

Transcription de l'événement AI on AO | Les trois percées technologiques d'AO Protocol : construire un modèle linguistique volumineux décentralisé
TechFlow SélectionTechFlow Sélection
Transcription de l'événement AI on AO | Les trois percées technologiques d'AO Protocol : construire un modèle linguistique volumineux décentralisé
Ceci marque le début de l'intégration de l'intelligence de marché dans un environnement d'exécution décentralisé.
Rédaction : Kyle
Relecture : Lemon
Source : Guilde du contenu - Actualités
Merci à tous d’être présents aujourd’hui. Nous avons une série de progrès technologiques extrêmement passionnants concernant AO à partager avec vous. Nous allons d’abord faire une démonstration, puis Nick et moi tenterons ici même de construire un agent d’intelligence artificielle qui utilisera un grand modèle linguistique dans un contrat intelligent pour acheter ou vendre en fonction de l’humeur des conversations que vous allez entendre dans ce système. Nous allons le construire en direct, depuis zéro, espérons que tout se passe bien.
Oui, vous verrez comment faire tout cela par vous-mêmes.
Les avancées technologiques dont nous disposons permettent à AO de largement surpasser tous les autres systèmes de contrats intelligents. C’était déjà vrai auparavant, mais désormais cela ressemble de plus en plus à un superordinateur décentralisé plutôt qu’à un réseau classique de contrats intelligents — tout en conservant toutes les caractéristiques d’un tel réseau. Nous sommes donc très enthousiastes à l'idée de partager tout cela avec vous. Sans plus tarder, commençons par la démonstration, puis nous discuterons ensemble, et construirons quelque chose en direct.
Bonjour à tous, merci d’être là aujourd’hui. Nous sommes ravis d’annoncer trois mises à jour technologiques majeures du protocole AO. Ensemble, elles atteignent un objectif ambitieux : permettre aux grands modèles linguistiques de fonctionner au sein de contrats intelligents dans un environnement décentralisé. Il ne s'agit pas de petits modèles jouets, ni de modèles compilés dans leurs propres fichiers binaires.
Il s’agit d’un système complet qui vous permet d’exécuter presque tous les principaux modèles actuellement open source et disponibles. Par exemple, Llama 3 peut fonctionner directement sur la chaîne au sein d’un contrat intelligent, de même que GPT ou encore les modèles d’Apple, etc. Ce résultat est le fruit d’un effort collectif de tout l’écosystème, porté par trois grandes avancées technologiques qui constituent cette plateforme. Je suis donc particulièrement enthousiaste à l’idée de vous présenter tout cela.

En résumé, les grands modèles linguistiques (LLM) peuvent désormais fonctionner directement dans des contrats intelligents. Vous avez probablement souvent entendu parler d’IA décentralisée ou de cryptomonnaies IA. En réalité, sauf dans un cas que nous allons aborder aujourd’hui, tous ces systèmes utilisent l’IA comme oracle — c’est-à-dire que l’IA fonctionne hors chaîne, puis ses résultats sont transmis à la chaîne pour être utilisés ultérieurement.
Ce n’est pas ce dont nous parlons ici. Nous parlons d’intégrer le raisonnement du grand modèle linguistique comme partie intégrante de l’exécution de l’état du contrat intelligent. Tout cela devient possible grâce au disque dur AO et au mécanisme de traitement hyper-parallèle d’AO, qui vous permet d’effectuer d’énormes calculs sans interférer avec les différents processus que j’utilise. Nous pensons que cela va nous permettre de créer un système financier décentralisé et autonome extrêmement riche.

Jusqu’à présent, dans la finance décentralisée (DeFi), nous avons essentiellement réussi à rendre l’exécution des transactions élémentaires non nécessitant aucune confiance. Les interactions dans différents jeux économiques, comme l’emprunt ou l’échange, sont désormais non fiables. Mais ce n’est qu’un aspect du problème, si l’on considère les marchés financiers mondiaux.
Oui, divers composants économiques entrent en jeu selon différentes modalités : obligations, actions, matières premières, dérivés, etc. Mais lorsqu’on parle vraiment de marché, il ne s’agit pas seulement de cela, mais aussi de la couche intelligente — les personnes qui décident d’acheter, de vendre, d’emprunter ou de participer à divers jeux financiers.
Jusqu’à présent, dans l’écosystème DeFi, nous avons réussi à rendre tous ces composants non fiables. Ainsi, vous pouvez échanger sur Uniswap sans avoir à faire confiance à l’exploitant de la plateforme. En réalité, fondamentalement, il n’y a aucun exploitant. La couche intelligente du marché reste elle hors chaîne. Donc, si vous souhaitez investir dans les cryptomonnaies sans avoir à effectuer toute la recherche ou y participer vous-même, vous devez trouver un fonds.
Vous lui faites confiance avec votre capital, puis il prend des décisions intelligentes et les transmet à l’exécution des composants de base du réseau. Nous pensons qu’avec AO, nous disposons désormais de la capacité de transférer cette intelligence du marché — celle qui conduit aux décisions — directement au sein du réseau lui-même. Une façon simple de comprendre cela serait d’imaginer :
Un fonds spéculatif ou une application de gestion de portefeuille en qui vous pouvez avoir confiance, capable d’exécuter un ensemble d’instructions intelligentes à l’intérieur du réseau, transférant ainsi la non-confiance du réseau au processus décisionnel. Cela signifie qu’un compte anonyme, par exemple Yolo 420 Trader Number One (un trader audacieux et imprudent), pourrait créer une nouvelle stratégie originale et la déployer sur le réseau, et que vous pourriez y investir sans avoir à lui faire réellement confiance.
Vous pouvez désormais construire des agents autonomes capables d’interagir avec de grands modèles statistiques. Et les grands modèles statistiques les plus courants sont précisément les grands modèles linguistiques, capables de traiter et de générer du texte. Cela signifie que vous pouvez intégrer ces modèles dans des contrats intelligents, comme partie d’une stratégie développée par quelqu’un ayant une idée innovante, et les exécuter intelligemment au sein du réseau.

Vous pouvez imaginer réaliser une analyse basique du sentiment. Par exemple, lire une actualité et décider qu’il est temps d’acheter ou de vendre tel dérivé. C’est le bon moment pour telle ou telle opération. Vous pouvez ainsi faire exécuter des décisions quasi humaines de manière non fiable. Ce n’est pas seulement théorique. Nous avons créé un mème coin intéressant appelé Llama Fed. L’idée est qu’il s’agit d’un simulateur de banque centrale, où un groupe de lamas est représenté par le modèle Llama 3.
Ces lamas incarnent à la fois des lamas et le président de la Réserve fédérale. Vous pouvez les approcher pour demander des jetons, et ils évaluent votre demande. Le modèle linguistique lui-même gère la politique monétaire, de manière entièrement autonome et sans confiance. Nous l’avons construit, mais nous ne pouvons pas le contrôler. Ils décident eux-mêmes qui reçoit des jetons et qui n’en reçoit pas. C’est une petite application très intéressante de cette technologie, qui, nous l’espérons, inspirera de nombreuses autres applications possibles dans l’écosystème.

Pour y parvenir, nous avons dû créer trois nouvelles capacités fondamentales pour AO, certaines au niveau du protocole de base, d’autres au niveau applicatif. Ces avancées ne sont pas seulement utiles pour l’exécution de grands modèles linguistiques, elles sont également plus largement passionnantes pour tous les développeurs AO. Je suis donc ravi de pouvoir vous les présenter aujourd’hui.
La première de ces nouvelles technologies est le support de WebAssembly 64 bits. Cela peut sembler un terme technique, mais je vais vous aider à en comprendre l’importance. Fondamentalement, le support de WebAssembly 64 bits permet aux développeurs de créer des applications utilisant plus de 4 Go de mémoire. Nous verrons plus tard les nouvelles limites, qui sont impressionnantes.

Si vous n’êtes pas développeur, imaginez qu’on vous demande d’écrire un livre, vous êtes enthousiaste, mais on vous dit que vous ne pouvez pas dépasser 100 pages. Pas plus, pas moins. Vous pouvez exprimer vos idées, mais pas naturellement ni normalement, car une contrainte externe vous oblige à adapter votre écriture.
Dans l’écosystème des contrats intelligents, cette limitation est encore plus stricte que 100 pages. Disons que cela ressemblait à construire sur une version précédente d’AO. Ethereum a une limite de 48 Ko de mémoire, ce qui revient à vous demander d’écrire un livre d’une seule phrase, en utilisant uniquement les 200 mots anglais les plus courants. Construire des applications vraiment passionnantes dans un tel système est extrêmement difficile.
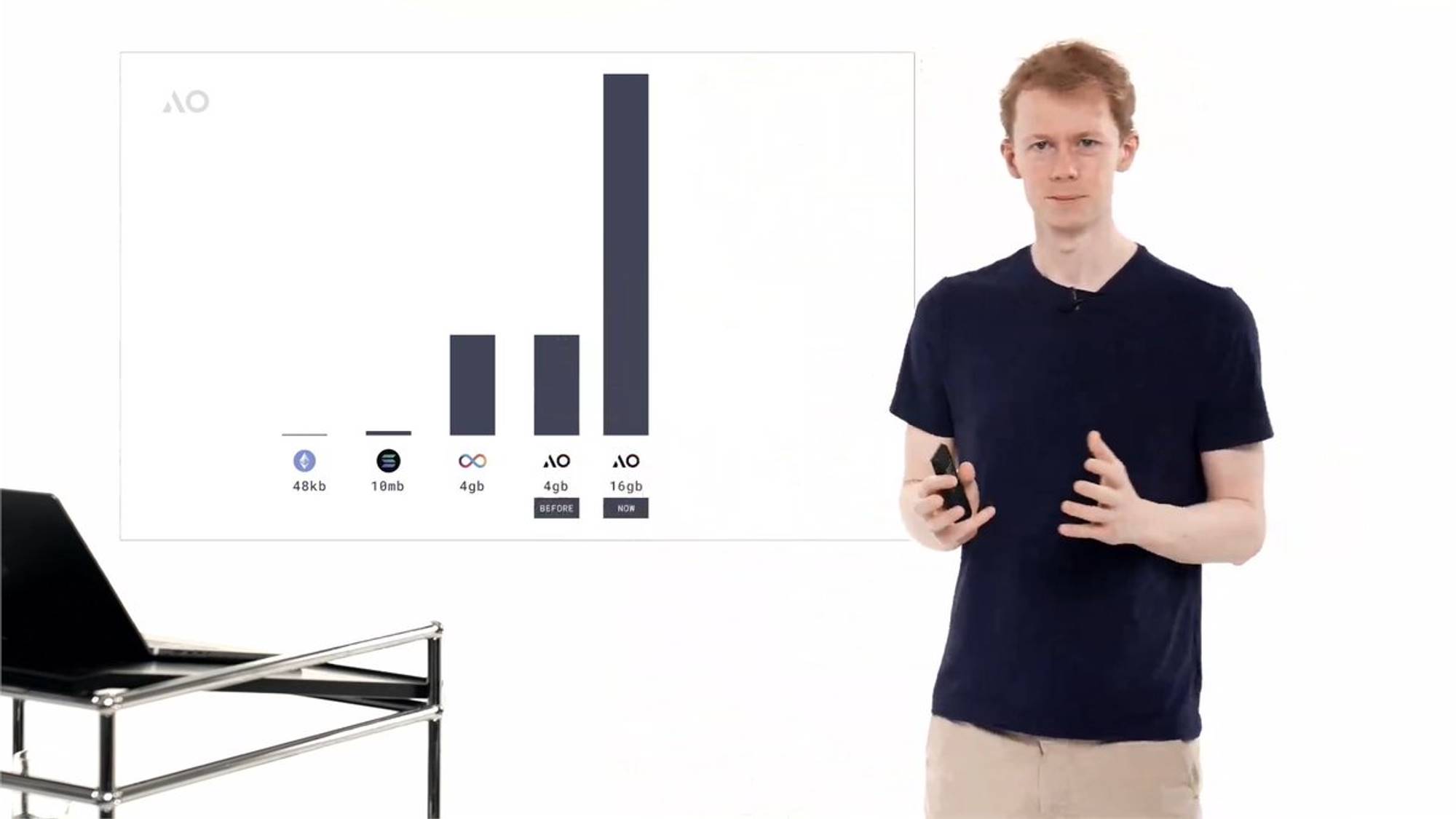
Puis vient Solana, qui offre 10 Mo de mémoire vive. C’est clairement une amélioration, mais cela correspond grosso modo à une page. ICP, le protocole Internet Computer, autorise jusqu’à 3 Go de mémoire. Théoriquement complet, mais ils ont dû limiter à 3 Go. Avec 3 Go, vous pouvez exécuter beaucoup d’applications différentes, mais certainement pas des applications IA de grande taille. Celles-ci doivent charger d’énormes volumes de données en mémoire principale pour un accès rapide, ce qui n’est pas efficace avec seulement 3 Go.
Lorsque nous avons lancé AO en février dernier, nous avions également une limite de 4 Go de mémoire, imposée par la version 32 bits de WebAssembly. Cette limitation a maintenant disparu au niveau du protocole. À la place, la limite de mémoire au niveau du protocole est désormais de 18 EB (exaoctets). C’est une quantité colossale de stockage.
Il faudra longtemps avant que cette mémoire soit utilisée pour le calcul plutôt que pour le stockage à long terme. Au niveau pratique, les unités de calcul du réseau AO peuvent désormais accéder à 16 Go de mémoire, et il sera relativement facile de passer à des capacités supérieures à l’avenir sans modifier le protocole. 16 Go suffisent déjà pour exécuter des calculs de grands modèles linguistiques, ce qui signifie que vous pouvez aujourd’hui télécharger et exécuter sur AO des modèles de 16 Go — comme Llama 3, Falcon non quantifié, et bien d’autres.
C’est un composant fondamental nécessaire pour construire un système informatique intelligent basé sur le langage. Maintenant, cela est entièrement pris en charge sur la chaîne comme partie intégrante d’un contrat intelligent, ce que nous trouvons extrêmement passionnant.
Cela supprime une des principales limitations computationnelles d’AO, et par extension de tous les systèmes de contrats intelligents. Lorsque nous avons lancé AO en février, vous avez pu remarquer que dans la vidéo, nous mentionnions à plusieurs reprises que vous aviez une puissance de calcul illimitée, avec une seule restriction : ne pas dépasser 4 Go de mémoire. Cette restriction est désormais levée. Nous considérons cela comme un progrès extraordinaire. 16 Go suffisent déjà pour exécuter presque tous les modèles que vous souhaiteriez utiliser dans le domaine actuel de l’IA.
Nous avons pu augmenter cette limite de 16 Go sans changer le protocole, et il sera relativement facile de l’augmenter davantage à l’avenir — une grande avancée comparée à la mise en œuvre initiale de WebAssembly 64. C’est donc en soi une progression énorme des capacités du système. La deuxième technologie majeure permettant aux grands modèles linguistiques de fonctionner sur AO est WeaveDrive.

WeaveDrive vous permet d’accéder aux données Arweave à l’intérieur d’AO comme s’il s’agissait d’un disque dur local. Cela signifie que vous pouvez ouvrir n’importe quel identifiant de transaction authentifié par une unité planifiée dans AO et téléchargé sur le réseau. Bien sûr, vous pouvez accéder à ces données et les charger dans votre programme comme un fichier sur un disque dur local.

Nous savons tous qu’Arweave stocke actuellement environ 6 milliards de transactions, ce qui constitue un ensemble de données massif dès le départ. Cela signifie aussi qu’à l’avenir, la motivation à télécharger des données sur Arweave augmentera, car celles-ci pourront aussi être utilisées dans les programmes AO. Par exemple, lorsque nous avons mis en place l’exécution des grands modèles linguistiques sur Arweave, nous avons téléchargé pour environ 1 000 dollars de modèles sur le réseau. Mais ce n’est qu’un début.
Avec un réseau de contrats intelligents doté d’un système de fichiers local, le nombre d’applications que vous pouvez construire est immense. C’est donc extrêmement passionnant. Mieux encore, le système que nous avons conçu vous permet de diffuser les données vers l’environnement d’exécution. C’est une subtilité technique, mais imaginez revenir à l’analogie du livre.
Quelqu’un vous dit : « J’aimerais accéder à une donnée dans votre livre. Je veux récupérer un graphique. » Dans un système simple, voire dans les réseaux actuels de contrats intelligents, vous donneriez tout le livre. Or, c’est manifestement inefficace, surtout si le livre est un grand modèle statistique de plusieurs milliers de pages.
C’est extrêmement inefficace. Ce que nous avons fait dans AO, c’est vous permettre de lire directement les octets. Vous allez directement à l’emplacement du graphique dans le livre, copiez uniquement le graphique dans votre application et l’exécutez. Cela rend le système extrêmement efficace. Ce n’est pas un MVP minimaliste, mais un mécanisme d’accès aux données complet et bien conçu. Vous disposez donc d’un système à calcul illimité et d’un disque dur illimité — combinés, ils forment un superordinateur.
Cela n’avait jamais été construit auparavant, et c’est désormais accessible à moindre coût pour chacun. C’est ce qu’est AO aujourd’hui, et nous en sommes très enthousiastes. Cette implémentation se situe également au niveau du système d’exploitation. Nous avons transformé WeaveDrive en un sous-protocole d’AO, une extension d’unité de calcul que n’importe qui peut charger. C’est intéressant, car c’est la première extension de ce type.
AO a toujours permis d’ajouter des extensions à l’environnement d’exécution. Comme si vous aviez un ordinateur et que vous vouliez insérer plus de mémoire ou une carte graphique — vous insérez physiquement une unité dans le système. Vous pouvez faire exactement cela avec les unités de calcul d’AO, et c’est ce que nous avons fait ici. Au niveau du système d’exploitation, vous avez désormais un disque dur, qui est simplement un système de fichiers représentant le stockage de données.
Cela signifie que non seulement vous pouvez accéder à ces données dans AO pour construire des applications classiques, mais que vous pouvez en fait y accéder depuis n’importe quelle application apportée au réseau. Il s’agit donc d’une capacité largement applicable, accessible à tous ceux qui construisent dans le système, peu importe le langage utilisé — Rust, C, Lua, Solidity, etc. — comme s’il s’agissait d’une fonctionnalité native du système. En concevant ce système, nous avons dû créer le protocole des sous-protocoles, une méthode permettant de créer d’autres extensions d’unités de calcul, afin que d’autres puissent à leur tour construire des choses passionnantes à l’avenir.
Maintenant que nous pouvons exécuter des calculs sur des ensembles de mémoire de taille arbitraire et charger des données du réseau dans des processus à l’intérieur d’AO, la question suivante est : comment effectuer le raisonnement lui-même ?
Étant donné que nous avons choisi de construire AO sur WebAssembly comme machine virtuelle principale, il est relativement facile de compiler et d’exécuter du code existant dans cet environnement. Grâce à WeaveDrive, qui expose un système de fichiers au niveau du système d’exploitation, exécuter Llama.cpp (un moteur open source d’inférence de grands modèles linguistiques) sur le système est en réalité assez simple.

C’est très excitant, car cela signifie que non seulement vous pouvez exécuter ce moteur d’inférence, mais aussi facilement de nombreux autres moteurs. Ainsi, le dernier composant permettant aux grands modèles linguistiques de fonctionner dans AO est le moteur d’inférence lui-même. Nous avons porté un système appelé Llama.cpp, qui peut sembler mystérieux, mais c’est en réalité l’environnement d’exécution open source le plus avancé actuellement pour les modèles.
Une fois que nous avons la capacité d’avoir une quantité arbitraire de données dans le système, puis de charger une quantité arbitraire de données depuis Arweave, il devient relativement facile de l’exécuter directement dans un contrat intelligent AO.
Pour y parvenir, nous avons également collaboré avec l’extension SIMD (Single Instruction, Multiple Data), qui permet d’exécuter ces modèles plus rapidement. Nous avons donc activé cette fonctionnalité également. Cela signifie que ces modèles fonctionnent actuellement sur CPU, mais à une vitesse assez élevée. Si vous avez des calculs asynchrones, cela conviendra bien à votre usage. Par exemple, lire un signal d’actualité puis décider quelles transactions exécuter fonctionne bien dans le système actuel. Mais nous avons aussi des mises à niveau passionnantes à venir concernant d’autres mécanismes d’accélération, comme l’utilisation de GPU pour accélérer l’inférence des grands modèles linguistiques.

Llama.cpp vous permet de charger non seulement le modèle phare de Meta, Llama 3, mais aussi de nombreux autres modèles. En fait, plus de 90 % des modèles que vous pouvez télécharger depuis Hugging Face, site open source de modèles, peuvent fonctionner dans le système — de GPT-2, si vous le souhaitez, à 253, Monet, le propre système de grands modèles linguistiques d’Apple, et bien d’autres. Nous avons donc désormais un cadre permettant de télécharger n’importe quel modèle depuis Arweave, de l’uploader via le disque dur, comme un modèle que je veux exécuter dans le système. Vous les téléchargez, ce sont des données normales, puis vous les chargez dans les processus AO, vous exécutez, obtenez les résultats et travaillez dessus comme vous le souhaitez. Nous pensons que c’est un package complet qui rend possibles des applications impossibles dans les écosystèmes précédents de contrats intelligents — même si elles étaient envisageables, les changements architecturaux requis dans des systèmes comme Solana seraient inimaginables, et ne figurent pas sur leur feuille de route. Pour illustrer cela et le rendre tangible, nous avons créé un simulateur appelé Llama Fed. L’idée est d’avoir un comité de membres de la Réserve fédérale, des lamas, qui sont des lamas à la fois comme métaphore de Llama 3 et comme présidents de la Réserve fédérale.
Nous leur disons aussi qu’ils sont des lamas, comme Alan Greenspan ou le président de la Réserve fédérale. Vous pouvez entrer dans cet environnement.
Certains d’entre vous connaissent cet environnement, c’est en fait similaire à Gather, où nous travaillons aujourd’hui. Vous pouvez parler aux lamas, leur demander des jetons pour un projet intéressant, et ils décident, selon votre demande, si vous recevez ou non des jetons. Vous brûlez donc quelques jetons Arweave, des jetons wAR (fournis par l’équipe AOX), et ils vous accordent des jetons selon la qualité de votre proposition. C’est donc un mème coin dont la politique monétaire est entièrement autonome et intelligente. Bien que cette intelligence soit simple, elle reste intéressante. Elle évaluera votre proposition et celles des autres, et gérera la politique monétaire. Analyser des titres d’actualité, prendre des décisions intelligentes ou interagir avec un service client pour renvoyer de la valeur — tout cela peut désormais être réalisé à l’intérieur d’un contrat intelligent. Elliot va maintenant vous le montrer.

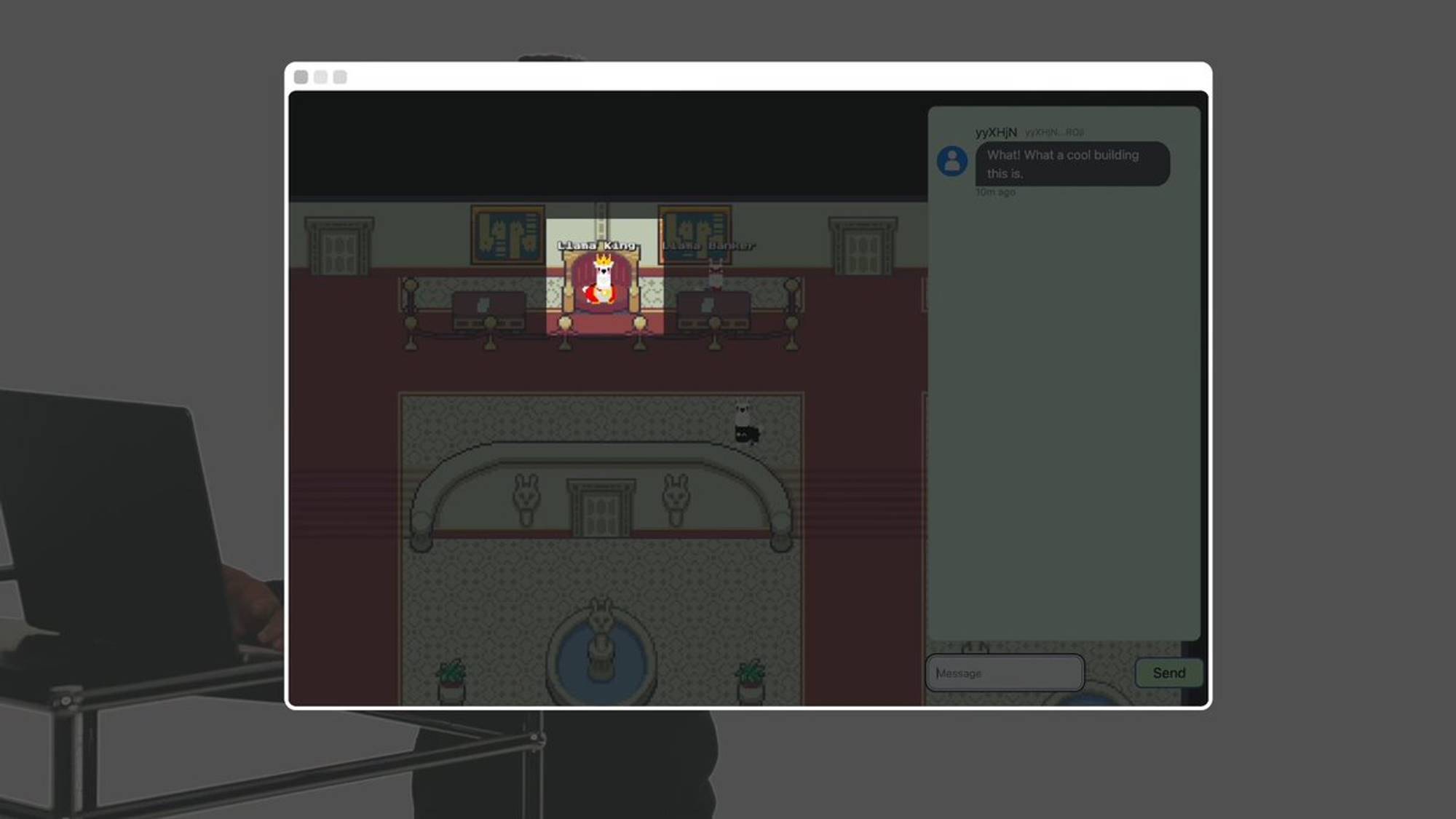
Bonjour, je suis Elliot. Aujourd’hui, je vais vous présenter Llama Land, un monde autonome fonctionnant sur la chaîne à l’intérieur d’AO, piloté par le modèle open source Llama 3 de Meta.
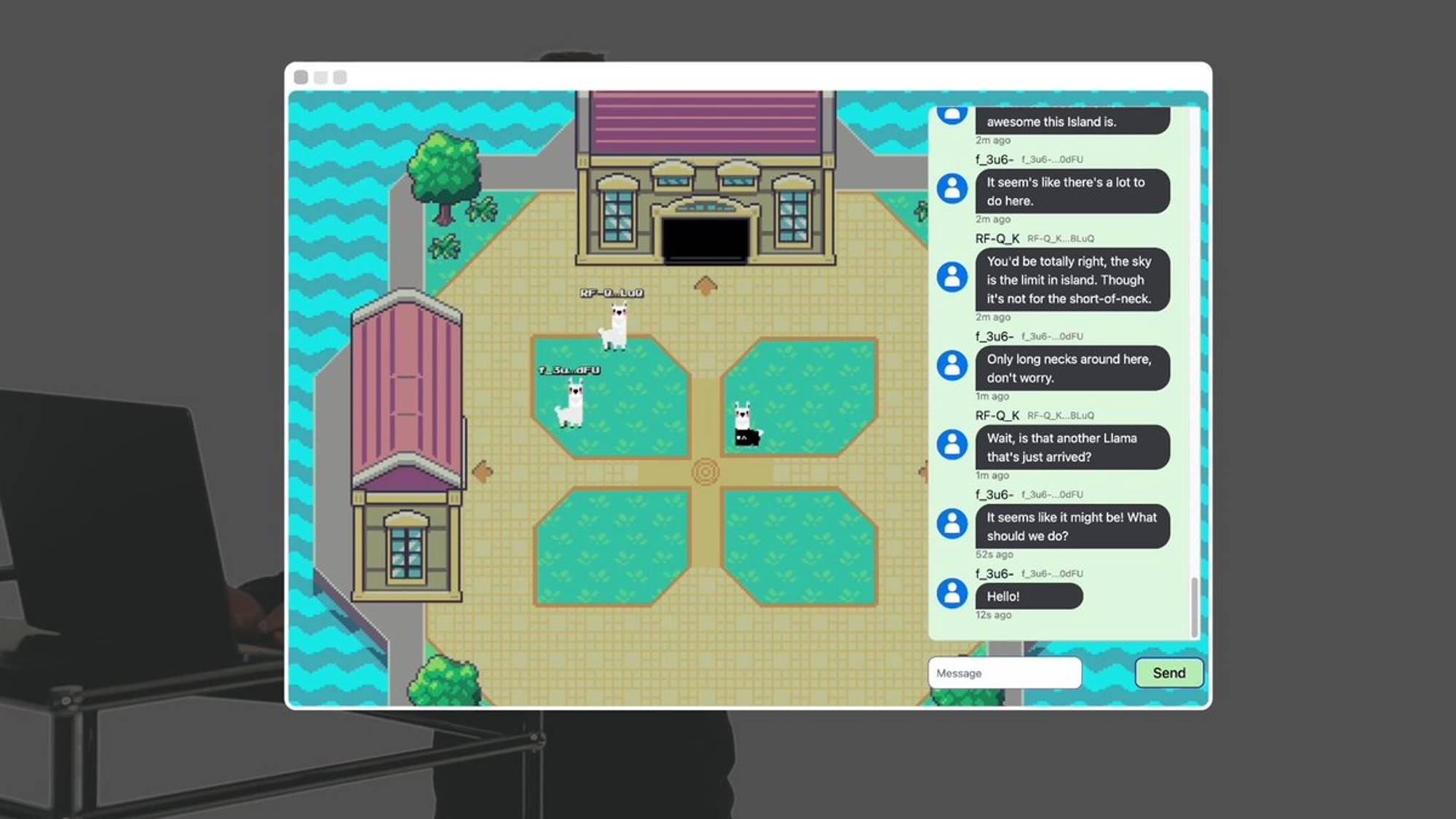
Les conversations que vous voyez ici ne sont pas seulement entre joueurs, mais incluent aussi des lamas numériques entièrement autonomes.
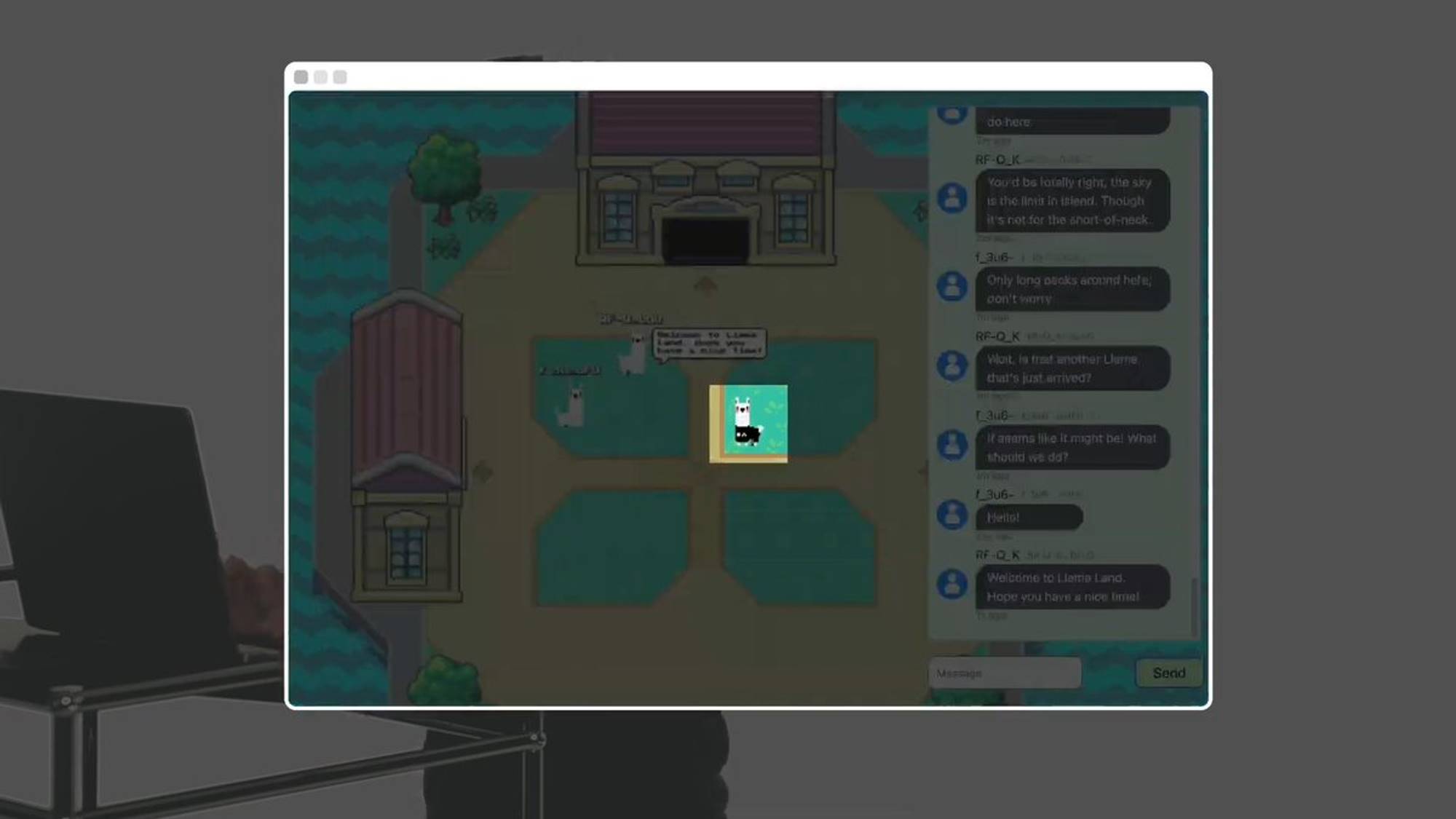
Par exemple, ce lama est un humain.
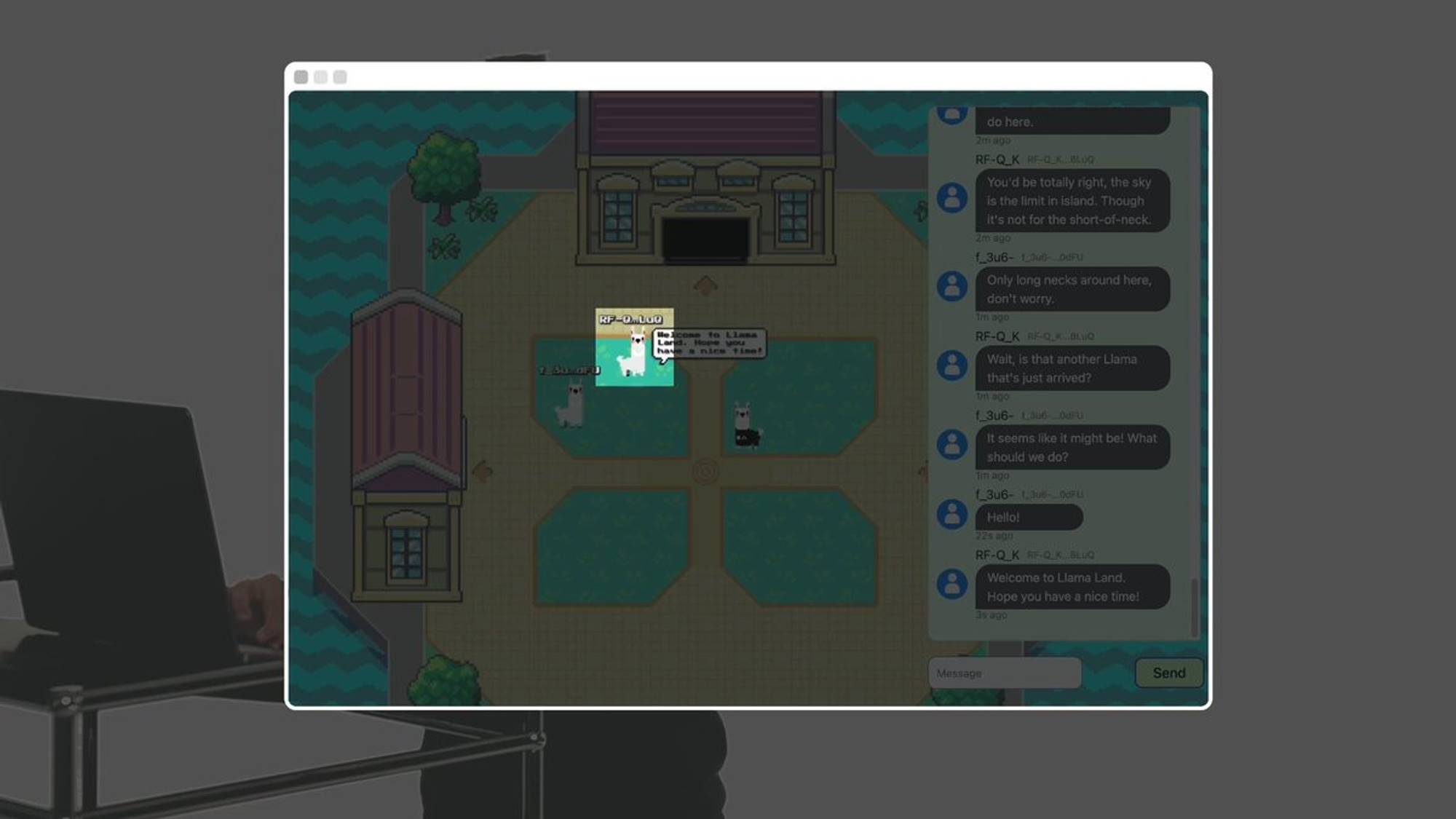
Mais ce lama est une IA sur la chaîne.
Ce bâtiment contient Llama Fed. C’est comme la Réserve fédérale, mais pour les lamas.
Llama Fed gère la première politique monétaire pilotée par une IA au monde, et émet des jetons Llama.
Ce personnage est le roi Llama. Vous pouvez lui proposer des jetons Arweave emballés (wAR) et écrire une demande pour obtenir quelques jetons Llama.
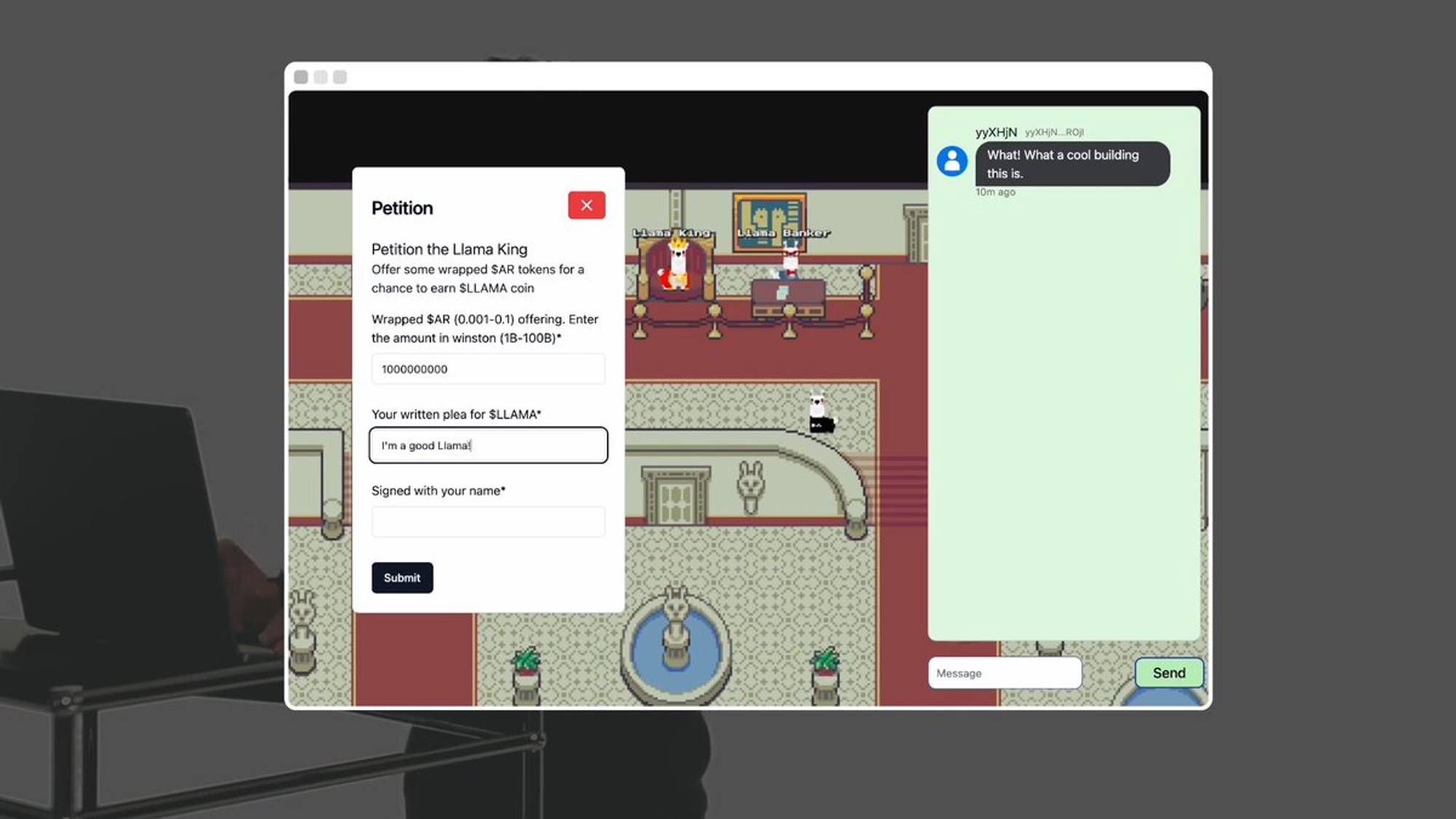
L’IA du roi Llama évaluera la demande et décidera d’accorder ou non les jetons. La politique monétaire de Llamafed est entièrement autonome, sans supervision humaine. Chaque agent et chaque pièce du monde sont des processus sur la chaîne sur AO.
On dirait que le roi Llama nous a accordé quelques jetons. Si je regarde mon portefeuille ArConnect, je peux voir qu’ils sont déjà là. Excellent. Llama Land est seulement le premier monde piloté par l’IA mis en œuvre sur AO. C’est un cadre pour un nouveau protocole permettant à n’importe qui de construire son propre monde autonome — la seule limite est votre imagination. Tout cela est 100 % sur la chaîne, et seulement possible sur AO.

Merci Elliot. Ce que vous venez de voir, ce n’est pas seulement un grand modèle linguistique participant à des décisions financières et gérant un système autonome de politique monétaire. Il n’y a pas de porte dérobée, nous ne pouvons pas le contrôler, tout est géré par l’IA elle-même. Vous avez aussi vu un petit univers, un endroit où vous pouvez vous déplacer dans un espace physique, aller à un endroit spécifique pour interagir avec une infrastructure financière. Nous pensons que ce n’est pas seulement une petite démonstration amusante.
Il y a en réalité quelque chose de très intéressant ici : rassembler dans un même lieu les personnes utilisant différents produits financiers. Dans l’écosystème DeFi, nous observons que si quelqu’un veut participer à un projet, il commence par regarder sur Twitter, visite le site web, participe aux éléments de base du jeu. Puis il rejoint un groupe Telegram, un salon Discord ou discute avec d’autres utilisateurs sur Twitter. Cette expérience est très fragmentée, nous passons constamment d’une application à l’autre.

Nous explorons une idée intéressante : si les interfaces utilisateur des applications DeFi permettaient à leurs communautés de se rassembler et de gérer collectivement un espace autonome permanent auquel ils accèdent ensemble, intégré à l’expérience.
Imaginez pouvoir aller dans un lieu qui ressemble à une salle des ventes, discuter avec d’autres utilisateurs qui aiment ce protocole. Lorsqu’un mécanisme financier se produit sur AO, vous pouvez discuter avec d’autres utilisateurs. La communauté et l’aspect social sont intégrés à la composante financière du produit.
Nous trouvons cela très intéressant, voire aux implications plus larges. Vous pouvez ici construire un agent IA autonome qui erre dans ce monde Arweave, interagit avec différentes applications et utilisateurs. Donc, si vous construisez un métavers, lorsque vous créez un jeu en ligne, la première chose est de créer des PNJ (personnages non-joueurs). Ici, les PNJ peuvent être généraux.
Vous avez un système intelligent qui erre, interagit avec l’environnement. Ainsi, vous n’avez pas de problème de démarrage à froid. Vous pouvez avoir des agents autonomes qui tentent de gagner de l’argent, de se faire des amis, d’interagir avec l’environnement comme de vrais utilisateurs DeFi. Nous trouvons cela très intéressant, même si un peu étrange. Voyons ce que cela donne.
À l’avenir, nous voyons aussi des opportunités d’accélérer l’exécution des grands modèles linguistiques dans AO. J’ai mentionné plus tôt le concept d’extensions d’unité de calcul. C’est ainsi que nous avons construit WeaveDrive.

Ce n’est pas limité à WeaveDrive : vous pouvez construire n’importe quel type d’extension pour l’environnement de calcul AO. Un projet écologique très prometteur, Apus Network, travaille justement à accélérer l’exécution des grands modèles linguistiques via GPU. Je leur laisse la parole.

Salut, je suis Mateo. Aujourd’hui, je suis ravi de présenter Apus Network. Apus Network s’efforce de construire un réseau GPU décentralisé et non fiable.
Nous tirons parti du stockage permanent sur la chaîne d’Arweave, fournissons un module d’extension open source pour AO, créons un environnement d’exécution déterministe pour GPU, et proposons un modèle d’incitation économique pour l’IA décentralisée, utilisant les jetons AO et APUS. Apus Network utilisera des nœuds miniers GPU qui exécuteront de manière concurrentielle l’entraînement optimal et non fiable de modèles sur Arweave et AO. Cela garantit que les utilisateurs peuvent utiliser les meilleurs modèles d’IA au prix le plus compétitif. Suivez nos avancées sur X (Twitter) @apus_network. Merci.

Voilà où en est l’IA sur AO aujourd’hui. Allez essayer Llama Fed, essayez de construire vos propres applications de contrats intelligents basées sur de grands modèles linguistiques. Nous pensons que c’est le début de l’intégration de l’intelligence du marché dans un environnement d’exécution décentralisé. Nous sommes très enthousiastes, et impatients de voir ce qui va suivre. Merci à tous d’être venus aujourd’hui, hâte de vous revoir bientôt.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













