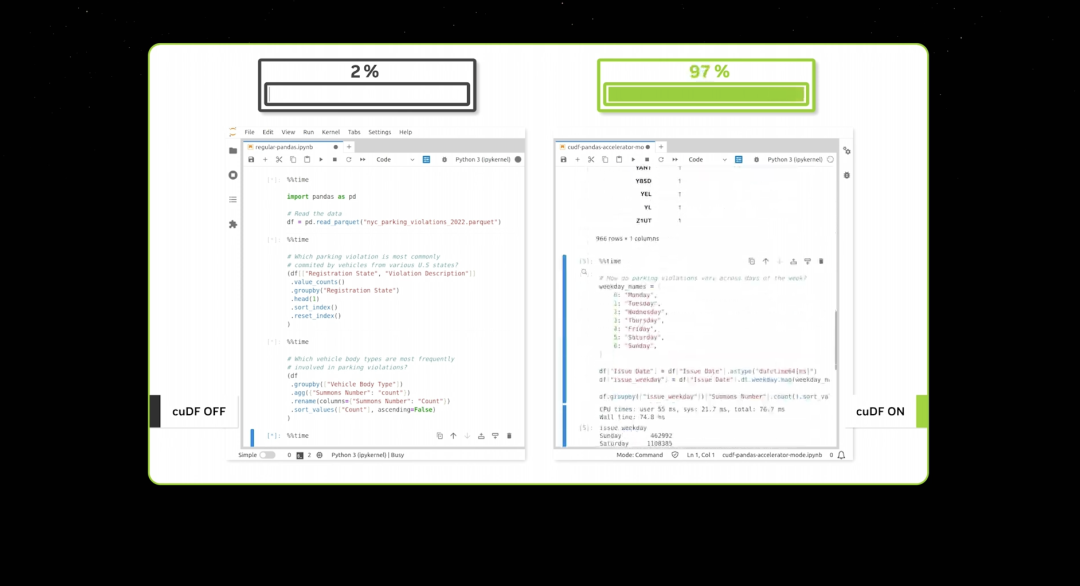
データ処理がこれほど高速になると、デモンストレーションにそれほど時間はかかりません。今やCUDAは人々が言うところの臨界点に達しましたが、それ以上に素晴らしいことに、良性の循環が始まっています。
このような現象は稀です。過去のすべての計算アーキテクチャのプラットフォームを見てみましょう。マイクロプロセッサCPUは60年存在していますが、その基本的なレイヤーでは変化がありません。加速コンピューティングという新しい計算方式はすでに存在していますが、新しいプラットフォームを作るのは極めて困難です。なぜなら、いわゆる「ニワトリが先か、卵が先か」の問題があるからです。
開発者があなたのプラットフォームを使ってくれなければ、ユーザーも現れません。しかしユーザーがいなければ、インストールベースもできません。インストールベースがなければ、開発者は興味を持ちません。開発者は大きなインストールベースを持つプラットフォームにソフトウェアを書きたいと考えますが、大きなインストールベースを作るには多くのアプリケーションが必要で、ユーザーを惹きつける必要があります。
この「ニワトリと卵」の問題が打破されることは滅多にありません。しかしNVIDIAは20年をかけ、分野別のライブラリを一つずつ、加速ライブラリを一つずつ積み重ね、現在世界中に500万人の開発者がNVIDIAのプラットフォームを利用しています。
NVIDIAは医療、金融、IT、自動車などほぼすべての主要産業、ほぼすべての科学分野にサービスを提供しています。NVIDIAのアーキテクチャにはこれほど多くの顧客がいるため、OEMメーカーやクラウドサービスプロバイダーはNVIDIAシステムの構築に興味を持っています。台湾にあるような優れたシステムメーカーも、NVIDIAシステムの構築に関心を持っています。これにより市場に選択肢が増え、規模拡大、研究開発の拡大の機会が増え、さらにアプリケーションの加速につながります。
アプリケーションが加速されるたびに、計算コストは下がります。100倍の加速は97%、96%、98%の節約に相当します。100倍から200倍、さらに1000倍へと加速が進めば、計算の限界コストはさらに低下し続けます。
NVIDIAは、計算コストを大幅に下げることで、市場、開発者、科学者、発明家たちがますます多くのアルゴリズムを発見し、ますます多くの計算資源を消費するようになり、ついには質的な飛躍が起こると信じています。計算の限界コストが非常に低くなり、新しい計算の使い方が登場するのです。
実際、まさに今そうなっています。過去10年間で、NVIDIAはある特定のアルゴリズムの限界計算コストを百万倍も下げてきました。そのため、インターネット全体のデータを含むLLMを訓練することは、今や非常に妥当で常識的なことになっています。誰も疑問を抱かないでしょう。これほど大量のデータを扱えるコンピュータを作り、自分自身のソフトウェアを書けるようにするというアイデアです。AIの出現は、計算がますます安価になれば、いつか誰かが偉大な使い道を見出すだろうという信念の賜物なのです。
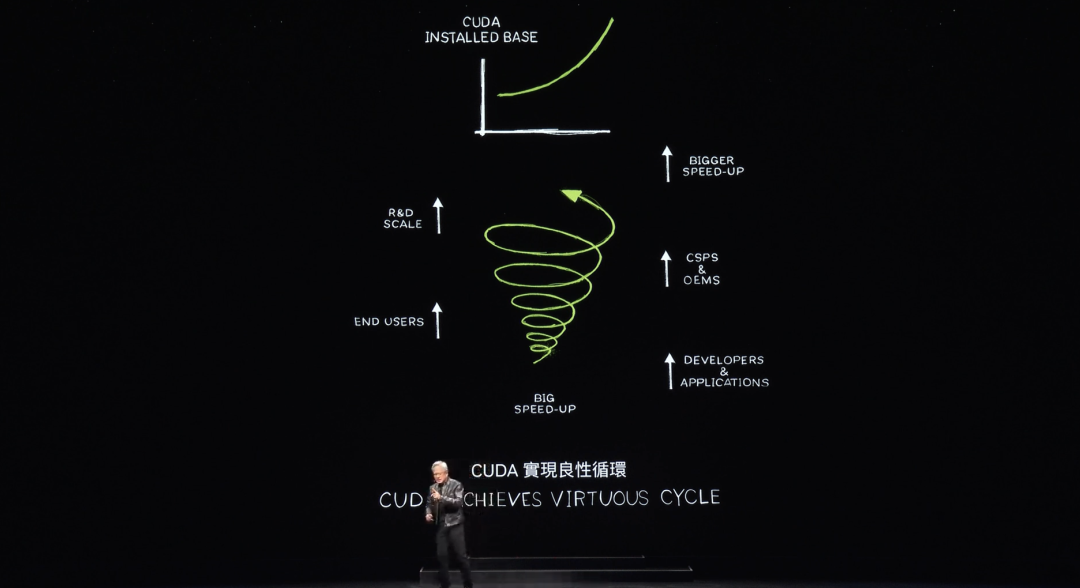
今や、CUDAは良性の循環を確立しました。インストールベースは拡大し、計算コストは低下し、それによりさらに多くの開発者が新しいアイデアを出し、需要をさらに押し上げます。私たちは今、非常に重要な出発点に立っています。
フアン氏はその後、「アース2(Earth-2)」のアイデアについて触れました。地球のデジタルツインを作成し、地球をシミュレーションすることで、将来をより正確に予測し、災害を回避し、気候変動の影響をより深く理解し、適応するための手段を得られるのです。

研究者たちは2012年にCUDAを発見しました。これはNVIDIAとAIが初めて出会った非常に重要な日です。幸運にも、科学者たちと協力し、ディープラーニングを可能にしました。
AlexNetはコンピュータビジョン分野で大きなブレークスルーを達成しました。しかしもっと重要なのは、ディープラーニングの背景、基礎、長期的な影響と可能性を俯瞰して理解することです。NVIDIAは、この技術が巨大な拡張可能性を持つことを認識しました。数十年前に発明・発見されたアルゴリズムが、突然、より多くのデータ、より大きなネットワーク、そして非常に重要な、より多くの計算リソースのおかげで、人類のアルゴリズムでは不可能だった成果を達成したのです。
さらにアーキテクチャを拡張し、より大きなネットワーク、より多くのデータ、より多くの計算リソースがあれば、何が可能になるか想像してみてください。2012年以降、NVIDIAはGPUアーキテクチャを変更し、Tensorコアを追加しました。10年前にNVLinkを発明し、CUDA、TensorRT、NCCL、Mellanoxの買収、TensorRT-ML、Triton推論サーバーなどを経て、これらすべてが一台の全く新しいコンピュータに統合されました。誰もその意味を理解せず、誰も要求しませんでした。
実際、フアン氏は誰もそれを買わないだろうと確信していました。しかしGTCで発表したところ、サンフランシスコにある小さな会社OpenAIが、NVIDIAに1台を提供してくれるように依頼してきたのです。
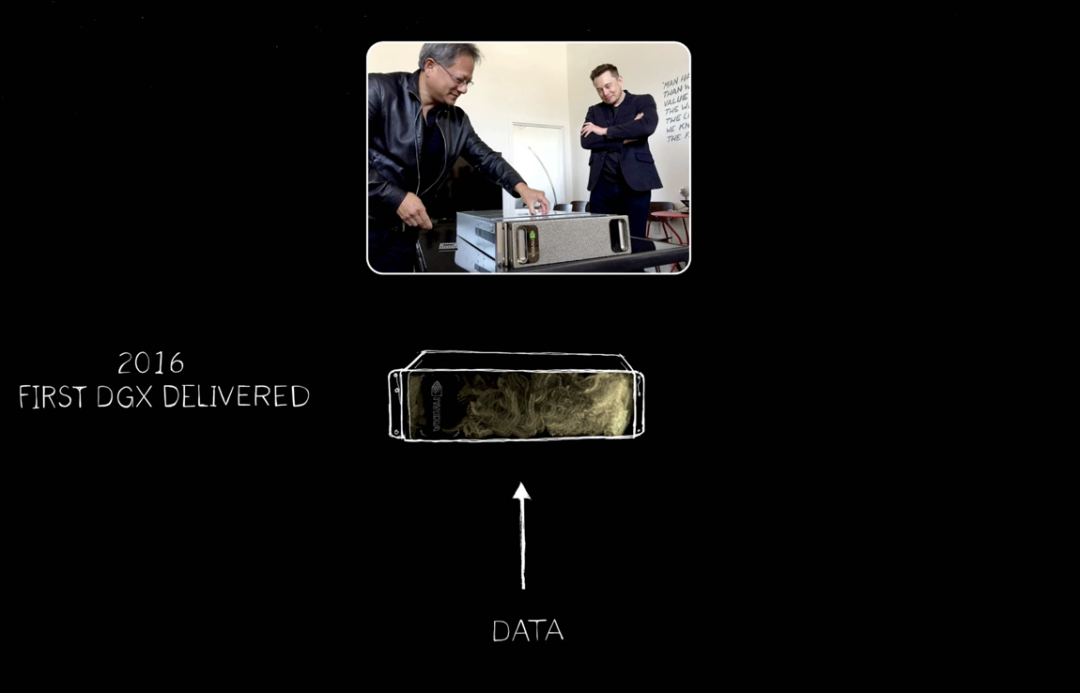
2016年、フアン氏はOpenAIに初のDGXを納品しました。これは世界初のAIスーパーコンピュータです。その後、一台のAIスーパーコンピュータ、一つのAIデバイスから、大型スーパーコンピュータ、さらに大規模なものへと拡張し続けました。
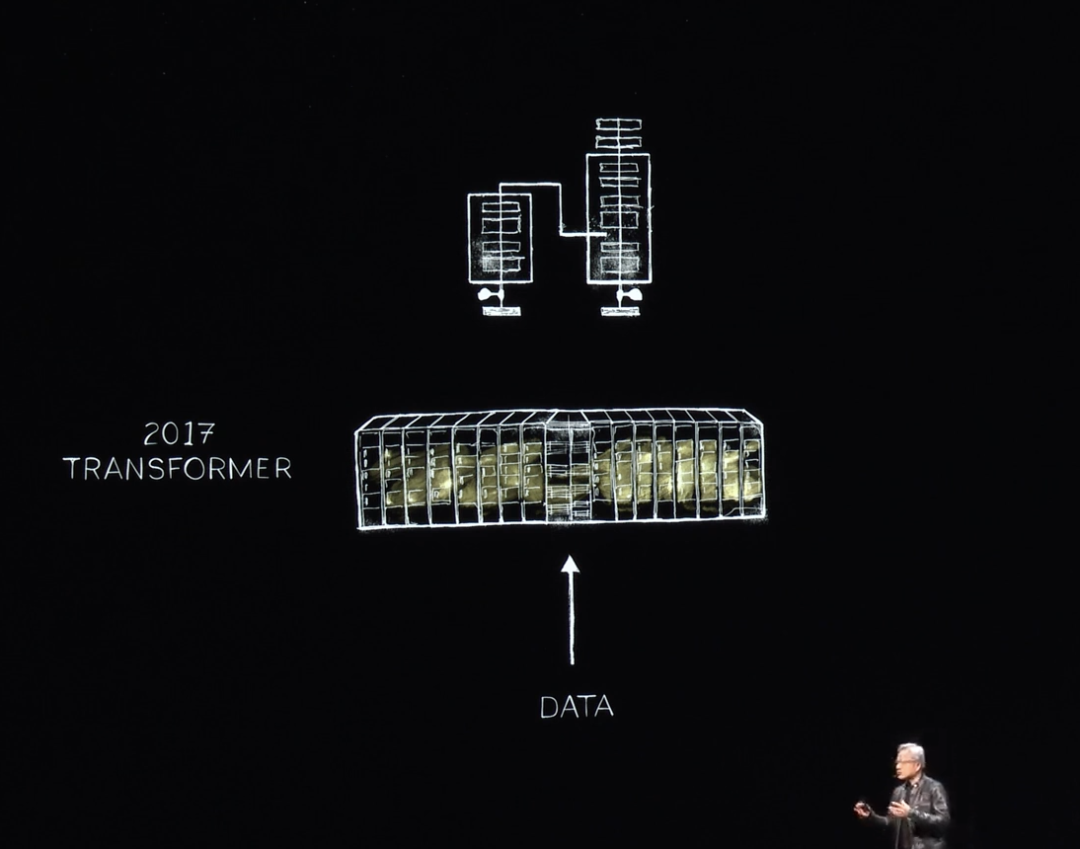
2017年には、世界がTransformerを発見しました。これにより大量のデータを訓練し、長期的な系列パターンを認識・学習できるようになりました。これでNVIDIAはLLMを訓練し、自然言語理解でブレークスルーを達成できるようになりました。さらに前進し、より大規模なシステムを構築しました。
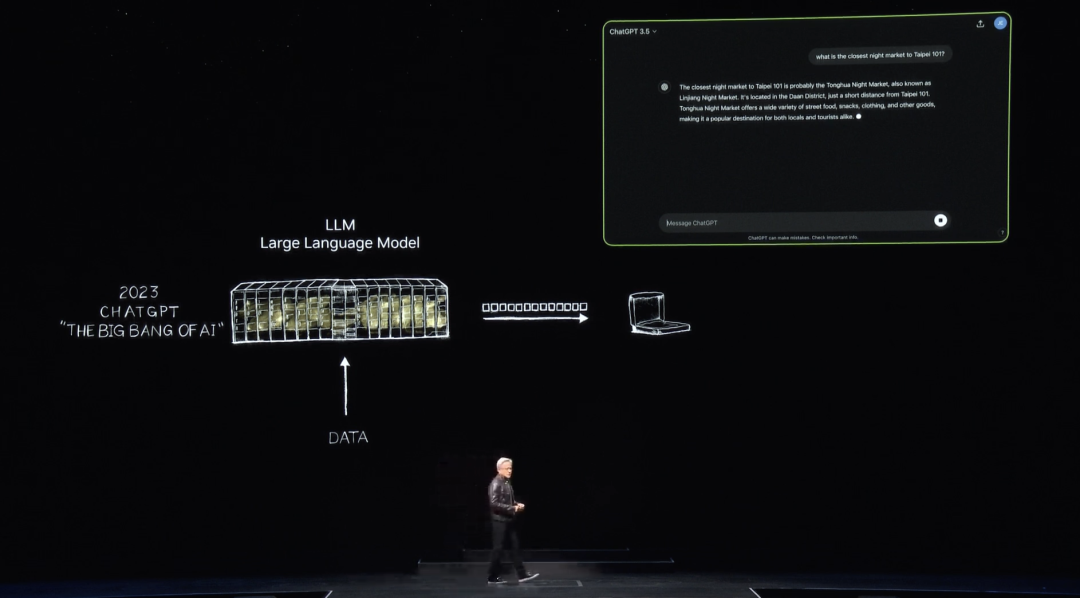
そして2022年11月、数千台のNVIDIA GPUと非常に大規模なAIスーパーコンピュータで訓練されたChatGPTがOpenAIからリリースされました。5日で100万人、2カ月で1億人のユーザーを獲得し、史上最高の成長スピードを記録しました。
ChatGPTが世界に示される前、AIは感知(perception)に関するものでした。自然言語理解、コンピュータビジョン、音声認識など、すべてが感知と検出に関するものでした。しかし今回、世界は初めて生成AIを解決しました。トークンを一つずつ生成していくのです。これらのトークンは単語ですが、今は画像、図表、表、曲、単語、音声、動画にもなります。これらのトークンは、意味を理解できるものであれば何でもありえます。化学物質のトークン、タンパク質のトークン、遺伝子のトークンなども可能です。先ほどアース2プロジェクトで見たように、天気のトークンを生成することもできます。
理解できます。物理を学ぶことができます。物理を学べるなら、AIモデルに物理を教えられます。AIモデルは物理の意味を学び、その後物理を生成できるようになります。1キロメートル規模にまで縮小し、フィルタリングではなく生成します。この方法で、ほぼすべての価値あるものを生成できます。自動車に対してはハンドル操作を生成し、ロボットアームに対しては動作を生成できます。私たちが学べることはすべて、今や生成できるようになります。
AI工場
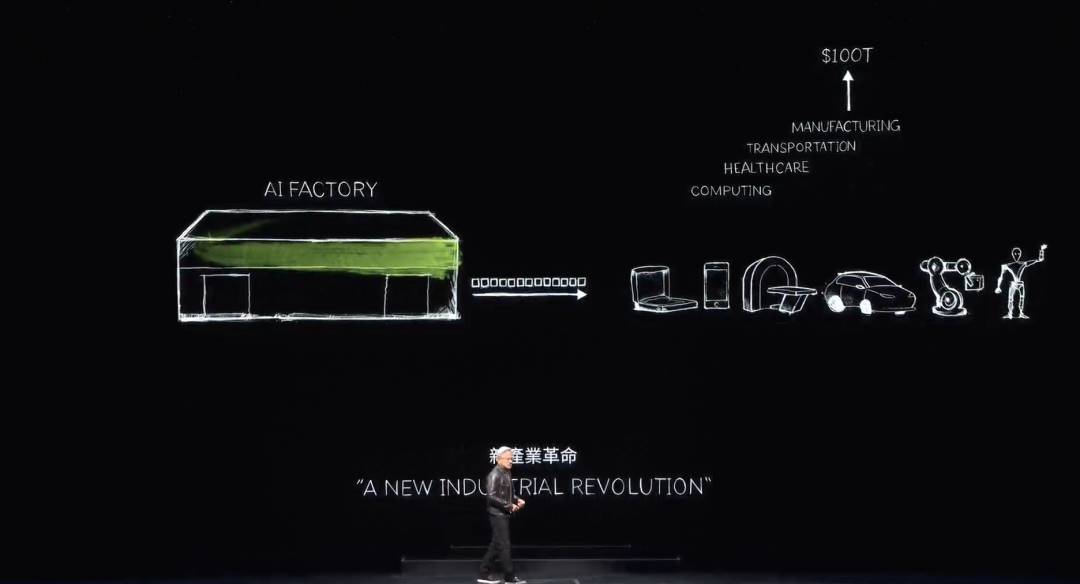
我々は今、生成AIの時代に入りました。しかし真に重要なのは、当初スーパーコンピュータとして始まったこのコンピュータが、今やデータセンターへと進化し、ただ一つのもの――トークン――を生成しているということです。これはAI工場であり、このAI工場は極めて高い価値を持つ新しい商品を創造・生産しています。
19世紀末、ニコラ・テスラは交流発電機を発明しました。NVIDIAはAIジェネレーターを発明しました。交流発電機は電子を生成し、NVIDIAのAIジェネレーターはトークンを生成します。これら二つのものは、市場で巨大なチャンスを持ち、ほぼすべての業界で完全に代替可能です。だからこそ、これは新たな産業革命なのです。
NVIDIAは今、各業界に新しい商品を生産する新しい工場を持っています。この商品は非凡な価値を持ち、この手法は非常にスケーラブルで、再現性も非常に高いです。
毎日、これほど多くの異なる生成AIモデルが発明されていることに気づきます。各業界が今、次々と参入しています。3兆ドル規模のIT業界が、100兆ドル規模の産業に直接役立つ何かを生み出そうとしているのは、これが初めてのことです。情報の保存やデータ処理のツールではなく、各業界に知能を生成する工場です。これは製造業になりますが、コンピュータの製造業ではなく、コンピュータを使って製造する業態です。
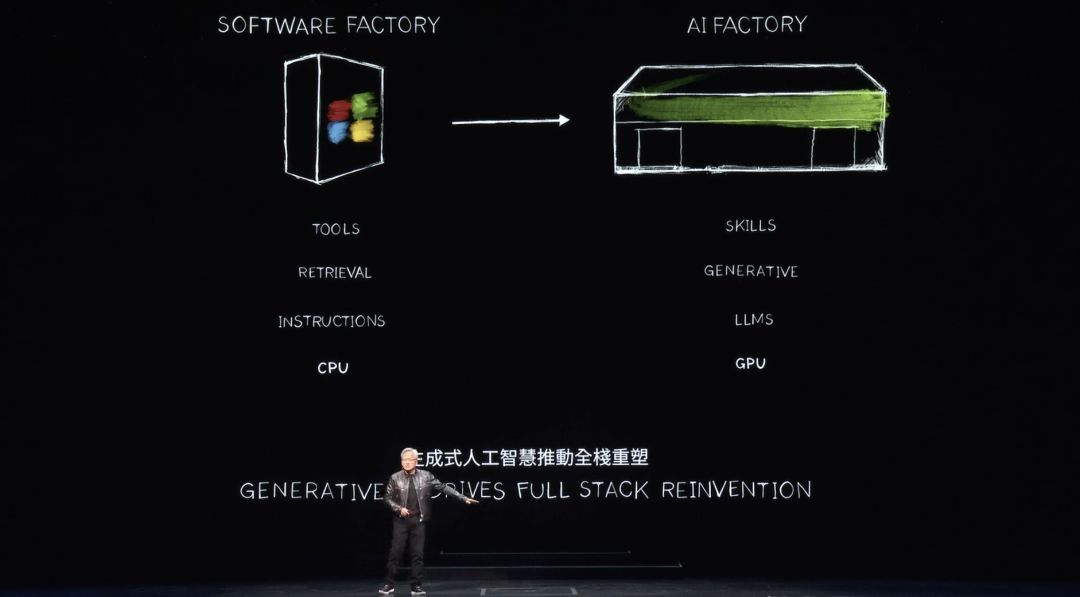
これは歴史上かつてないことです。加速コンピューティングがAIを生み、生成AIを生み、今や産業革命を生み出しています。業界への影響も非常に顕著で、多くの業界に新しい商品、新しい製品を創出できます。それをトークンと呼んでもよいのですが、自らの業界への影響も極めて深いのです。
60年間にわたり、計算の各レイヤーが変化してきました。CPUによる汎用コンピューティングから、GPUによる加速コンピューティングへ。コンピュータは命令を必要としていました。今やコンピュータはLLM、AIモデルを処理します。かつての計算モデルは検索に基づいていました。スマートフォンに触れるたび、事前に録画されたテキスト、画像、動画が検索され、推薦システムに基づいて再構成され、提示されます。
フアン氏は、「将来のコンピュータは、必要な情報を検索するだけでなく、できる限り多くのデータを生成するようになります。理由は、生成されたデータの方が情報を得るために必要なエネルギーが少ないからです。生成されたデータは文脈にもより関連性があります。知識を符号化し、あなたを理解します。コンピュータに情報を取得させたりファイルを探させたりするのではなく、直接あなたの質問に答えてもらいます。コンピュータはもはや私たちが使う道具ではなく、スキルを生成し、タスクを実行する存在になります」と述べました。
NIMs:NVIDIA推論マイクロサービス

ソフトウェアを生産する業界という考え方は、90年代初頭に革命的なアイデアでした。マイクロソフトがソフトウェアのパッケージ化という概念を生み出したことでPC業界が革命を受けました。パッケージ化されたソフトウェアがなければ、PCで何ができるでしょうか?それが業界を牽引しました。今、NVIDIAは新しい工場、新しいコンピュータを持っています。その上では、NIMs(NVIDIA Inference Microservices:NVIDIA推論マイクロサービス)と呼ばれる新しいソフトウェアを実行します。
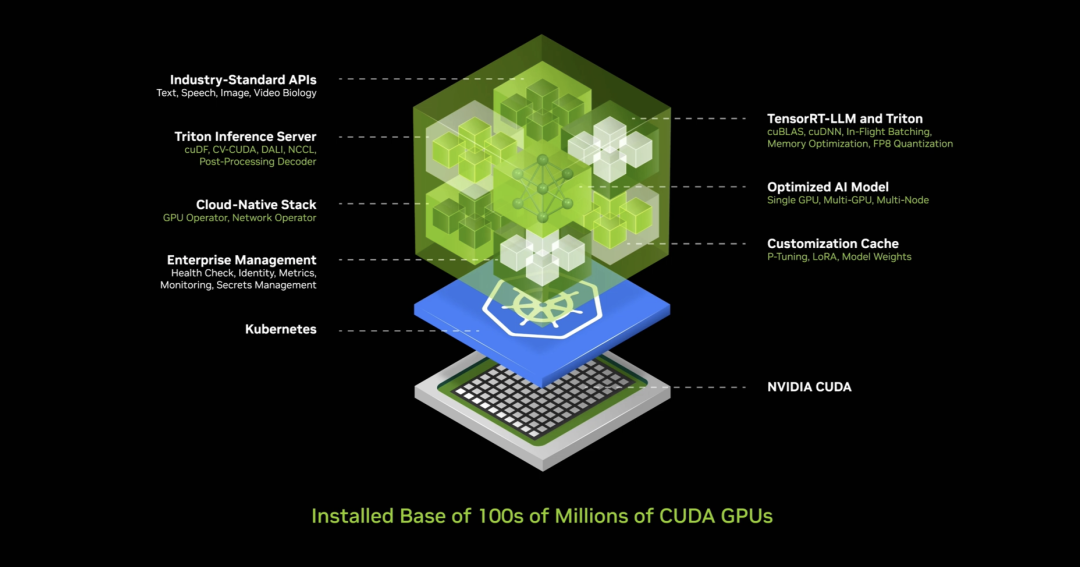
この工場内部でNIMが動作します。このNIMは事前訓練済みモデル、すなわちAIです。このAI自体は非常に複雑ですが、AIを動作させる計算スタックはさらに極めて複雑です。ChatGPTを使うとき、その背後にあるスタックは膨大なソフトウェアです。背後にあるプロンプトも膨大なソフトウェアで、非常に複雑です。モデルは巨大で、数十億から数兆のパラメータを持ち、単一のコンピュータではなく複数のコンピュータで動作します。ワークロードを複数のGPUに分配し、テンソル並列、パイプライン並列、データ並列、各種並列、エキスパート並列などを活用し、できるだけ迅速に処理します。
なぜなら、工場で稼働している場合、スループットは直接収益に関係するからです。スループットはサービス品質、利用可能な人数とも直接関係します。
我々は今、データセンターのスループット利用率が極めて重要な世界にいます。以前も重要でしたが、今ほどではありませんでした。以前も重要でしたが、測定していませんでした。しかし今、起動時間、実行時間、利用率、スループット、アイドル時間など、すべてのパラメータが測定されています。なぜならこれは工場だからです。あるものが工場であるとき、その運用は直接企業の財務実績に関係します。これはほとんどの企業にとって極めて複雑な問題です。

そこでNVIDIAは何をしたか?NVIDIAはこのAIボックスを作りました。このコンテナの中には膨大なソフトウェアが詰め込まれています。コンテナ内部にはCUDA、cuDNN、TensorRT、Triton推論サービスが含まれています。クラウドネイティブで、Kubernetes環境で自動スケーリング可能。管理サービスとフックがあり、AIを監視できます。共通API、標準APIがあり、このボックスと会話できます。このNIMをダウンロードし、会話できます。あなたのコンピュータにCUDAがあれば、今やどこにでもある状態です。すべてのクラウド、すべてのコンピュータメーカーから利用可能。数億台のPCで利用可能で、すべてのソフトウェアが統合され、400もの依存関係が一つにまとめられています。
NVIDIAはこのNIMをテストしました。すべての事前訓練済みモデルを、Pascal、Ampere、Hopperのすべてのバージョンでテストしました。名前を忘れたものさえあります。信じがたい発明で、私の最も好きなものの一つです。
フアン氏は、「NVIDIAは言語ベース、視覚ベース、画像ベース、医療、デジタル生物学用、デジタルヒューマン用など、さまざまなバージョンをすべて持っています。ai.nvidia.comにアクセスするだけで利用できます」と述べました。
また、「本日、NVIDIAはHuggingFaceに完全に最適化されたLlama3 NIMを公開しました。そこであなたが試すことができ、そのまま持って帰ることもできます。無料で提供されます。任意のクラウドで実行できます。このコンテナをダウンロードし、自分のデータセンターに配置し、お客様に提供することもできます」と述べました。
NVIDIAは物理学、セマンティック検索(RAGsと呼ばれる)、視覚言語、さまざまな言語など、さまざまな分野向けのバージョンを揃えています。これらのマイクロサービスの使い方は、大規模なアプリケーションに接続することです。
将来最も重要なアプリケーションの一つは、もちろんカスタマーサービスです。ほぼすべての業界にエージェントが必要です。これは数兆ドル規模のカスタマーサービスを表します。看護師もある意味でカスタマーサービスエージェントです。非処方・非診断的な看護師は基本的に小売業のカスタマーサービスであり、ファストフード、金融、保険業界などです。数千万人のカスタマーサービス担当者は、今や言語モデルとAIで強化できます。そのため、あなたが見ているこれらのボックスは基本的にNIMsです。
いくつかのNIMは推論エージェントで、タスクを与え、それを特定し、計画に分解します。いくつかのNIMは情報を検索します。いくつかのNIMは検索を行います。いくつかのNIMはツールを使います。前述のcuOptのようなものです。SAP上で動作するツールを使うことができます。そのため、ABAPという特定の言語を学ぶ必要があります。おそらく一部のNIMはSQLクエリを行う必要があります。そのため、これらすべてのNIMは専門家であり、今やチームとして組み合わされています。
では何が変わったのか?アプリケーション層が変わりました。かつて命令で書かれたアプリケーションは、今やAIチームを組み立てるアプリケーションになりました。プログラミングの方法を知っている人は少数ですが、問題を分解し、チームを組み立てる方法を知っている人はほぼ全員です。私は、将来すべての企業が大量のNIMコレクションを持つようになると信じています。欲しい専門家をダウンロードし、チームとして接続します。どのように接続するか正確に知る必要さえありません。タスクをエージェント、NIMに渡すだけで、それがどのように割り当てるか決定します。そのチームリーダーエージェントがタスクを分解し、各チームメンバーに割り当てます。チームメンバーがタスクを実行し、結果をチームリーダーに戻し、チームリーダーが結果を推論し、あなたに情報を提示します。まるで人間のように。これは近い将来の、アプリケーションの未来の姿です。
もちろん、これらの大規模AIサービスとは、テキストプロンプトや音声プロンプトで対話できます。しかし、多くのアプリケーションは人間のような形での対話を望んでいます。NVIDIAはこれを「デジタルヒューマン」と呼び、デジタルヒューマン技術の研究を続けています。
フアン氏は続け、「デジタルヒューマンは、あなたと対話する優れたエージェントとなり、インタラクションをより魅力的で、思いやりのあるものにする可能性があります。もちろん、デジタルヒューマンがより自然に見えるように、この巨大なリアリズムのギャップを越える必要があります。将来的に、コンピュータが人間のように私たちと対話できる世界を想像してください。これがデジタルヒューマンの驚異的な現実です。デジタルヒューマンは、カスタマーサービスから広告、ゲームに至るまで、さまざまな業界を根本的に変えます。デジタルヒューマンの可能性は無限です。
現在のキッチンのスキャンデータを使用します。スマートフォンを通じて、AIインテリアデザイナーとなり、美しいフォトリアルな提案を生成し、素材や家具の入手先を提供します。
NVIDIAがあなたのためにいくつかのデザインオプションを生成しました。また、AIカスタマーサービスエージェントとなり、インタラクションをより生き生きと個別化し、あるいはデジタル医療従事者となり、患者を診察し、タイムリーで個別化されたケアを提供します。AIブランドアンバサダーとなり、次の波のマーケティングと広告のトレンドを設定することさえあります。
生成AIとコンピュータグラフィックスの新ブレークスルーにより、デジタルヒューマンは人間のように見て、理解し、私たちと対話できるようになりました。私が見ている限り、あなたはどこかの録音
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News












