
黃仁勳 CES2026 最新演講:三個關鍵話題,一臺“芯片怪獸”
TechFlow Selected深潮精選
黃仁勳 CES2026 最新演講:三個關鍵話題,一臺“芯片怪獸”
當物理 AI 需要持續思考、長期運行,並真正進入現實世界,問題已經不再只是算力夠不夠,而是誰能把整套系統真正搭起來。
作者:李海倫 蘇揚
北京時間 1月 6 日,英偉達 CEO 黃仁勳身著標誌性皮衣再次站在 CES2026 的主舞臺上。
2025年 CES,英偉達展示了量產的 Blackwell 芯片和完整的物理 AI 技術棧。在會上,黃仁勳強調,一個“物理 AI 時代”正在開啟。他描繪了一個充滿想象力的未來:自動駕駛汽車具備推理能力,機器人能夠理解並思考,AIAgent(智能體)可以處理百萬級 token 的長上下文任務。
轉眼一年過去,AI 行業經歷了巨大的變革演進。黃仁勳在發佈會上回顧這一年的變化時,重點提到了開源模型。
他說,像 DeepSeek R1 這樣的開源推理模型,讓整個行業意識到:當開放、全球協作真正啟動後,AI 的擴散速度會極快。儘管開源模型在整體能力上仍比最前沿模型慢大約半年,但每隔六個月就會追近一次,而且下載量和使用量已經呈爆發式增長。

相比 2025 年更多展示願景與可能性,這一次英偉達開始系統性地希望解決“如何實現”的問題:圍繞推理型 AI,補齊長期運行所需的算力、網絡與存儲基礎設施,顯著壓低推理成本,並將這些能力直接嵌入自動駕駛和機器人等真實場景。
在本次黃仁勳在 CES 上的演講,圍繞三條主線展開:
●在系統與基礎設施層面,英偉達圍繞長期推理需求重構了算力、網絡與存儲架構。以 Rubin 平臺、NVLink 6、Spectrum-X 以太網和推理上下文內存存儲平臺為核心,這些更新直指推理成本高、上下文難以持續和規模化受限等瓶頸,解決 AI 多想一會、算得起、跑得久的問題。
●在模型層面,英偉達將推理型 AI(Reasoning / Agentic AI)置於核心位置。通過 Alpamayo、Nemotron、Cosmos Reason 等模型與工具,推動 AI 從“生成內容”邁向能夠持續思考、從“一次性響應的模型”轉向“可以長期工作的智能體”。
●在應用與落地層面,這些能力被直接引入自動駕駛和機器人等物理 AI 場景。無論是 Alpamayo 驅動的自動駕駛體系,還是 GR00T 與 Jetson 的機器人生態,都在通過雲廠商和企業級平臺合作,推動規模化部署。

01 從路線圖到量產:Rubin 首次完整披露性能數據
在本次 CES 上,英偉達首次完整披露了 Rubin 架構的技術細節。
演講中,黃仁勳從 Test-time Scaling(推理時擴展)開始鋪墊,這個概念可以理解為,想要 AI 變聰明,不再只是讓它“多努力讀書”,而是靠“遇到問題時多想一會兒”。
過去,AI 能力的提升主要靠訓練階段砸更多算力,把模型越做越大;而現在,新的變化是哪怕模型不再繼續變大,只要在每次使用時給它多一點時間和算力去思考,結果也能明顯變好。
如何讓“AI 多思考一會兒”變得經濟可行?Rubin 架構的新一代 AI 計算平臺就是來解決這個問題。
黃仁勳介紹,這是一套完整的下一代 AI 計算系統,通過 Vera CPU、Rubin GPU、NVLink 6、ConnectX-9、BlueField-4、Spectrum-6 的協同設計,以此實現推理成本的革命性下降。

英偉達 Rubin GPU 是Rubin 架構中負責 AI 計算的核心芯片,目標是顯著降低推理與訓練的單位成本。
說白了,Rubin GPU 核心任務是“讓 AI 用起來更省、更聰明”。
Rubin GPU 的核心能力在於:同一塊 GPU 能幹更多活。它一次能處理更多推理任務、記住更長的上下文,和其他 GPU 之間的溝通也更快,這意味著很多原本要靠“多卡硬堆”的場景,現在可以用更少的 GPU 完成。
結果就是,推理不但更快了,而且明顯更便宜。
黃仁勳現場給大家複習了 Rubin 架構的 NVL72 硬件參數:包含 220 萬億晶體管,帶寬 260 TB/秒,是業界首個支持機架規模機密計算的平臺。

整體來看,相比 Blackwell,Rubin GPU 在關鍵指標上實現跨代躍升:NVFP4 推理性能提升至 50 PFLOPS(5 倍)、訓練性能提升至 35 PFLOPS(3.5 倍),HBM4 內存帶寬提升至 22 TB/s(2.8 倍),單 GPU 的 NVLink 互連帶寬翻倍至 3.6 TB/s。
這些提升共同作用,使單個 GPU 能處理更多推理任務與更長上下文,從根本上減少對 GPU 數量的依賴。

Vera CPU 是專為數據移動和 Agentic 處理設計的核心組件,採用 88 個英偉達自研 Olympus 核心,配備 1.5 TB 系統內存(是上代 Grace CPU 的3 倍),通過 1.8 TB/s的 NVLink-C2C 技術實現 CPU與 GPU 之間的一致性內存訪問。
與傳統通用 CPU 不同,Vera 專注於 AI 推理場景中的數據調度和多步驟推理邏輯處理,本質上是讓“AI 多想一會兒”得以高效運行的系統協調者。
NVLink 6 通過 3.6 TB/s 的帶寬和網絡內計算能力,讓 Rubin 架構中的 72個 GPU 能像一個超級 GPU 一樣協同工作,這是實現降低推理成本的關鍵基礎設施。
這樣一來,AI 在推理時需要的數據和中間結果可以迅速在 GPU 之間流轉,不用反覆等待、拷貝或重算。


在 Rubin 架構中,NVLink-6 負責 GPU 內部協同計算,BlueField-4 負責上下文與數據調度,而 ConnectX-9 則承擔系統對外的高速網絡連接。它確保 Rubin 系統能夠與其他機架、數據中心和雲平臺高效通信,是大規模訓練和推理任務順利運行的前提條件。
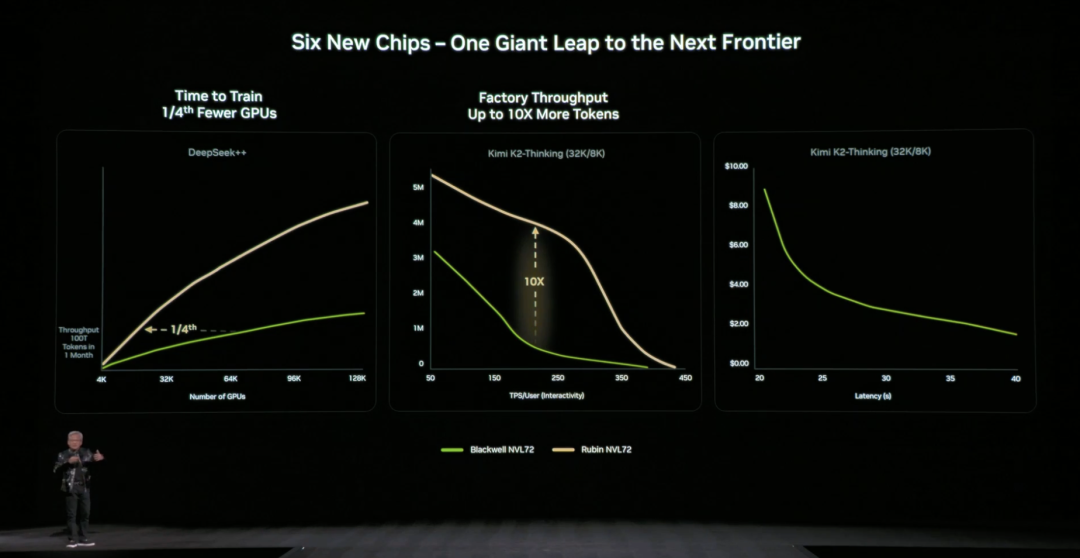
相比上一代架構,英偉達也給出具體直觀的數據:相比 NVIDIA Blackwell 平臺,可將推理階段的 token 成本最高降低 10 倍,並將訓練混合專家模型(MoE)所需的 GPU 數量減少至原來的 1/4。
英偉達官方表示,目前微軟已承諾在下一代 Fairwater AI 超級工廠中部署數十萬 Vera Rubin 芯片,CoreWeave 等雲服務商將在 2026 年下半年提供 Rubin 實例,這套“讓 AI 多想一會兒”的基礎設施正在從技術演示走向規模化商用。

02 “存儲瓶頸”如何解決?
讓 AI“多想一會兒”還面臨一個關鍵技術挑戰:上下文數據該放在哪裡?
當 AI 處理需要多輪對話、多步推理的複雜任務時,會產生大量上下文數據(KV Cache)。傳統架構要麼把它們塞進昂貴且容量有限的 GPU 內存,要麼放到普通存儲裡(訪問太慢)。這個“存儲瓶頸”如果不解決,再強的 GPU 也會被拖累。
針對這個問題,英偉達在本次 CES 上首次完整披露了由 BlueField-4 驅動的推理上下文內存存儲平臺(Inference Context Memory Storage Platform),核心目標是在 GPU 內存和傳統存儲之間創建一個“第三層”。既足夠快,又有充足容量,還能支撐 AI 長期運行。
從技術實現上看,這個平臺並不是單一組件在發揮作用,而是一套協同設計的結果:
- BlueField-4 負責在硬件層面加速上下文數據的管理與訪問,減少數據搬移和系統開銷;
- Spectrum-X 以太網提供高性能網絡,支持基於 RDMA 的高速數據共享;
- DOCA、NIXL和 Dynamo 等軟件組件,則負責在系統層面優化調度、降低延遲、提升整體吞吐。
我們可以理解為,這套平臺的做法是,將原本只能放在 GPU 內存裡的上下文數據,擴展到一個獨立、高速、可共享的“記憶層”中。一方面釋放 GPU 的壓力,另一方面又能在多個節點、多個 AI 智能體之間快速共享這些上下文信息。
在實際效果方面,英偉達官方給出的數據是:在特定場景下,這種方式可以讓每秒處理的 token 數提升最高達 5 倍,並實現同等水平的能效優化。
黃仁勳在發佈中多次強調,AI 正在從“一次性對話的聊天機器人”,演進為真正的智能協作體:它們需要理解現實世界、持續推理、調用工具完成任務,並同時保留短期與長期記憶。這正是 Agentic AI 的核心特徵。推理上下文內存存儲平臺,正是為這種長期運行、反覆思考的 AI 形態而設計,通過擴大上下文容量、加快跨節點共享,讓多輪對話和多智能體協作更加穩定,不再“越跑越慢”。

03
新一代 DGX SuperPOD :讓 576個 GPU 協同工作
英偉達在本次 CES 上宣佈推出基於 Rubin 架構的新一代 DGX SuperPOD(超節點),將 Rubin 從單機架擴展到整個數據中心的完整方案。
什麼是 DGX SuperPOD?
如果說 Rubin NVL72 是一個裝有 72個 GPU 的“超級機架”,那麼 DGX SuperPOD 就是把多個這樣的機架連接起來,形成一個更大規模的 AI 計算集群。這次發佈的版本由 8個 Vera Rubin NVL72 機架組成,相當於 576個 GPU 協同工作。
當 AI 任務規模繼續擴大時,單個機架的 576個 GPU 可能還不夠。比如訓練超大規模模型、同時服務數千個 Agentic AI 智能體、或者處理需要數百萬 token 上下文的複雜任務。這時就需要多個機架協同工作,而 DGX SuperPOD 就是為這種場景設計的標準化方案。
對於企業和雲服務商來說,DGX SuperPOD 提供的是一個“開箱即用”的大規模 AI 基礎設施方案。不需要自己研究如何把數百個 GPU 連接起來、如何配置網絡、如何管理存儲等問題。
新一代 DGX SuperPOD 五大核心組件:
○8個 Vera Rubin NVL72 機架 - 提供計算能力的核心,每個機架 72個 GPU,總共 576個 GPU;
○NVLink 6 擴展網絡 - 讓這 8 個機架內的 576個 GPU 能像一個超大 GPU 一樣協同工作;
○Spectrum-X 以太網擴展網絡 - 連接不同的 SuperPOD,以及連接到存儲和外部網絡;
○推理上下文內存存儲平臺 - 為長時間推理任務提供共享的上下文數據存儲;
○英偉達 Mission Control 軟件 - 管理整個系統的調度、監控和優化。
這一次的升級,SuperPOD 的基礎以 DGX Vera Rubin NVL72 機架級系統為核心。每一臺 NVL72 本身就是一臺完整的 AI 超級計算機,內部通過 NVLink 6 將72塊 Rubin GPU 連接在一起,能夠在一個機架內完成大規模推理和訓練任務。新的 DGX SuperPOD,則由多臺 NVL72 組成,形成一個可以長期運行的系統級集群。
當計算規模從“單機架”擴展到“多機架”後,新的瓶頸隨之出現:如何在機架之間穩定、高效地傳輸海量數據。圍繞這一問題,英偉達在本次 CES 上同步發佈了基於 Spectrum-6 芯片的新一代以太網交換機,並首次引入“共封裝光學”(CPO)技術。
簡單來看,就是將原本可插拔的光模塊直接封裝在交換芯片旁邊,把信號傳輸距離從幾米縮短到幾毫米,從而顯著降低功耗和延遲,也提升了系統整體的穩定性。
04 英偉達開源 AI“全家桶”:從數據到代碼一應俱全
本次 CES 上,黃仁勳宣佈擴展其開源模型生態(Open Model Universe),新增和更新了一系列模型、數據集、代碼庫和工具。這個生態覆蓋六大領域:生物醫學 AI(Clara)、AI 物理模擬(Earth-2)、Agentic AI(Nemotron)、物理 AI(Cosmos)、機器人(GR00T)和自動駕駛(Alpamayo)。
訓練一個 AI 模型需要的不只是算力,還需要高質量數據集、預訓練模型、訓練代碼、評估工具等一整套基礎設施。對大多數企業和研究機構來說,從零開始搭建這些太耗時間。
具體來說,英偉達開源了六個層次的內容:算力平臺(DGX、HGX 等)、各領域的訓練數據集、預訓練的基礎模型、推理和訓練代碼庫、完整的訓練流程腳本,以及端到端的解決方案模板。
Nemotron 系列是此次更新的重點,覆蓋了四個應用方向。
在推理方向,包括 Nemotron 3 Nano、Nemotron 2 Nano VL 等小型化推理模型,以及 NeMo RL、NeMo Gym 等強化學習訓練工具。在 RAG(檢索增強生成)方向,提供了 Nemotron Embed VL(向量嵌入模型)、Nemotron Rerank VL(重排序模型)、相關數據集和 NeMo Retriever Library(檢索庫)。在安全方向,有 Nemotron Content Safety 內容安全模型及配套數據集、NeMo Guardrails 護欄庫。
在語音方向,則包含 Nemotron ASR 自動語音識別、Granary Dataset 語音數據集和 NeMo Library 語音處理庫。這意味著企業想做一個帶 RAG的 AI 客服系統,不需要自己訓練嵌入模型和重排序模型,可以直接使用英偉達已經訓練好並開源的代碼。
05 物理 AI 領域,走向商業化落地
物理 AI 領域同樣有模型更新——用於理解和生成物理世界視頻的 Cosmos,機器人通用基礎模型 Isaac GR00T、自動駕駛視覺-語言-行動模型 Alpamayo。

黃仁勳在 CES 上聲稱,物理 AI 的“ChatGPT 時刻”快要來了,但面對挑戰也很多:物理世界太複雜多變,採集真實數據又慢又貴,永遠不夠用。
怎麼辦呢?合成數據是條路。於是英偉達推出了 Cosmos。
這是一個開源的物理 AI 世界基礎模型,目前已經用海量視頻、真實駕駛與機器人數據,以及 3D 模擬做過預訓練。它能理解世界是怎麼運行的,可以把語言、圖像、3D 和動作聯繫起來。
黃仁勳表示,Cosmos 能實現不少物理 AI 技能,比如生成內容、做推理、預測軌跡(哪怕只給它一張圖)。它可以依據 3D 場景生成逼真的視頻,根據駕駛數據生成符合物理規律的運動,還能從模擬器、多攝像頭畫面或文字描述生成全景視頻。就連罕見場景,也能還原出來。
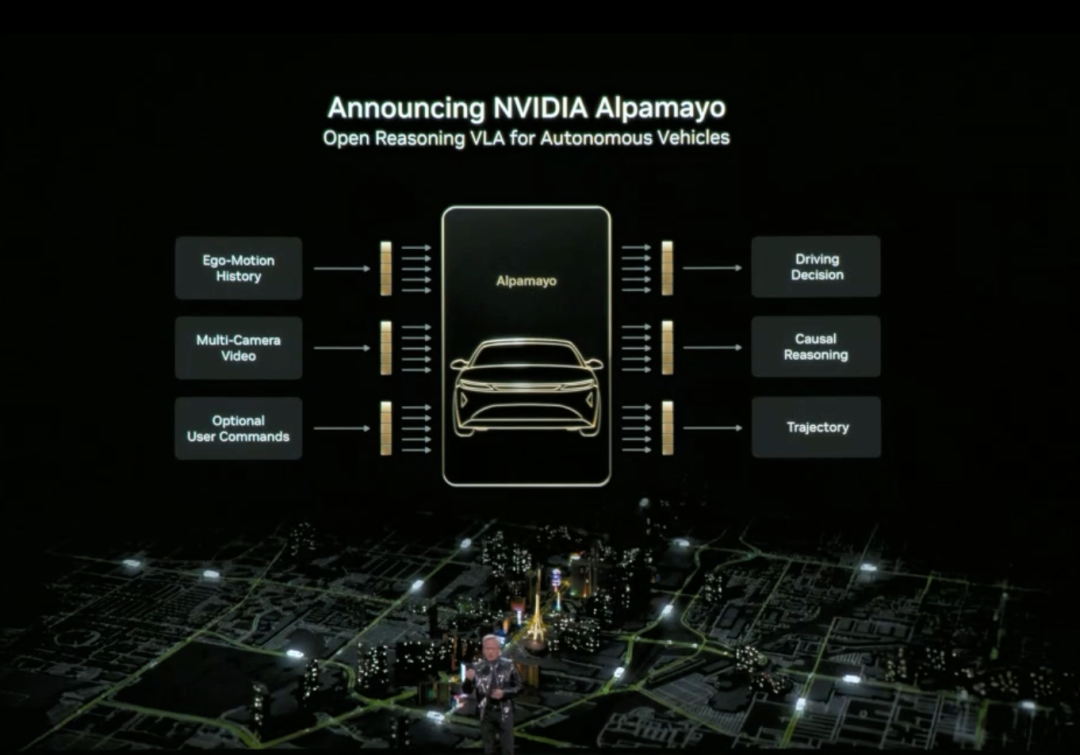
黃仁勳還正式發佈了 Alpamayo。Alpamayo 是一個面向自動駕駛領域的開源工具鏈,也是首個開源的視覺-語言-行動(VLA)推理模型。與之前僅開源代碼不同,英偉達這次開源了從數據到部署的完整開發資源。
Alpamayo 最大的突破在於它是“推理型”自動駕駛模型。傳統自動駕駛系統是“感知-規劃-控制”的流水線架構,看到紅燈就剎車,看到行人就減速,遵循預設規則。而 Alpamayo 引入了“推理”能力,理解複雜場景中的因果關係,預測其他車輛和行人的意圖,甚至能處理需要多步思考的決策。
比如在十字路口,它不只是識別出“前方有車”,而是能推理”那輛車可能要左轉,所以我應該等它先過”。這種能力讓自動駕駛從“按規則行駛”升級到“像人一樣思考”。
黃仁勳宣佈英偉達 DRIVE 系統正式進入量產階段,首個應用是全新的梅賽德斯-奔馳 CLA,計劃 2026 年在美國上路。這款車將搭載 L2++級自動駕駛系統,採用“端到端 AI 模型+傳統流水線”的混合架構。
機器人領域同樣有實質性進展。
黃仁勳表示包括 Boston Dynamics、Franka Robotics、LEM Surgical、LG Electronics、Neura Robotics和 XRlabs 在內的全球機器人領軍企業,正在基於英偉達 Isaac 平臺和 GR00T 基礎模型開發產品,覆蓋了從工業機器人、手術機器人到人形機器人、消費級機器人的多個領域。

在發佈會現場,黃仁勳背後站滿了不同形態、不同用途的機器人,它們被集中展示在分層舞臺上:從人形機器人、雙足與輪式服務機器人,到工業機械臂、工程機械、無人機與手術輔助設備,展現出一版“機器人生態圖景”。
從物理 AI 應用到 RubinAI 計算平臺,再到推理上下文內存存儲平臺和開源 AI“全家桶”。
英偉達在 CES 上展示的這些動作,構成了英偉達對於推理時代 AI 基礎設施的敘事。正如黃仁勳反覆強調的那樣,當物理 AI 需要持續思考、長期運行,並真正進入現實世界,問題已經不再只是算力夠不夠,而是誰能把整套系統真正搭起來。
CES 2026 上,英偉達已經給出了一份答卷。
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News














