

Analyse de MonadBFT (1ère partie) : comment résoudre le problème de la fourche terminale
TechFlow SélectionTechFlow Sélection
Analyse de MonadBFT (1ère partie) : comment résoudre le problème de la fourche terminale
La bifurcation finale fausse les incitations économiques des proposants de blocs et constitue également une menace potentielle pour l'activité du réseau. MonadBFT garantit qu'aucun bloc proposé par un leader honnête et obtenant une majorité légale de votes ne sera abandonné ou sauté, grâce à l'introduction d'un mécanisme de reproposition et de certificats sans endorsement (NEC).
Le cœur de la blockchain réside dans la mise en œuvre d'un consensus global strict : autrement dit, quel que soit le pays ou le fuseau horaire où se trouvent les nœuds du réseau, tous les participants doivent finalement s'accorder sur un ensemble de résultats objectifs.
Mais les réseaux distribués dans la réalité ne sont pas parfaits : certains nœuds tombent en panne, d'autres mentent, voire sabotent délibérément le système. Dans ce cas, comment le système parvient-il à « parler d'une seule voix » et à rester cohérent ?
C'est précisément là que le protocole de consensus intervient. Il s'agit fondamentalement d'un ensemble de règles destinées à guider un groupe de nœuds indépendants, voire partiellement non fiables, afin qu'ils parviennent à une décision unifiée sur l'ordre et le contenu de chaque transaction.
Et une fois ce « consensus strict » établi, la blockchain peut débloquer de nombreuses fonctionnalités clés, telles que la garantie de propriété numérique, des modèles monétaires résistants à l'inflation, ainsi qu'une structure de collaboration sociale extensible. Mais à condition que le protocole de consensus lui-même garantisse simultanément deux fondamentaux :
- Deux blocs mutuellement conflictuels ne peuvent pas être confirmés ;
- Le réseau doit continuer à progresser sans s'enrayer ni s'arrêter.
MonadBFT constitue la dernière percée technologique dans cette direction.
Rappel succinct de l'évolution du protocole de consensus
Le domaine des mécanismes de consensus a été étudié pendant plusieurs décennies. Les premiers protocoles, comme PBFT (Practical Byzantine Fault Tolerance), étaient déjà capables de gérer une situation très réaliste : même si certaines parties du réseau perdent la connexion, agissent malicieusement ou diffusent de fausses informations, tant que ces nœuds défaillants ne dépassent pas un tiers du total, le système peut encore parvenir à un accord.
La conception de ces premiers protocoles était plutôt « traditionnelle » : à chaque tour, un leader est choisi pour proposer une proposition, puis les autres validateurs votent sur celle-ci en plusieurs tours, confirmant progressivement l'ordre des transactions.
Le processus de vote complet passe généralement par plusieurs phases, comme pre-prepare, prepare, commit et reply. À chaque étape, tous les validateurs doivent communiquer entre eux. Autrement dit, chacun doit envoyer un message à tous les autres, ce qui entraîne une croissance explosive du volume de messages, en forme de « réseau ».
La complexité de cette structure de communication est en n² — c’est-à-dire que si le réseau compte 100 validateurs, près de 10 000 messages peuvent être transmis à chaque tour de consensus.
Cela ne pose pas de problème majeur dans un petit réseau, mais dès que le nombre de validateurs augmente, la charge de communication devient rapidement insoutenable, rendant l'efficacité du système fortement compromise.
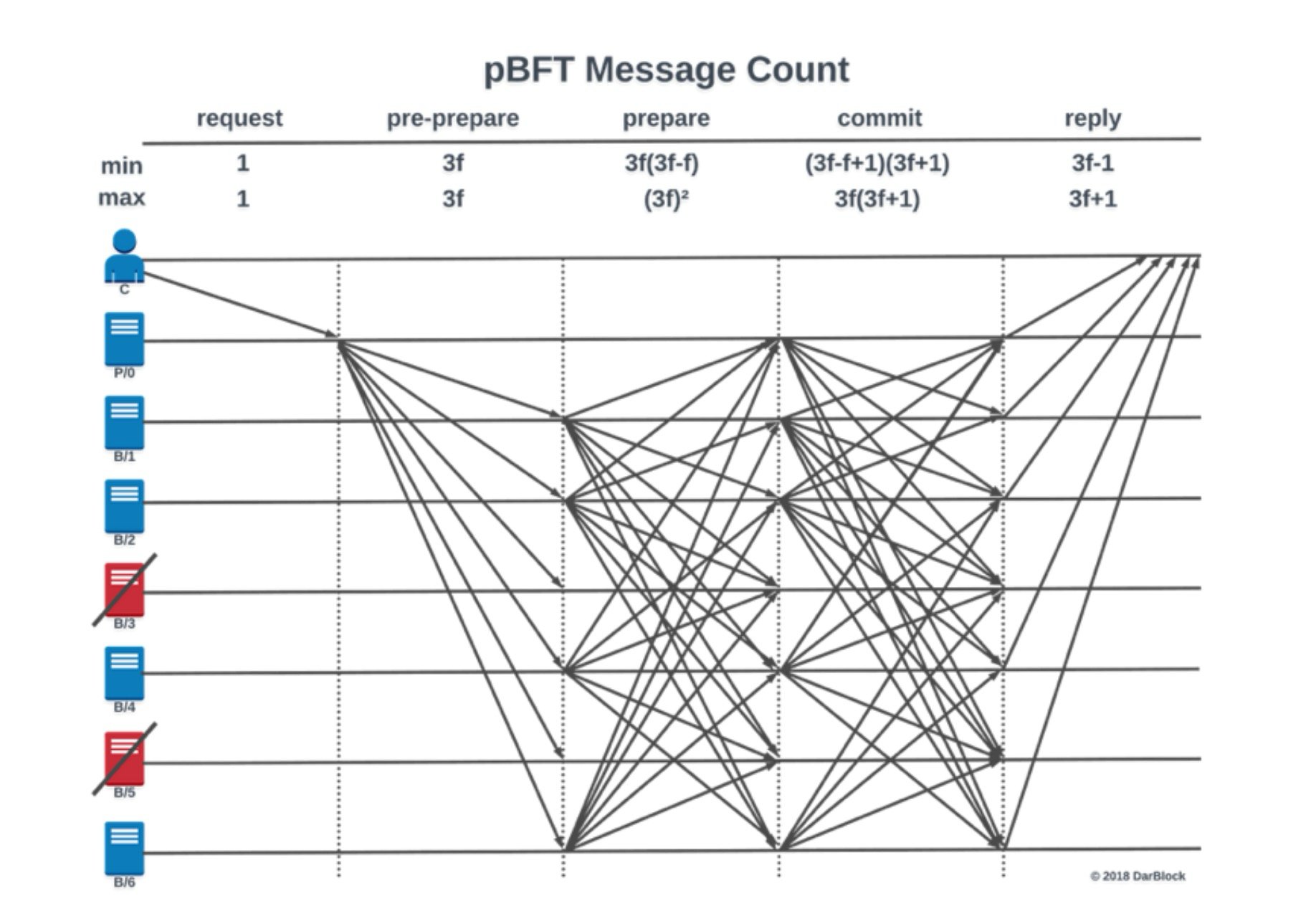
Cette structure de communication quadratique, où « chacun communique avec chacun », est en réalité très inefficace. Par exemple, dans un réseau de 100 validateurs, chaque tour de consensus pourrait nécessiter des dizaines de milliers de messages.
Ce type de système peut encore fonctionner dans un petit cercle fermé, mais sur un réseau ouvert et mondial, la charge de communication devient immédiatement inacceptable. Ainsi, des protocoles BFT précoces comme PBFT ou Tendermint ne sont généralement utilisés que dans des scénarios de réseaux autorisés (permissioned network) ou avec un très petit nombre de validateurs, pour pouvoir simplement fonctionner.
Pour permettre aux protocoles BFT de s'adapter à des environnements de blockchains publiques non autorisées, de nouvelles conceptions ont commencé à adopter des modes de communication plus légers : chaque validateur communique uniquement avec le leader, au lieu d’échanger des messages avec tous les autres.
Cela réduit la complexité des messages de n² à n — allégeant considérablement la charge du système.
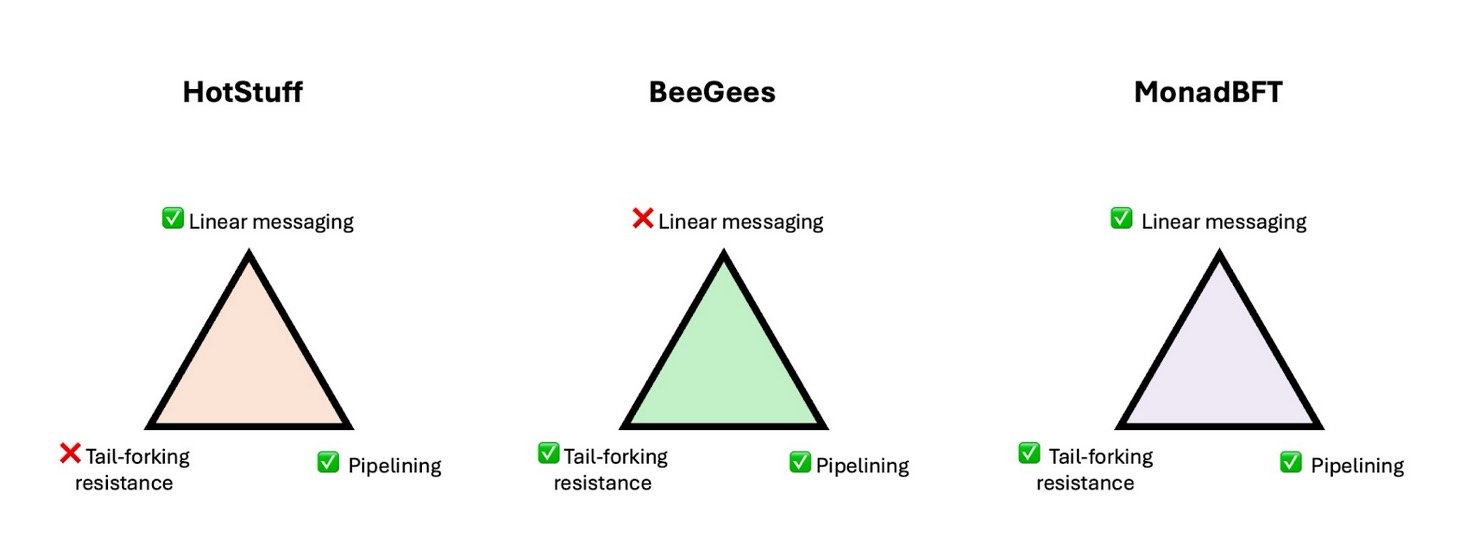
Le protocole HotStuff a été introduit en 2018 précisément pour résoudre ce problème d’extensibilité. Son concept de conception est très clair : remplacer le processus de vote complexe de PBFT par une structure de communication plus simple et pilotée par un leader.
La caractéristique clé de HotStuff est sa communication dite linéaire. Dans son mécanisme, chaque validateur n’a besoin que d’envoyer son vote au leader actuel, qui regroupe ensuite ces votes pour générer un Quorum Certificate (QC, preuve de majorité).
Ce QC est essentiellement une signature collective prouvant à tout le réseau : « La majorité des nœuds a approuvé cette proposition. »
En comparaison, le mode de communication de PBFT est une « diffusion à tous », où chacun parle dans le groupe, créant un chaos relatif. Le modèle HotStuff ressemble davantage à « un seul collecteur, un seul paquetage », permettant au système de fonctionner efficacement peu importe le nombre de participants.
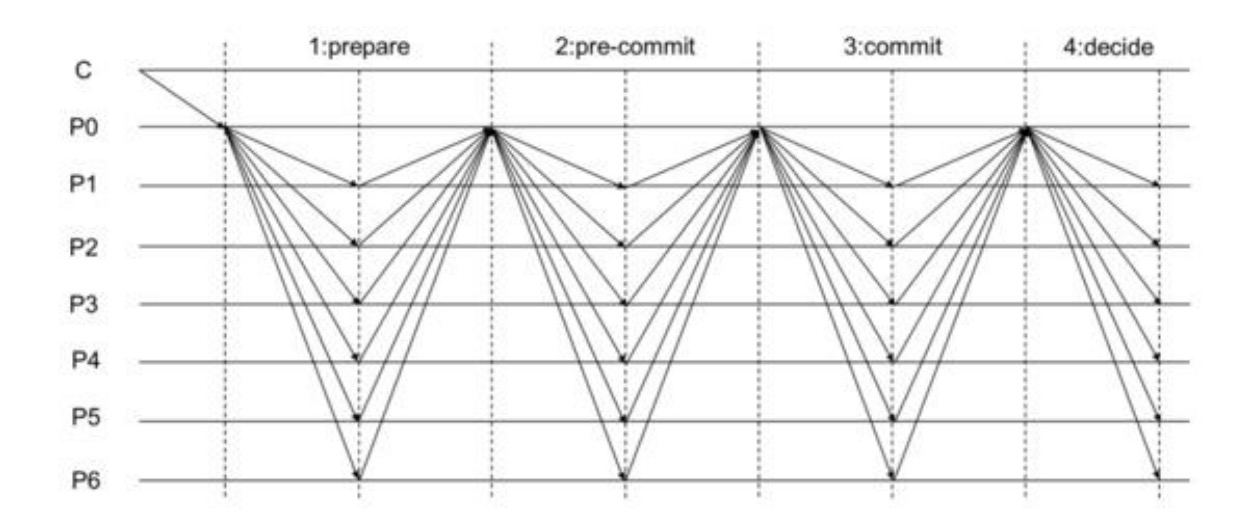
Au-delà de la communication linéaire, HotStuff peut être amélioré en version pipelinée (pipelined HotStuff), afin d’accroître l’efficacité.
Dans HotStuff d’origine, le même validateur reste leader pendant plusieurs tours successifs jusqu’à ce qu’un bloc soit pleinement confirmé. Ce processus suit le principe « un bloc à la fois », toute l’attention étant concentrée sur l’avancement du bloc courant.
Dans HotStuff pipeliné, le mécanisme devient plus flexible : un nouveau leader est désigné à chaque tour, et chaque leader a deux tâches :
- Regrouper les votes du tour précédent en un Quorum Certificate (QC) et le diffuser à tout le réseau ;
- Proposer un nouveau bloc, préparant ainsi le prochain tour.
Autrement dit, on ne traite plus « un bloc après confirmation complète du précédent », mais comme une chaîne de montage, où différents leaders gèrent chacun une étape. Le précédent propose un bloc, le suivant le confirme tout en proposant un nouveau bloc, et le consensus avance comme un relais.
C’est d’où vient l’analogie avec le « pipeline » : tandis que le bloc actuel est en cours de confirmation, le suivant est déjà en préparation, permettant un traitement parallèle et une meilleure efficacité.
En résumé, les protocoles comme HotStuff ont apporté des améliorations majeures par rapport aux anciens BFT selon deux axes :
- Communication allégée, chaque validateur n’ayant besoin de communiquer qu’avec le leader ;
- Meilleure efficacité de traitement, avec possibilité de paralléliser la confirmation de plusieurs blocs.
Cela fait de HotStuff un modèle de conception pour de nombreux mécanismes de consensus PoS modernes. Mais tout avantage a son revers — bien que performante, la structure en pipeline introduit discrètement un risque structurel difficile à détecter.
Nous allons maintenant approfondir ce problème central : le tail-forking (fourchement de queue).
Le problème de tail-forking (fourchement de queue)
Bien que HotStuff — particulièrement sa version pipelinée — ait résolu le problème d’extensibilité des protocoles de consensus, il a également introduit de nouveaux défis. Le plus critique et souvent négligé est ce qu’on appelle le « tail-forking » (fourchement de queue).
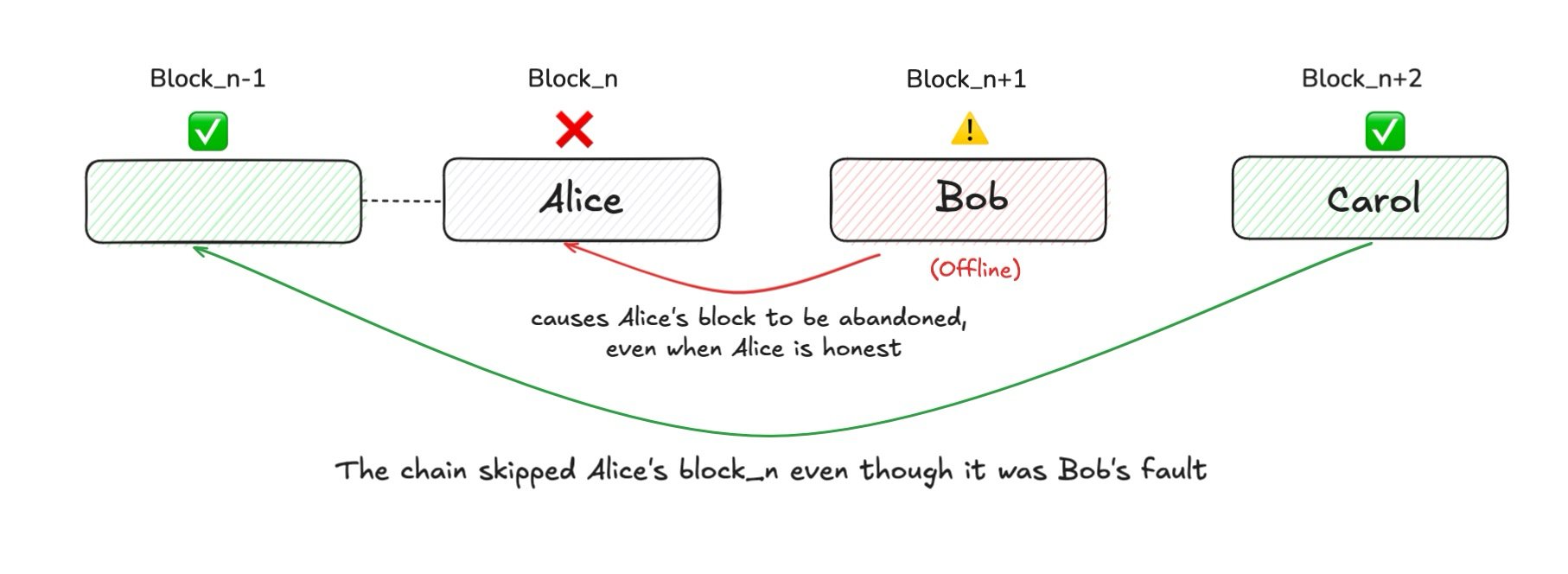
Qu’est-ce que le tail-forking ? On peut le comprendre simplement comme une restructuration inattendue (reorg) à l’extrémité de la chaîne.
Plus précisément, un bloc valide a été correctement diffusé à la majorité des validateurs, a reçu suffisamment de votes, et semblait sur le point d’être confirmé et intégré à la chaîne principale. Pourtant, il finit par être « ignoré », abandonné (orphaned), et remplacé par un autre bloc au même niveau de hauteur.
Il ne s’agit ni d’un bug ni d’une attaque, mais d’une possibilité inhérente à la structure même du protocole. Cela semble injuste, n’est-ce pas ? Alors, comment cela se produit-il exactement ?
Nous avons mentionné précédemment que chaque leader dans HotStuff pipeliné a deux tâches :
- A. Proposer un nouveau bloc (par exemple Bₙ₊₁)
- B. Collecter les votes pour le bloc du leader précédent et générer un QC (par exemple finaliser Bₙ)
Ces deux tâches sont exécutées en parallèle, comme un relais. Mais c’est justement ici que le problème surgit.
Par exemple : supposons qu’Alice soit le leader au tour n, elle propose le bloc Bₙ, qui obtient une supermajorité de votes et est presque confirmé. Ensuite, Bob devient le leader et doit proposer le bloc suivant Bₙ₊₁, tout en incluant le QC de Bₙ dans sa proposition pour finaliser Bₙ.
Mais si Bob est hors ligne ou refuse délibérément d’inclure le QC de Bₙ, un problème survient.
Personne n’ayant inclus le QC de Bₙ, les votes restent locaux, le bloc qui aurait dû être confirmé est « mis de côté », puis ignoré par le réseau.
Tel est l’essence du tail-forking : le bloc du leader précédent est ignoré à cause de la défaillance ou de la malveillance du leader suivant.
Pourquoi le tail-forking est-il grave ?
Le problème du tail-forking se concentre principalement sur deux aspects : 1) la distorsion du mécanisme d’incitation, 2) la menace sur l’activité du système.
Premièrement, les récompenses sont perdues : si un bloc est abandonné, son leader ne reçoit aucune récompense, ni la prime de création de bloc ni les frais de transaction. Par exemple, Alice propose un bloc légitime et recueille une supermajorité de votes, mais à cause d’une erreur ou d’une action malveillante de Bob, le bloc n’est pas confirmé, et Alice ne touche rien. Cela crée une structure d’incitation erronée : des nœuds malveillants comme Bob peuvent « couper » les récompenses des concurrents en ignorant leurs blocs. Cette action ne nécessite aucune attaque technique, seulement un refus de coopération, ce qui affaiblit les revenus des compétiteurs. Si cela se reproduit, cela nuit à long terme à l’engagement et à l’équité du système, pouvant même inciter à la collusion entre nœuds.
Deuxièmement, élargissement des opportunités d’attaque MEV : le tail-forking crée aussi un problème plus subtil mais sérieux : l’espace de manipulation malveillante de la MEV (Maximum Extractable Value) augmente. Par exemple : supposons qu’il y ait une transaction d’arbitrage très lucrative dans le bloc d’Alice. Bob, s’il veut nuire, peut s’allier avec le prochain leader Carol pour ne pas diffuser le bloc d’Alice. Puis Carol reconstruit un nouveau bloc à la même hauteur, copiant la transaction d’arbitrage d’Alice — capturant ainsi la MEV pour elle-même. Cette pratique de « réorganisation de tête + collusion » respecte formellement les règles de création de bloc, mais constitue en réalité un pillage soigneusement orchestré. Pire encore, cela incite les leaders à former des « accords secrets », transformant la confirmation des blocs en un jeu de répartition des profits plutôt qu’en un service public.
Troisièmement, compromission de la garantie de finalité, impact sur l’expérience utilisateur : contrairement aux protocoles de type Nakamoto, un grand avantage des protocoles BFT est leur finalité déterministe : une fois qu’un bloc est soumis, il ne peut pas être annulé. Mais le tail-forking brise cette garantie, surtout pour les blocs ayant déjà reçu des votes mais pas encore confirmés officiellement. Certaines dapps à haut débit espèrent souvent lire les données juste après le vote d’un bloc pour réduire la latence, et si ce bloc est soudainement abandonné, cela peut entraîner un retour arrière de l’état utilisateur — par exemple un solde de compte anormal, une transaction à effet de levier élevée disparaissant soudainement, ou un état de jeu réinitialisé brutalement.
Quatrièmement, risque de défaillance en cascade : généralement, le tail-forking peut retarder la confirmation d’un bloc d’un seul tour, un impact mineur. Mais dans certains cas extrêmes, si plusieurs leaders consécutifs choisissent d’ignorer le bloc précédent, le système peut s’immobiliser, personne ne voulant « reprendre » le bloc antérieur. L’avancement de la chaîne entière s’arrête alors, jusqu’à ce qu’un leader « responsable » apparaisse pour relancer le réseau.
Bien que certaines solutions existaient auparavant, comme le mécanisme d’évitement du tail-forking proposé par BeeGees, elles impliquaient souvent des sacrifices de performance, comme le retour à une complexité de communication quadratique, ce qui n’en valait pas la peine.
Qu’est-ce que MonadBFT ?
MonadBFT est un nouveau protocole de consensus spécialement conçu pour résoudre le problème de tail-forking. Sa force réside dans le fait qu’il corrige les failles structurelles sans sacrifier les gains de performance apportés par HotStuff en pipeline. Autrement dit, MonadBFT ne repart pas de zéro, mais optimise le cadre central de HotStuff. Il conserve trois caractéristiques clés :
- Rotation du leader (rotating leader) : un nouveau leader est désigné à chaque tour pour faire avancer la chaîne ;
- Soumissions en pipeline (pipelined commits) : plusieurs processus de confirmation de blocs peuvent se chevaucher ;
- Communication linéaire (linear messaging) : chaque validateur n’a besoin de communiquer qu’avec le leader, économisant ainsi une grande partie de la charge réseau.
Mais ces trois points ne suffisent pas à assurer la sécurité. Pour colmater la faille structurelle du tail-forking, MonadBFT ajoute deux mécanismes clés :
- Mécanisme de reproposition forcée (Re-Proposal)
- Certificat sans aval (NEC, No-Endorsement Certificate)
Mécanisme de reproposition (Re-Proposal)
Dans les protocoles BFT, le temps est divisé en tours (appelés view), chaque tour ayant un leader chargé de proposer un nouveau bloc. Si le leader échoue (par exemple, ne propose pas de bloc à temps ou présente une proposition invalide), le système passe au tour suivant et désigne un nouveau leader.
MonadBFT ajoute un mécanisme garantissant qu’aucun bloc honnêtement proposé ne sera perdu à cause d’un changement de leader.
Lorsqu’un leader actuel échoue, les validateurs envoient un message signé de changement de vue (view change), indiquant que le tour actuel a expiré.
Fait important, ce message ne signifie pas seulement « délai expiré », mais doit aussi inclure l’information du dernier bloc voté par le validateur, comme s’il disait : « Je n’ai pas reçu de proposition valide, voici le bloc le plus récent que j’ai vu. »
Le nouveau leader collecte ces messages d’expiration provenant d’une supermajorité (2f+1) de validateurs, puis les fusionne en un certificat d’expiration (Timeout Certificate, TC). Ce TC représente une image instantanée du consensus du réseau sur le « bloc de tête » lorsque le tour précédent a échoué. Le nouveau leader extrait alors le bloc de hauteur maximale (ou numéro de vue le plus élevé), appelé high_tip.
MonadBFT exige que la proposition du nouveau leader inclue un TC valide, et qu’il doive reproposer le bloc suspendu le plus élevé dans le TC, lui offrant ainsi une nouvelle chance d’être confirmé.
Pourquoi ? Comme mentionné précédemment : nous ne voulons pas qu’un bloc presque confirmé disparaisse soudainement.
Exemple : supposons qu’Alice soit le leader du view 5, elle propose un bloc valide et obtient la majorité des votes. Ensuite, Bob, leader du view 6, est hors ligne et ne fait pas avancer la chaîne. Quand Carol devient leader du view 7, selon les règles de MonadBFT, elle doit inclure le TC et reproposer le bloc d’Alice. Ainsi, le travail honnête d’Alice n’est pas perdu.
Si Carol n’a pas le bloc d’Alice, elle peut le demander aux autres nœuds. Ces derniers peuvent :
- Fournir le bloc, ou
- Renvoyer un message signé « sans aval » (No-Endorsement, NE), indiquant qu’ils n’ont pas ce bloc (le mécanisme sera expliqué plus bas). (Au maximum f nœuds byzantins peuvent ignorer la demande et ne pas répondre.)
Dès que Carol reproposera le bloc d’Alice, elle obtiendra une opportunité supplémentaire de proposition, évitant ainsi d’être pénalisée à cause de l’échec du leader précédent.
L’objectif de ce mécanisme de reproposition est clair : garantir que la progression de la chaîne soit équitable, et qu’aucun travail valide ne soit silencieusement abandonné par malchance ou sabotage.
Certificat sans aval (NEC)
Reprenons l’exemple précédent : après l’expiration du tour de Bob, Carol demande aux autres validateurs de fournir le bloc high_tip (celui d’Alice). Au moins 2f+1 validateurs répondront alors :
- Soit en fournissant le bloc d’Alice
- Soit en envoyant un message NE signé, indiquant qu’ils n’ont pas reçu le bloc d’Alice
Dès que Carol reçoit le bloc d’Alice, elle doit obligatoirement le reproposer selon les règles. Elle ne peut sauter ce bloc et en proposer un nouveau que si elle reçoit des messages NE signés d’au moins f+1 validateurs.
Pourquoi f+1 ? Dans un système BFT composé de 3f+1 validateurs, au maximum f peuvent être malveillants. Si le bloc d’Alice a effectivement obtenu une supermajorité de votes, au moins 2f+1 nœuds honnêtes l’ont reçu.
Par conséquent, si Carol affirme « je ne peux pas obtenir le bloc d’Alice », elle doit présenter des signatures de f+1 validateurs prouvant qu’ils ne l’ont pas reçu. Cela constitue un certificat sans aval (No-Endorsement Certificate, NEC).
Le NEC est un justificatif d’exemption pour le leader : c’est une preuve vérifiable que le bloc précédent n’était pas prêt à être confirmé, et qu’il n’est pas ignoré malicieusement, mais abandonné pour de bonnes raisons.
Reproposition + Certificat sans aval = Résolution du tail-forking
En introduisant le mécanisme de reproposition (Re-Proposal) et le certificat sans aval (NEC), MonadBFT établit un ensemble de règles rigoureuses et claires pour le traitement du bloc de tête :
Soit finaliser la soumission du bloc « presque confirmé » ; soit fournir des preuves suffisantes qu’il n’est pas encore prêt à être confirmé ; sinon, il est interdit de sauter ou remplacer le bloc précédent.
Ce mécanisme garantit que tout bloc ayant reçu une majorité légale de votes ne sera pas abandonné à cause d’une erreur ou d’une omission intentionnelle du leader. Le risque structurel de tail-forking est systématiquement éliminé, et le protocole impose des contraintes claires contre les sauts abusifs.
Si un leader tente de sauter un bloc précédent sans justification, et ne fournit pas de NEC, le protocole détectera et rejettera immédiatement cette action. Tout saut sans preuve cryptographique est illégal et ne recevra pas le soutien du consensus du réseau.
Sur le plan des incitations économiques, cette conception offre une protection claire aux validateurs :
- Tout bloc honnêtement proposé et soutenu par des votes ne verra pas ses récompenses annulées à cause d’un dysfonctionnement ultérieur ;
- Même dans des situations extrêmes, par exemple si un nœud saute intentionnellement son tour de proposition pour aider un autre à s’emparer de la MEV d’un bloc précédent, le protocole oblige le leader suivant à reproposer prioritairement l’ancien bloc, empêchant ainsi l’attaquant de tirer profit économiquement du saut.
Encore plus important, MonadBFT n’a pas sacrifié la performance pour renforcer la sécurité.
Certaines conceptions antérieures contre le tail-forking (comme le protocole BeeGees), bien que dotées d’une certaine protection, dépendaient souvent d’une forte complexité de communication (n²) ou activaient des processus de recommunication à chaque tour, ce qui augmentait fortement la charge du système en pratique.
La stratégie de conception de MonadBFT est plus ingénieuse :
Les communications supplémentaires (messages d’expiration, reproposition de blocs) ne sont lancées que lors d’une défaillance de vue ou d’une anomalie. Sur le chemin normal où des leaders honnêtes produisent des blocs successivement, le protocole maintient un fonctionnement léger et efficace.
Cet équilibre dynamique entre performance et sécurité constitue l’un des avantages centraux de MonadBFT par rapport aux protocoles précédents.
Résumé
Cet article a passé en revue les mécanismes de base du consensus PBFT traditionnel, retracé l’évolution du protocole HotStuff, et expliqué en détail comment MonadBFT résout au niveau structurel le problème endogène de tail-forking dans HotStuff en pipeline.
Le tail-forking déforme les incitations économiques des proposants de blocs et constitue une menace potentielle pour l’activité du réseau. Grâce au mécanisme de reproposition et au certificat sans aval (NEC), MonadBFT garantit que tout bloc proposé honnêtement et ayant obtenu une majorité légale de votes ne sera ni abandonné ni ignoré.
Dans le prochain article, nous explorerons deux autres caractéristiques fondamentales de MonadBFT :
- Finalité spéculative (Speculative Finality)
- Réactivité optimiste (Optimistic Responsiveness)
Et nous analyserons plus en profondeur la signification pratique de ces mécanismes pour les validateurs et les développeurs.
À suivre.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














