

Dragonfly Partner: "Don't Trust, Verify" Applied to Decentralized Inference
TechFlow Selected TechFlow Selected
Dragonfly Partner: "Don't Trust, Verify" Applied to Decentralized Inference
Blockchain and machine learning clearly have a lot in common.
Author: Haseeb Qureshi
Translation: TechFlow
You want to run a large language model like Llama2–70B. A model this large requires over 140GB of memory, meaning you can't run the original model on your home computer. So what are your options? You might turn to cloud service providers, but you may be reluctant to trust a single centralized company to handle this workload for you and collect all your usage data. What you need is decentralized inference—enabling you to run machine learning models without relying on any single provider.
The Trust Problem
In a decentralized network, simply running a model and trusting its output isn't enough. Suppose I ask the network to analyze a governance dilemma using Llama2–70B—how do I know it didn’t actually use Llama2-13B, giving me worse analysis while pocketing the difference?
In the centralized world, you might trust a company like OpenAI because their reputation is at stake (and to some extent, the quality of LLMs is self-evident). But in a decentralized world, honesty isn’t assumed—it must be verified.
This is where verifiable inference comes in. In addition to providing a response to a query, you also prove that it was correctly executed on the requested model. But how?
The simplest approach would be to run the model as a smart contract on-chain. This would certainly guarantee verified outputs, but it's extremely impractical. GPT-3 represents words with an embedding dimension of 12,288. Performing a single matrix multiplication of this size on-chain would cost approximately $10 billion at current gas prices and fill every block for about a month.
So we need a different approach.
After observing this space, I see three main approaches emerging for verifiable inference: zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomics. Each has distinct trade-offs in terms of security and cost.
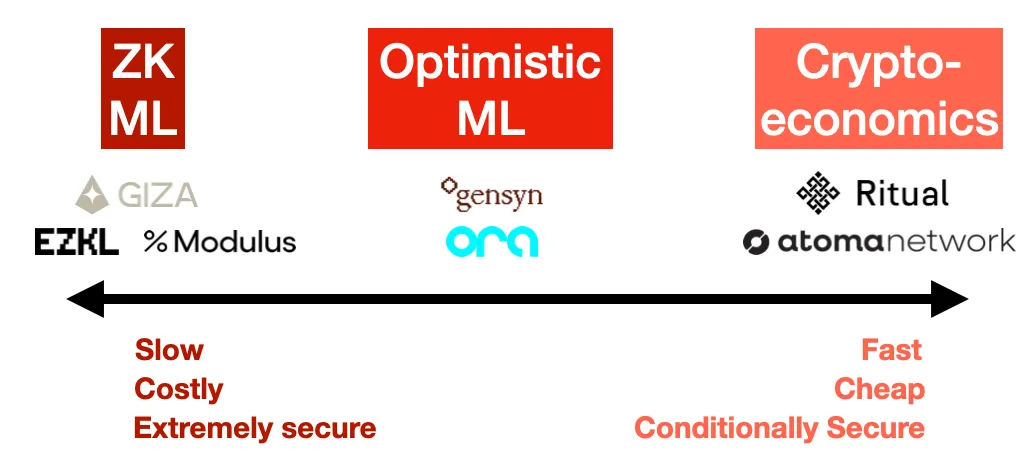
1. Zero-Knowledge Proofs (ZK ML)
Imagine being able to prove you ran a large model, yet the proof size remains fixed regardless of the model’s scale. This is the promise of ZK ML (machine learning), achieved via ZK-SNARKs.
While elegant in theory, compiling a deep neural network into a zero-knowledge circuit and then generating a proof is extremely difficult—and prohibitively expensive. At minimum, you could expect inference costs to increase by 1,000x and latency by 1,000x (due to proof generation time), not to mention the initial effort of compiling the model itself into a circuit. Ultimately, these costs get passed on to users, making it very expensive for end users.
On the other hand, this is the only method offering cryptographic guarantees of correctness. With ZK, no matter how hard a model provider tries, they cannot cheat. But the cost makes this impractical for large models in the foreseeable future.
Examples: EZKL, Modulus Labs, Giza
2. Optimistic Fraud Proofs (Optimistic ML)
The optimistic approach is: trust, but verify. We assume inference is correct unless proven otherwise. If a node attempts to cheat, “watchers” in the network can identify the cheater and challenge them with a fraud proof. These watchers must constantly monitor the chain and re-run the model themselves to ensure correctness.
These fraud proofs follow Truebit-style interactive challenges—a game of responses where the model execution trace is repeatedly bisected on-chain until the error is isolated.
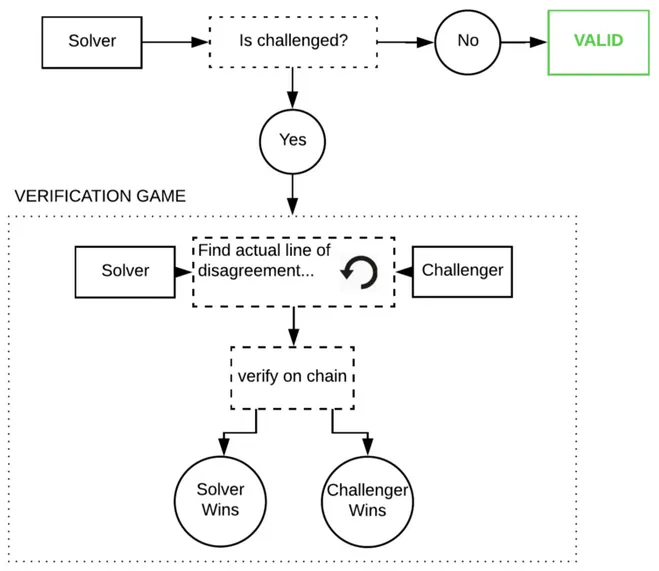
If this actually happens, it would be extremely expensive—the programs are massive with huge internal states, and a single GPT-3 inference costs about 1 petaflop (10⁵ floating-point operations). However, game theory suggests this is highly unlikely (fraud proofs are also notoriously difficult to implement correctly, since the code path is rarely exercised in production).
The benefit of optimism is that ML is secure as long as there’s one honest watcher. It’s cheaper than ZK ML, but keep in mind that each watcher re-runs every query. In equilibrium, if there are 10 watchers, the security cost is passed to users, who must pay over 10x the base inference cost (or however many watchers exist).
The downside is, like optimistic rollups, you must wait out a challenge period before considering a response verified. Depending on network parameters, this could be minutes rather than days.
3. Cryptoeconomic ML
Here, we drop all fancy techniques and do something simple: stake-weighted voting. Users decide how many nodes should run their query. Each reveals their response, and if there’s disagreement, the outlier nodes get slashed. It’s a standard oracle mechanism—a straightforward way for users to set their desired security level, balancing cost and trust. If Chainlink were doing ML, this is how they’d do it.
Latency here is low—you only need commit-and-reveal phases from each node. If written to the blockchain, this could technically happen in just two blocks.
However, security is weakest. If most nodes collude, they can rationally choose to cheat. As a user, you must consider how much stake is at risk and how costly cheating would be. That said, with mechanisms like Eigenlayer’s restaking and attributable security, networks can offer effective insurance in case of security failure.
The advantage of this system is user-configurable security. Users can choose a quorum of 3, 5, or even every node in the network. Or, if feeling risky, they could even go with n=1. The cost function is simple: users pay per node in their chosen quorum. Pick 3, pay 3x inference cost.
The tricky question: can n=1 ever be secure? In a naive setup, an isolated node would always cheat if unmonitored. But I suspect that if queries are encrypted and payments are intent-based, you might hide from the node whether it’s the sole responder. In such cases, you might charge regular users less than 2x inference cost.
Ultimately, the cryptoeconomic approach is the simplest, easiest, and likely cheapest—but theoretically, it’s the least elegant and least secure. As always, details matter.
Examples: Ritual, Atoma Network
Why Verifiable ML Is Hard
You might wonder why we don’t already have all this. After all, ML models are just very large computer programs. Proving correct program execution is core to blockchains.
That’s why these three verification methods mirror how blockchains protect their blockspace: ZK rollups use ZK proofs, optimistic rollups use fraud proofs, and most L1 blockchains use cryptoeconomics. Unsurprisingly, we arrive at essentially the same solutions. So why is applying them to ML so hard?
ML is unique because ML computations are typically represented as dense computational graphs optimized for efficient GPU execution—not designed for provability. Therefore, proving ML computations in ZK or optimistic environments requires recompiling them into a verifiable format, which is complex and expensive.
A second fundamental difficulty with machine learning is nondeterminism. Program verification assumes deterministic outputs. But running the same model on different GPU architectures or CUDA versions can yield different results. Even with identical hardware, randomness in algorithms (e.g., noise in diffusion models or token sampling in LLMs) introduces variability. You can fix this by controlling random seeds. Yet one last nagging issue remains: inherent nondeterminism in floating-point arithmetic.
Almost all GPU operations use floating-point numbers. Floating-point math is tricky because it’s not associative—that is, (a + b) + c does not always equal a + (b + c). Due to GPU parallelization, the order of additions or multiplications may vary across executions, leading to small output differences. This likely won’t affect LLM outputs due to the discrete nature of tokens, but for image models, it could cause subtle pixel variations, preventing perfect output matching.
This means you either avoid floating-point numbers entirely—causing severe performance penalties—or allow some flexibility when comparing outputs. Either way, the details are messy and can’t be fully abstracted away. (This is why the Ethereum Virtual Machine doesn’t support floating-point operations, though some blockchains like NEAR do.)
In short, decentralized inference networks are hard because every detail matters—and real-world details are surprisingly numerous.
Conclusion
Currently, blockchains and machine learning have much in common—one creates technology for trust, the other desperately needs it. While each approach to decentralized inference involves trade-offs, I’m excited to see how entrepreneurs leverage these tools to build the best possible networks.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













