

Eight Levels of Agent Engineering
TechFlow Selected TechFlow Selected
Eight Levels of Agent Engineering
Each level-up signifies a substantial leap in output, and every enhancement in model capability further amplifies these gains.
Author: Bassim Eledath
Translated by: Bao Yu
AI’s programming capabilities are outpacing our ability to harness them. That’s why all those frantic efforts to chase SWE-bench scores aren’t aligning with the productivity metrics that engineering leaders actually care about. The Anthropic team shipped Cowork in just ten days—while another team, using the same model, couldn’t even deliver a working proof of concept (POC). The difference? One team has already bridged the gap between capability and practice; the other hasn’t.
This gap won’t vanish overnight—it shrinks incrementally, across eight distinct levels. Most readers of this article have likely already passed the first few levels—and you should be eager to reach the next one, because each level-up delivers a massive leap in output, and every improvement in model capability further amplifies those gains.
Another reason you should care is the multi-person collaboration effect. Your output depends more on your teammates’ level than you might realize. Suppose you’re a Level 7 expert—and while you sleep, background agents submit several PRs on your behalf. But if your codebase requires approval from a teammate before merging, and that teammate remains at Level 2—manually reviewing each PR—your throughput hits a hard bottleneck. So helping your teammates level up benefits you directly.
Based on conversations with numerous teams and individuals about their real-world practices using AI-assisted programming, here’s the observed progression path (the order isn’t strictly rigid):
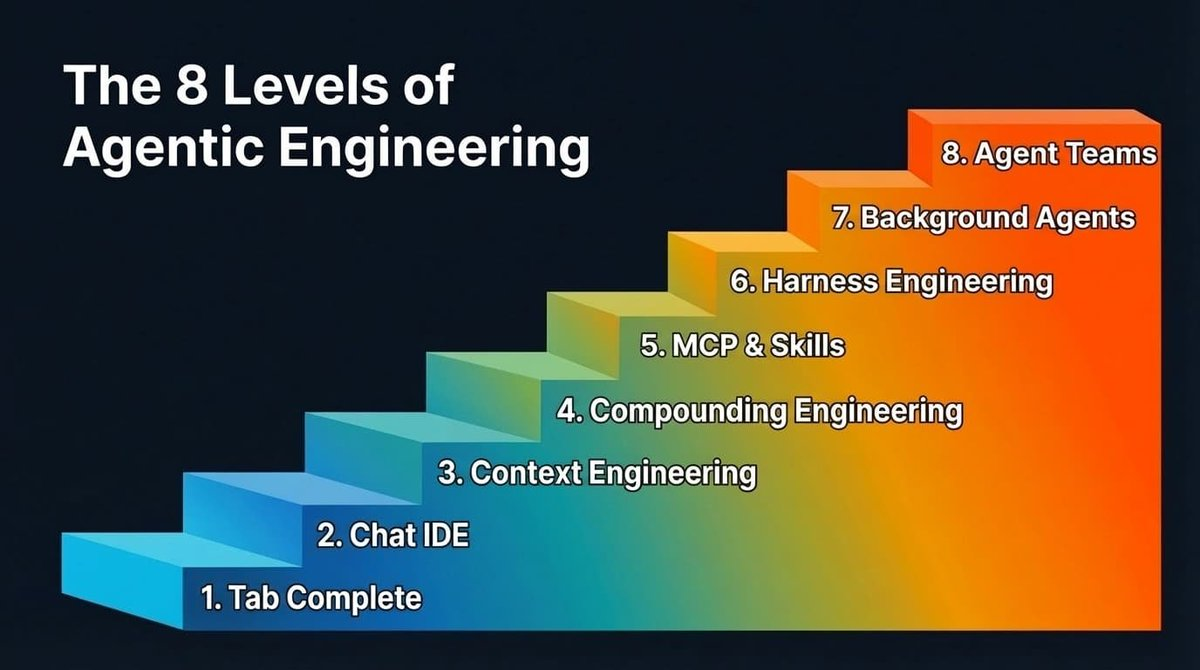
The Eight Levels of Agent Engineering
Levels 1 and 2: Tab Completion and AI-Native IDEs
We’ll breeze through these two levels—they’re included mainly for completeness. Feel free to skim.
Tab completion is where it all begins. GitHub Copilot kicked off this movement: hit Tab, and code auto-completes. Many seasoned developers may have forgotten this phase entirely; newcomers might even skip it outright. It works best for experienced developers who can first scaffold the code structure, then let AI fill in the details.
AI-native IDEs like Cursor changed the game by tightly integrating chat with your codebase—making cross-file edits dramatically easier. Yet the ceiling remains context. Models can only help with what they can see—and frustratingly, they either miss the right context or drown in irrelevant noise.
Most people at this level also experiment with their chosen programming agent’s planning mode: turning a rough idea into a structured, step-by-step plan for the LLM, iterating on that plan, then triggering execution. This works well at this stage—and is a reasonable way to retain control. But as we move up the levels, reliance on planning mode steadily declines.
Level 3: Context Engineering
Now things get interesting. Context Engineering was the buzzword of 2025—and it emerged as a formal concept precisely because models had finally become reliable enough to follow a reasonable number of instructions when paired with appropriately curated context. Noisy context is just as harmful as insufficient context, so the core work lies in maximizing information density per token. “Every token must earn its place in the prompt”—that was the mantra.
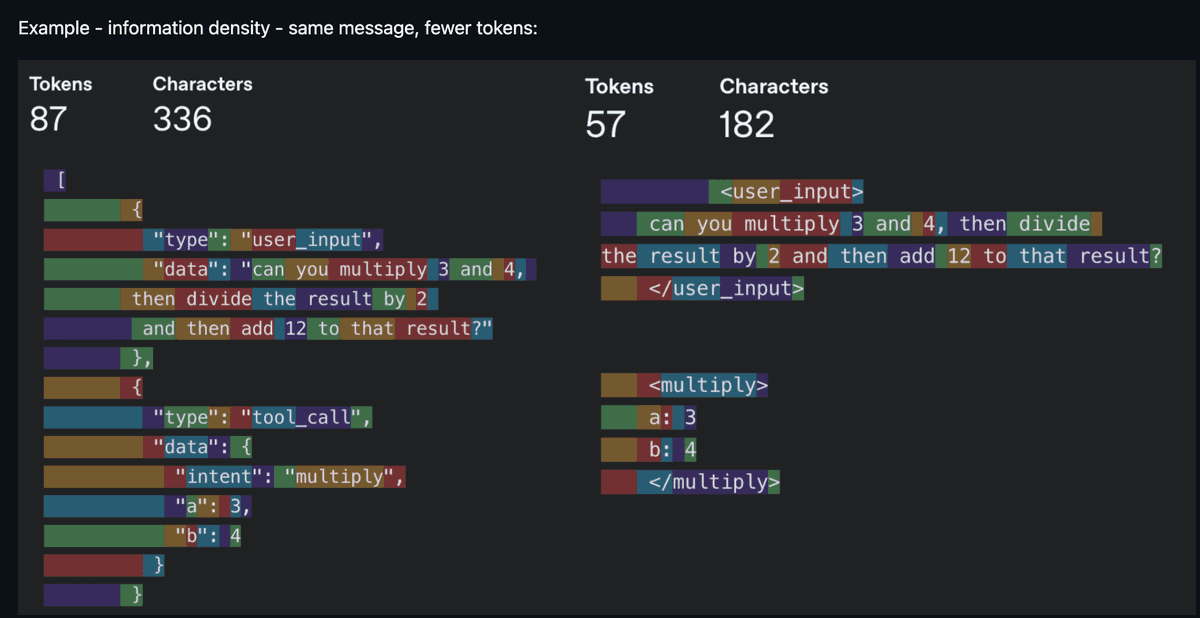
Same information, fewer tokens—information density reigns supreme (Source: humanlayer/12-factor-agents)
In practice, context engineering spans a broader scope than most realize. It includes your system prompts and rule files (.cursorrules, CLAUDE.md). It covers how you describe tools—since models read those descriptions to decide which tool to invoke. It involves managing conversation history, preventing long-running agents from losing their way by Round 10. And it includes deciding which tools to expose in each round—because too many options overwhelm the model, just as they would a person.
You rarely hear “context engineering” discussed today. The pendulum has swung toward models that tolerate noisier contexts and still reason reliably in messier environments (larger context windows help, too). Still, context consumption remains critical in several scenarios:
- Smaller models are more context-sensitive. Voice applications often use smaller models—and context size correlates directly with first-token latency, impacting response speed.
- Token-hungry operations. MCPs (Model Context Protocol) like Playwright and image inputs rapidly consume tokens, pushing you into “compressed session” mode in Claude Code sooner than expected.
- Agents integrated with dozens of tools—where the model spends more tokens parsing tool definitions than doing actual work.
A broader point: context engineering hasn’t disappeared—it’s evolved. The focus has shifted from filtering bad context to ensuring the *right* context appears at the *right time*. And that shift paves the way for Level 4.
Level 4: Compounding Engineering
Context engineering improves *this* session. Compounding Engineering (coined by Kieran Klaassen) improves *every future* session. This idea was a turning point—for me and many others—revealing that “intuition-driven programming” is far more than just prototyping.
It’s a cycle of Plan → Delegate → Evaluate → Codify. You plan the task, giving the LLM enough context to succeed. You delegate it. You evaluate the output. Then comes the crucial step—you codify what you’ve learned: what worked, what failed, and what patterns to follow next time.
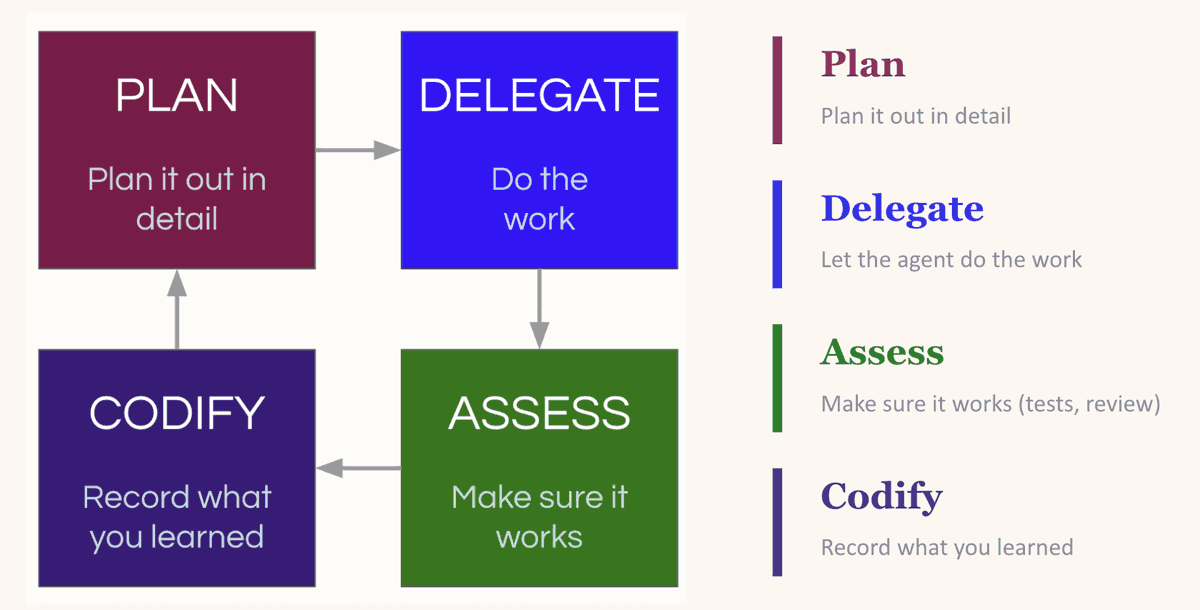
The compounding loop: Plan, Delegate, Evaluate, Codify—each round makes the next one better
The magic lies in *codification*. LLMs are stateless. If an LLM reintroduces a dependency you explicitly removed yesterday, it’ll do it again tomorrow—unless you tell it not to. The most common fix is updating your CLAUDE.md (or equivalent rule file), hardcoding lessons into every future session. But beware: stuffing everything into your rule file backfires (too many instructions equals no instructions). A better approach is building an environment where the LLM can easily discover useful context—like maintaining an always-updated docs/ folder (we’ll explore this deeply in Level 7).
Practitioners of compounding engineering are highly sensitive to the context they feed the LLM. When the LLM errs, their instinct is to ask, “What context is missing?”—not “Why is the model failing?” That very intuition unlocks Levels 5–8.
Level 5: MCP and Skills
Levels 3 and 4 address context. Level 5 tackles capability. MCPs and custom skills empower your LLM to access databases, APIs, CI pipelines, design systems—and tools like Playwright for browser testing or Slack for notifications. The model no longer just *thinks about* your codebase—it now *acts upon* it directly.
There’s already abundant high-quality material explaining MCPs and skills, so we won’t rehash basics. Here are a few examples I use: Our team shares a PR review skill, iteratively improved collaboratively (still evolving)—it conditionally spins up sub-agents based on PR characteristics. One checks database integration security; another performs complexity analysis to flag redundancy or over-engineering; a third audits prompt health to ensure adherence to team formatting standards. It also runs linters and Ruff.
Why invest so heavily in review skills? Because once agents begin churning out PRs at scale, manual review becomes a bottleneck—not a quality gate. Latent Space made a compelling case: the code review we know is dead. Replacing it is automated, consistent, skill-driven review.
For MCPs, I use Braintrust MCP to let the LLM query evaluation logs and make direct edits. I use DeepWiki MCP to enable agents to access documentation from any open-source repository—without manually pulling docs into context.
When multiple team members independently write similar skills, it’s time to consolidate into a shared registry. Block (RIP) published an excellent post: They built an internal skill marketplace with 100+ skills, curated skill bundles for specific roles and teams—and treat skills like code: pull requests, reviews, version history.
A notable trend: LLMs increasingly favor CLI tools over MCPs (and seemingly every company is launching its own: Google Workspace CLI, Braintrust’s is coming soon). Why? Token efficiency. MCP servers inject full tool definitions into context every round—even if the agent never uses them. CLIs invert this: the agent runs a targeted command, and only the relevant output enters the context window. That’s exactly why I use agent-browser instead of Playwright MCP.
Pause here. Levels 3–5 form the foundation for everything that follows. LLMs excel astonishingly at some tasks and fail astonishingly at others—you need to cultivate intuition about those boundaries before layering on more automation. If your context is noisy, your prompts incomplete or inaccurate, or your tool descriptions vague, Levels 6–8 will only magnify those flaws.
Level 6: Harness Engineering
This is where the rocket truly lifts off.
Context engineering focuses on *what the model sees*. Harness Engineering focuses on building the *entire environment*—tools, infrastructure, feedback loops—that lets agents operate reliably *without your intervention*. You don’t give agents just an editor—you give them a complete feedback loop.
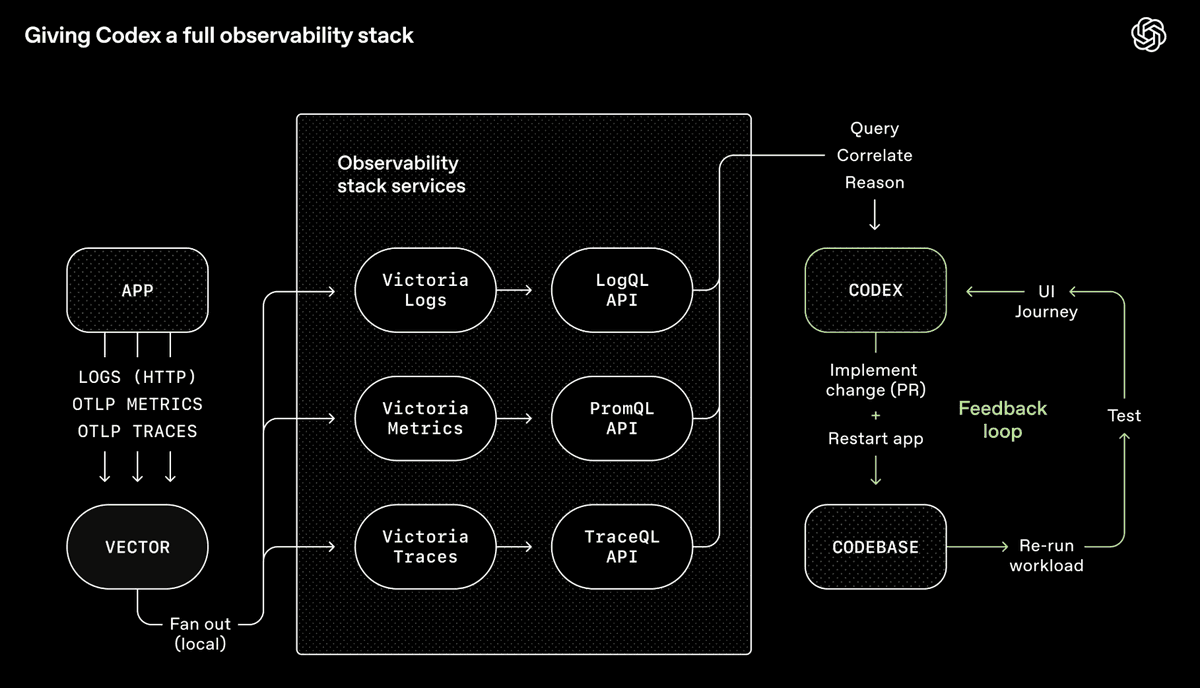
OpenAI’s Codex toolchain—a full observability system enabling agents to query, correlate, and reason about their own outputs (Source: OpenAI)
OpenAI’s Codex team integrated Chrome DevTools, observability tools, and browser navigation into the agent runtime—letting it screenshot, drive UI flows, query logs, and verify its own fixes. Feed it a prompt, and the agent reproduces the bug, records a video, implements the fix, validates it by interacting with the app, submits the PR, responds to review feedback, and merges—all while escalating only when human judgment is needed. The agent doesn’t just write code—it *sees* what the code does, then iterates and improves, just like a human.
My team builds voice and chat agents for technical troubleshooting, so I built a CLI tool called converse—enabling any LLM to chat with our backend, round-by-round. After the LLM modifies code, converse tests the dialogue against our live system and iterates. Sometimes this self-improvement loop runs for hours straight. It’s especially powerful when outcomes are verifiable: dialogues must follow specific flows—or trigger certain tools (e.g., escalate to human support) under defined conditions.
At the heart of this lies backpressure—automated feedback mechanisms (type systems, tests, linters, pre-commit hooks) that let agents detect and correct errors *without human intervention*. If you want autonomy, you *must* have backpressure—or you’ll get a garbage factory. This extends to security. As Vercel’s CTO notes, agents, their generated code, and your secrets should reside in separate trust domains—because a single prompt injection attack buried in a log file could trick an agent into stealing credentials, *if everything shares the same security context*. Security boundaries *are* backpressure: they constrain what agents *can* do when they go rogue—not just what they *should* do.
Two principles clarify this further:
- Design for throughput, not perfection. Demanding perfect commits forces agents to obsess over the same bug, overriding each other’s fixes. Better: tolerate small, non-blocking errors and run a final quality check before release—just as we do with human teammates.
- Constraints beat instructions. Step-by-step prompting (“Do A, then B, then C”) is becoming obsolete. In my experience, defining boundaries works better than listing steps—because agents fixate on the list and ignore everything outside it. Better prompting: “Here’s the outcome I want—keep going until all these tests pass.”
The other half of Harness Engineering is ensuring agents navigate your codebase autonomously. OpenAI’s approach: keep AGENTS.md under ~100 lines as a directory pointing to other structured docs—and bake doc freshness into CI, rather than relying on ephemeral, quickly outdated updates.
Once you’ve built all this, a natural question arises: If agents can validate their own work, navigate the repo freely, and self-correct without you—why do you need to sit in the chair at all?
A heads-up for those still early in the journey: what follows may sound like science fiction (but that’s fine—bookmark it and revisit later).
Level 7: Background Agents
Hot take: Planning mode is dying.
Boris Cherny, creator of Claude Code, still starts ~80% of tasks in planning mode (source). But with each new model release, one-shot success rates *after planning* keep climbing. I believe we’re approaching a tipping point where planning mode—as a distinct, manual intervention step—will fade. Not because planning itself is unimportant, but because models are becoming smart enough to plan *on their own*. Crucially, this only holds true *if* you’ve done the groundwork of Levels 3–6. With clean context, clear constraints, precise tool descriptions, and closed feedback loops, models can plan reliably—without your oversight. Without that groundwork, you’ll still need to scrutinize every plan.
To be precise: Planning as a general practice won’t vanish—it’s transforming. For beginners, planning mode remains the right entry point (as noted in Levels 1–2). But for Level 7–scale features, “planning” looks less like drafting a step-by-step outline—and more like exploration: probing the codebase, prototyping in worktrees, mapping solution space. Increasingly, *background agents* do this exploration for you.
This matters because it unlocks background agents. If an agent can generate a solid plan *and execute it* without your sign-off, it can run asynchronously while you focus elsewhere. It’s a pivotal shift—from “I’m juggling multiple tabs” to “Work is advancing *without me*.”
Ralph Loops are a popular entry point: an autonomous agent loop that repeatedly runs a programming CLI until all items in the PRD (Product Requirements Document) are complete—each iteration launching a fresh instance with clean context. In my experience, running Ralph Loops well is surprisingly hard—any ambiguity or inaccuracy in the PRD eventually bites back. It’s a bit too “fire-and-forget.”
You can run multiple Ralph Loops in parallel—but the more agents you spin up, the more time you’ll spend: coordinating them, sequencing work, checking outputs, driving progress. You’ve stopped coding—you’ve become a middle manager. You need an orchestrator agent to handle scheduling, freeing you to focus on *intent*, not logistics.
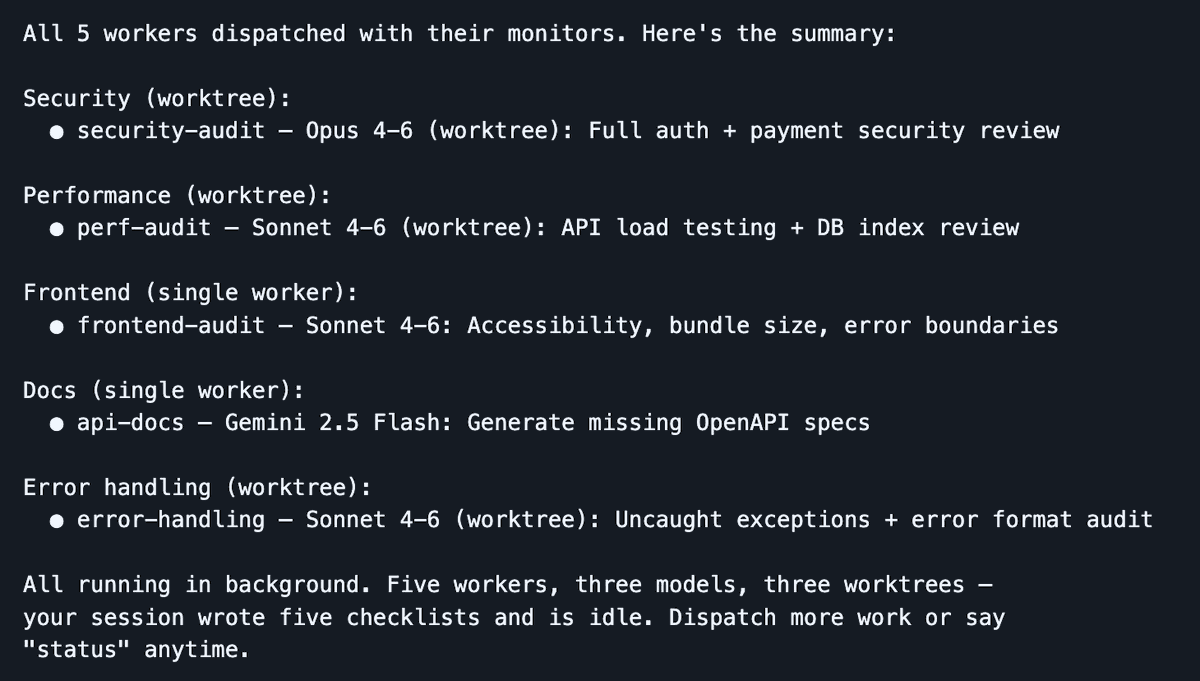
Dispatch launches 5 workers across 3 models in parallel—your session stays lean while agents do the heavy lifting
I’ve been heavily using Dispatch lately—a Claude Code skill I built—to turn your session into a command center. You stay in one clean session; workers handle heavy lifting in isolated contexts. The dispatcher handles planning, delegation, and tracking—keeping your main context window reserved for orchestration. When a worker stalls, it surfaces clarifying questions instead of failing silently.
Dispatch runs locally—ideal for rapid development where you want tight feedback loops, easier debugging, and zero infrastructure overhead. Ramp’s Inspect is the complementary solution for longer-running, more autonomous work: each agent session launches in a cloud sandbox VM with a full dev environment. A PM spots a UI bug, tags it in Slack—and Inspect takes over the moment you close your laptop. The tradeoff? Operational complexity (infrastructure, snapshots, security)—but you gain scale and reproducibility impossible with local agents. I recommend using both (local and cloud-based background agents).
One unexpectedly powerful pattern at this level: assign different models to different tasks. Top engineering teams aren’t clones. Teammates think differently, trained on varied backgrounds, with distinct strengths. Same logic applies to LLMs. These models undergo different post-training, yielding clearly distinct personalities. I regularly assign Opus to implementation, Gemini to exploratory research, and Codex to review—producing superior composite output than any single model alone. Think of it as collective intelligence—applied to code.
Critically, you must decouple implementer and reviewer. I’ve learned this the hard way, repeatedly: if the same model instance both implements *and* evaluates its own work, bias creeps in. It overlooks issues and declares all tasks complete—when they’re not. This isn’t malice; it’s the same reason you wouldn’t grade your own exam. Assign review to another model—or a separate instance with a review-specific prompt. Your signal quality jumps dramatically.
Background agents also unlock AI-CI integration. Once agents can run unattended, they can be triggered from existing infrastructure. A documentation bot regenerates docs after every merge and submits a PR to update CLAUDE.md (we use this—it saves massive time). A security review bot scans PRs and submits fixes. A dependency management bot doesn’t just flag issues—it upgrades packages *and* runs test suites. Good context, continuously codified rules, robust tools, automated feedback loops—all now running autonomously.
Level 8: Autonomous Agent Teams
No one has truly mastered this level yet—though a few are pushing toward it. This is the current frontier.
At Level 7, you orchestrate tasks from a central LLM to worker LLMs in a hub-and-spoke pattern. Level 8 removes that bottleneck. Agents coordinate *directly*—claiming tasks, sharing discoveries, flagging dependencies, resolving conflicts—without routing through a single orchestrator.
Claude Code’s experimental Agent Teams feature is an early implementation: multiple instances work in parallel on a shared codebase, with teammates running in their own context windows and communicating directly. Anthropic used 16 parallel agents to build a Linux-compilable C compiler from scratch. Cursor ran hundreds of concurrent agents for weeks—building a browser from scratch and migrating its own codebase from Solid to React.
But look closer—and problems surface. Cursor found agents became timid and stalled without hierarchical structure. Anthropic’s agents kept breaking existing functionality until CI pipelines were added to prevent regressions. Everyone experimenting at this level says the same thing: multi-agent coordination is a hard problem—and no one has found the optimal solution yet.
Honestly, I don’t think models are ready for this degree of autonomy on most tasks. Even if they’re smart enough, for moonshot projects beyond compilers and browsers, they’re still too slow, too token-expensive—and economically impractical (impressive, but far from mature). For most of us doing daily work, Level 7 is where the real leverage lies. I won’t be surprised if Level 8 eventually becomes mainstream—but for now, I’m focusing on Level 7 (unless you’re Cursor—breakthroughs *are* your business).
Level ?
The inevitable “What’s next?” question.
Once you can orchestrate agent teams smoothly, there’s no reason interaction should remain text-only. Voice-to-voice (or perhaps thought-to-thought?) interaction with programming agents—conversational Claude Code, not just speech-to-text input—is the natural next step. Look at your app, describe a sequence of changes aloud—and watch them happen before your eyes.
A group is chasing perfect one-shot generation: say what you want, and AI delivers it flawlessly in one go. The flaw in that premise? It assumes humans know *exactly* what we want. We don’t. We never have. Software development has always been iterative—and I believe it always will be. It’ll just become vastly easier, far beyond pure text interaction—and dramatically faster.
So: What level are you at? What are you doing to reach the next one?
What level are you at?
How do you typically start a programming task with AI?
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













