

Sora hasn't even launched yet, so why is it already shaking up the internet industry?
TechFlow Selected TechFlow Selected
Sora hasn't even launched yet, so why is it already shaking up the internet industry?
OpenAI directly calls it a "world simulator," capable of simulating the characteristics of people, animals, and environments in the physical world.
Author: Mu Mu
Even before opening public testing, OpenAI has already stunned the tech industry, internet community, and social media with teaser videos created by its text-to-video model, Sora.
According to official videos released by OpenAI, Sora can generate complex-scene "ultra-videos" up to one minute long based on user-provided text descriptions. Not only are the visual details highly realistic, but the model also simulates camera motion effects.
From the released video samples, what excites the industry is precisely Sora's demonstrated ability to understand the real world. Compared to other text-to-video large models, Sora shows advantages in semantic understanding, image rendering, visual coherence, and video duration.
OpenAI directly calls it a "world simulator," declaring that it can simulate characteristics of people, animals, and environments in the physical world. However, the company also acknowledges that Sora is not yet perfect and still has shortcomings in comprehension and potential safety issues.
Therefore, Sora is only available for testing by a very small number of individuals. OpenAI has not announced when Sora will be opened to the general public, but the impact it has generated is enough to make companies developing similar models realize the gap.
Sora’s “Trailer” Stuns Everyone
As soon as OpenAI unveiled its text-to-video model Sora, China once again saw an outpouring of sensational reactions.
Self-media outlets exclaimed “reality no longer exists,” and internet tycoons praised Sora’s capabilities. Zhou Hongyi, founder of 360, said Sora’s emergence could shorten the timeline for achieving AGI from ten years to about two. Within just a few days, Sora’s Google search index surged rapidly, reaching popularity levels close to ChatGPT.
Sora’s viral success stems from the 48 videos released by OpenAI, with the longest lasting one full minute. This not only breaks previous length limits of text-to-video models like Gen2 and Runway but also delivers clear visuals—and even demonstrates an understanding of cinematography language.
In a one-minute clip, a woman in a red dress walks down a neon-lit street with photorealistic style and smooth motion. Most striking is the close-up of her face—every pore, freckle, and acne scar is accurately simulated. The makeup fading effect rivals turning off beauty filters during a live stream, while neck wrinkles precisely reveal her age, perfectly matching her facial appearance.
Beyond human realism, Sora can also simulate real-world animals and environments. In one video featuring multi-angle close-ups of a Victoria crowned pigeon, ultra-high resolution reveals the bird’s blue feathers down to its crown, including subtle details such as dynamic red eyes and breathing rhythms—making it nearly impossible to tell whether the footage was AI-generated or filmed by humans.
For non-realistic creative animations, Sora achieves visual quality comparable to Disney animated films, leading netizens to worry about animators losing their jobs.
Moreover, Sora’s improvements go beyond video length and image quality—it can simulate camera movements and shooting trajectories, first-person perspectives from games, aerial views, and even continuous single-take sequences seen in movies.
After watching the impressive videos released by OpenAI, you can understand why the tech and social media communities are so shocked by Sora—and these are just trailers.
OpenAI Introduces the “Visual Patch” Dataset
So how does Sora achieve this simulation capability?
According to OpenAI’s technical report on Sora, this model is surpassing limitations of earlier image generation models.
Past research into text-to-visual generation has used various methods, including recurrent networks, generative adversarial networks (GANs), autoregressive transformers, and diffusion models—but typically focused on limited categories of visual data, short videos, or fixed-size videos.
Sora uses a Transformer-based diffusion model. The image generation process consists of two stages: a forward process and a reverse process, enabling Sora to extend videos forward or backward along the timeline.
The forward process simulates the transformation from a real image to pure noise. Specifically, the model gradually adds noise to an image until it becomes completely noisy. The reverse process is the inverse: starting from a noisy image, the model gradually reconstructs the original image. Through this back-and-forth between reality and noise, OpenAI enables the machine Sora to learn how visual content forms.
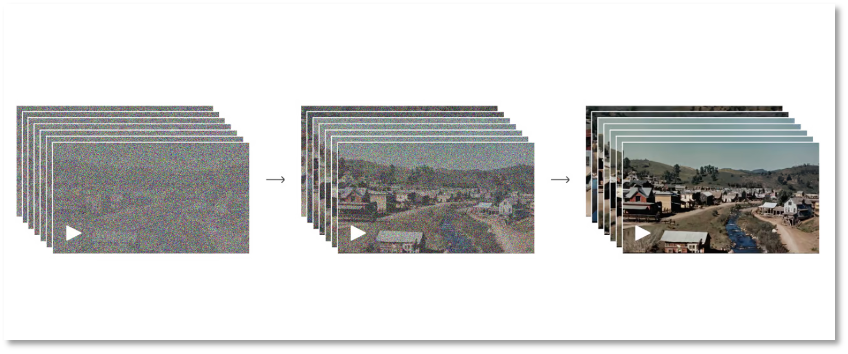 Process from complete noise to clear image
Process from complete noise to clear image
Of course, this process requires repeated training. The model learns how to progressively remove noise and restore image details. Through iterative cycles of these two phases, Sora’s diffusion model generates high-quality images. This type of model has shown excellent performance in image generation, image editing, and super-resolution tasks.
This explains why Sora can produce high-definition, ultra-detailed results. But moving from static images to dynamic videos requires further data accumulation and training.
Building upon the diffusion model, OpenAI converts all types of visual data—including videos and images—into a unified representation for large-scale generative training of Sora. This representation, defined by OpenAI as “visual patches,” consists of smaller data units analogous to text tokens in GPT.
Researchers first compress video into a low-dimensional latent space, then decompose this representation into spatiotemporal patches—a highly scalable format that facilitates conversion from video to patches and is well-suited for training models to handle diverse video and image types.
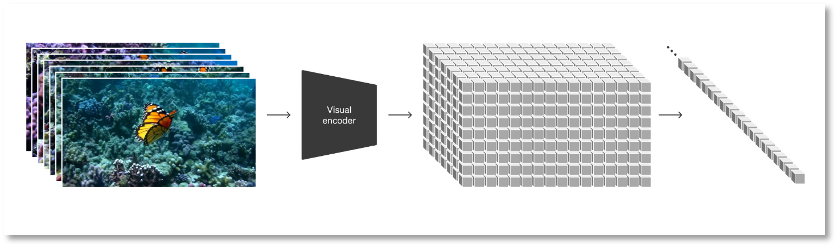 Converting visual data into patches
Converting visual data into patches
To reduce information volume and computational cost during training, OpenAI developed a video compression network that reduces video dimensions to a low-level latent space at the pixel level. Compressed video data is then used to generate patches, reducing input size and thus computational load. Simultaneously, OpenAI trained a corresponding decoder model to map compressed information back into pixel space.
Using this patch-based representation, researchers can train Sora on videos and images of varying resolutions, durations, and aspect ratios. During inference, Sora determines video logic and controls output size by arranging randomly initialized patches within appropriately sized grids.
OpenAI reports that during large-scale training, the video model exhibited exciting capabilities—Sora can realistically simulate people, animals, and environments in the real world, generate high-fidelity videos, and achieve both 3D consistency and temporal consistency, thereby accurately simulating the physical world.
Altman Acts as Middleman for Public Testing
Despite showing strong capabilities—from results to development process—ordinary users still cannot access Sora. Currently, people can only write prompts and tag OpenAI co-founder Sam Altman on X (formerly Twitter), who then acts as a middleman, generating videos via Sora and sharing them publicly.
This inevitably raises doubts about whether Sora is truly as powerful as OpenAI claims.
In response, OpenAI admits the current model still has flaws. Like early versions of GPT, Sora suffers from “hallucinations”—errors that manifest more vividly in video outputs due to their visual nature.
For example, it fails to accurately simulate basic physical interactions, such as the relationship between a treadmill belt and human movement, or the timing logic between a glass breaking and liquid spilling out.
In one video clip titled “archaeologists excavating a plastic chair,” the chair simply floats out of the sand.
There are also instances of puppies appearing out of nowhere, humorously dubbed “wolf mitosis” by netizens.
It sometimes confuses left from right.
These visible flaws in dynamic scenes suggest that Sora still needs deeper understanding and training regarding the logic of physical motion in the real world. Moreover, compared to the risks posed by ChatGPT, Sora—which provides direct visual experiences—carries greater ethical and safety concerns.
Previously, text-to-image model Midjourney already taught humanity that “seeing is no longer believing”—AI-generated photorealistic images have become elements of misinformation. Dr. Newman, Chief Scientific Officer at identity verification firm iProov, stated that Sora would allow “malicious actors to more easily generate high-quality fake videos.”
It’s easy to imagine the unpredictable consequences if Sora-generated videos are maliciously used for fraud, defamation, spreading violence, or pornography—this is why Sora inspires not only awe but also fear.
OpenAI is aware of the potential safety issues Sora might bring, which is likely why access is currently limited to a select few through invitation-only testing. When will it open to the public? OpenAI hasn’t provided a timeline. But judging from the officially released videos, other companies don’t have much time left to catch up with Sora.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News










