

SemiAnalysis 創始人解析萬億美元 AI 競爭:算力是 AI 世界的貨幣,Nvidia 是“中央銀行”
TechFlow Selected深潮精選
SemiAnalysis 創始人解析萬億美元 AI 競爭:算力是 AI 世界的貨幣,Nvidia 是“中央銀行”
AI 不只是算法革命,而是一場由算力、資金與地緣政治共同驅動的產業遷徙。
編譯:Grace
編輯:Siqi

在 AI 帶來的新一輪全球基礎設施重構中,算力、資本與能源正以前所未有的方式交織在一起。
本文是 SemiAnalysis 創始人兼 CEO Dylan Patel 在 Invest Like The Best 的最新訪談。Dylan Patel 是業內最知名的 AI 與半導體分析師之一,他和團隊長期跟蹤半導體供應鏈和 AI 基建,甚至通過衛星影像監測數據中心的建設,非常熟悉前沿技術的發展進程,具有極強的行業影響力。
在採訪中,他從產業鏈、能源網絡與資本流動出發,勾勒出一個極少被公開討論的事實:AI 不只是算法革命,而是一場由算力、資金與地緣政治共同驅動的產業遷徙。
• 算力—資本—基礎設施正形成閉環,算力就是 AI 時代的貨幣;
• 誰掌控數據、接口與切換成本,誰就擁有了 AI 市場的話語權;
•Neo clouds 與推理服務商承擔最大的需求與信用不確定性,而穩定利潤最終流向英偉達;
•Scaling Law 不會出現邊際效益遞減現象;
• 模型“更大”不等於“更聰明”,真正進步來自模型算法或者架構的優化、模型推理時間的延長;
•在 AI Factory 範式下,企業競爭的關鍵因素在於用最低 token 成本提供穩定、可規模化的智能服務;
•硬件創新的重心在芯片互聯、光電與電力設備等老工業環節,因此能真正推動硬件創新的仍是巨頭。
01.AI 掌控之爭:誰在博弈?如何取勝?
三千億美元的三角交易是什麼?
在當下的 AI infra 競賽中,OpenAI–Oracle–Nvidia 之間形成了一個獨特結構性合作,這一交易模式被市場稱為“三角交易(Triangle Deal)”,三方在資金流與產能上形成了深度捆綁。
•OpenAI 向甲骨文購買雲服務;
•甲骨文作為硬件基礎設施供應商,負責建設並運營龐大的數據中心,因此需要向英偉達採購大量的 GPU 芯片,資金會在很大程度上流回英偉達;
•之後,英偉達再將自身部分利潤以戰略投資的形式返還給 OpenAI,支持 OpenAI 的 AI 基礎設施建設。
2025 年 6 月,甲骨文 Orcl 首次披露與 OpenAI 的重大雲服務交易,OpenAI 將在未來五年內向甲骨文購買總額約 3000 億美元的算力服務(年均支出約 600 億美元),監管文件顯示,這項協議將在 2027 財年起,為甲骨文帶來超過 300 億美元收入,這成為史上規模最大的雲端合約之一。
2025 年 9 月,英偉達宣佈將向 OpenAI 投資最高 1000 億美元,雙方將合作建設至少 10 吉瓦的 AI 數據中心,用於訓練與運行下一代模型,耗電量相當於 800 萬戶美國家庭。英偉達股價當日上漲超 4%,市值逼近 4.5 萬億美元。
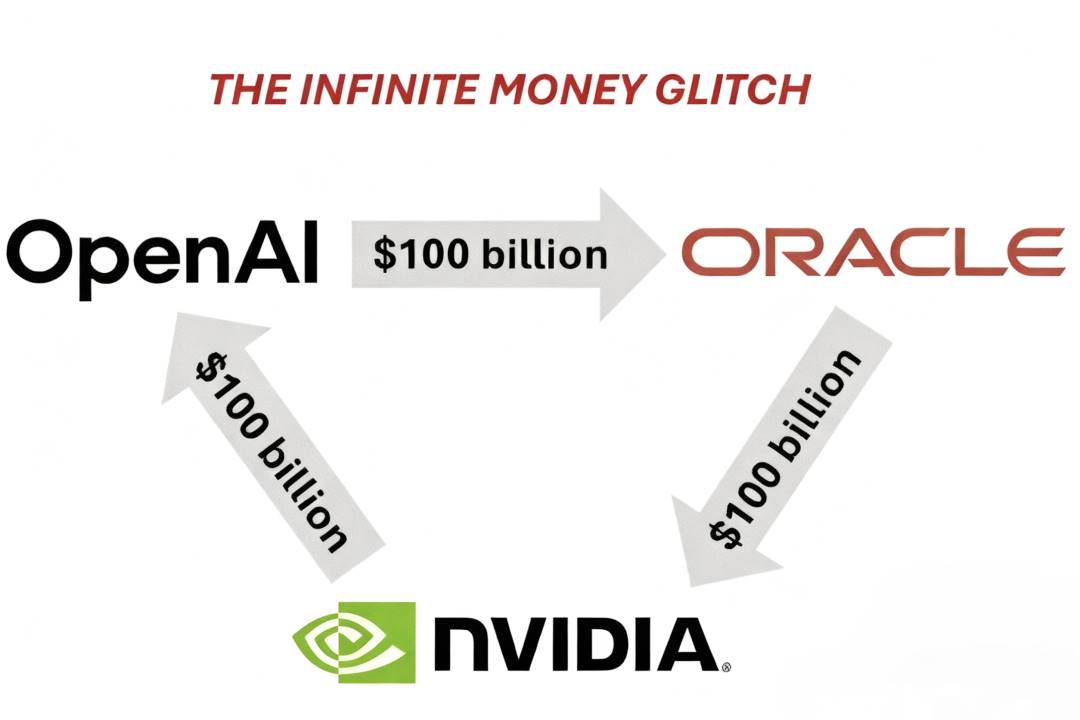
按照 Dylan 的估算,1GW 數據中心的建設成本約為每年 100–150 億美元,合同期一般為 5 年,總額約在 500–750 億美元之間。如果 OpenAI 的目標是構建 10GW 級別的計算集群,那麼總資金需求將達到數千億美元規模。
以 Nvidia 與 OpenAI 的交易為例,1GW 集群對應約 100 億美元的 Nvidia 股權投資,但完整建設一座 1GW 級別的 AI 數據中心的總成本約為 500 億美元,其中會有大約 350 億美元直接流向 Nvidia,這部分的毛利率高達 75%。換句話說,Nvidia 實際上將一半的毛利轉化為 OpenAI 的股權,達成一種結構性讓利。
這一三角交易不僅是對算力稀缺的回應,更代表了 AI 行業資本化的新階段:在這個階段,算力成為新的貨幣,基礎設施成為價值分配的高地,技術創新的速度被金融結構不斷放大。
數據、接口與切換成本:掌控 AI 市場話語權的關鍵
AI 產業的競爭表面上是模型與平臺之爭,實質上是權力鏈條的重構。Dylan 認為,誰掌控數據、接口與切換成本,誰就掌控了 AI 市場的話語權。
以 Cursor與 Anthropic 為例,表面上 Anthropic 作為模型提供方賺取了大部分毛利,但 Cursor 作為應用方掌握了用戶與代碼庫數據,且可在多模型之間自由切換,最終仍保有議價空間。
這種博弈也存在於 OpenAI 與微軟之間。2023 年,微軟幾乎完全掌控 OpenAI 的算力與資本合作,但到了 2024 年下半年,為避免承擔約 3000 億美元的長期支出,微軟暫停了部分數據中心建設,放棄獨家算力供應,OpenAI 轉向了 Oracle。OpenAI 與微軟目前正就利潤分配(微軟的封頂利潤為 49%)和知識產權共享進行重新談判,雙方的控制權正從以微軟為主逐漸轉向更加平衡的合作關係。
在硬件層面也是如此,Nvidia 無法通過併購來擴大控制力,只能依靠資產負債表來“兜底”——通過需求擔保、回購協議,甚至提前分配算力等方式鞏固自身生態體系。Dylan 將這一過程稱為“GPU 貨幣化”:GPU 已成為整個 AI 行業的通用貨幣,而 Nvidia 則像一座中央銀行,通過融資與供給規則來掌控流通。
這種前置分配機制還被大量複製——Oracle、CoreWeave 等公司都在向合作伙伴提供“首年免付算力窗口”,讓對方能夠先行進行模型訓練、獲得推理補貼、擴大用戶規模,再在隨後的四年內以現金流方式償還成本。
由此,AI 行業形成了一個跨越硬件—資本—雲服務—應用的多層權力鏈條。算力、資金與信用在這條鏈上循環流轉,構成 AI 世界的金融基礎設施。
Neo Clouds:AI 產業鏈的新商業分層
Nebius、CoreWeave 的崛起本質上是 AI 產業鏈正在形成一個新的商業分層:Neo Clouds 介於芯片製造、雲算力等底層供給與大模型、應用產品等上層生態之間,承擔著算力租賃、模型託管與推理服務的角色。
Neo Clouds 有兩種模式:
1. 短期合同:
通過購買 GPU、搭建數據中心,用高溢價租出算力。這一模式現金流充足但價格風險極高。以英偉達 Blackwell 為例,如果按六年攤銷計算,每小時算力成本約 2 美元,短期合同可賣到 3.5 至 4 美元,利潤非常高。但當下一代芯片發佈之後,芯片性能提升了十倍,價格僅提高了三倍,這類資產價值就會迅速下滑。
2. 長期綁定:
通過多年期合同鎖定客戶。這一模式毛利穩定但非常依賴對手方信用,如果無法履約,風險將集中落在 middle layer players 身上:
•Nebius 與 Microsoft 簽訂了一份 190 億美元的長期合同,確保了穩定的現金流和高額利潤,市場甚至認為這個信用水平高於美國國債;
•CoreWeave 早期主要依賴微軟的訂單,是微軟重要的算力合作伙伴。後來,Microsoft 減少了採購規模,CoreWeave 轉而與 Google 和 OpenAI 建立合作關係,向這些公司提供 GPU 計算資源和數據中心服務。這讓它在短期內維持了高利潤,但也帶來了新的風險,尤其是 OpenAI 的償付能力不足,讓這些合同的長期穩定性存在隱憂。
Inference Providers 也在 Neo Clouds Business Model 中尋找到了新的增長空間。它們為客戶提供模型託管和高效推理服務,主要面向 Roblox、Shopify 等企業。這些企業雖然具備自建模型的能力,但推理部署過程往往非常複雜,尤其是在大模型和多任務場景下。Inference Providers 通過提供開源模型微調、穩定算力和可靠服務,成為整個系統運行中的關鍵一環。
Inference Providers:提供模型推理服務的第三方平臺或企業,是已經部署了某個模型並允許用戶通過 API 或其他接口使用這個模型的服務商,也就是說用戶可以付費使用這些服務商提供的 API。
然而,這些 Inference Providers 自身也處於高度不確定的環境中。它們的客戶多為資金有限的初創企業或中小型 SaaS開發者,項目週期短、合同履約風險高,一旦資金鍊斷裂,風險便會層層傳導。最終,產業鏈的利潤依然集中在英偉達:它通過銷售 GPU 實現穩定收益,卻幾乎不受市場波動影響。所有的不確定性與信用風險,都由 Inference Providers 來承擔。
AI 軍備競賽
Dylan 同樣認為,AI 已成為新的戰略賽道,尤其在大國博弈的語境下,競爭不再侷限於技術維度,而是國家經濟與體系的整體對抗。尤其對美國而言,AI 是維持其全球主導地位的最後關鍵點,如果沒有這場 AI 浪潮,美國可能會在本世紀末失去世界霸權。
今天來看,美國社會的增長動力正在枯竭:債務高企、製造業迴流緩慢、基礎設施老化,而 AI 是唯一能讓經濟重新進入增長通道的加速器。因此,美國必須依靠 AI 來維持 GDP 擴張、控制債務風險並延續制度秩序。當前,美國的模式依然建立在資本市場與創新驅動之上,依靠開放生態與私營部門的鉅額投入,通過超大規模算力建設維持領先地位。
中國採取的則是截然不同的長期戰略。中國政府常以“以虧損換份額”的方式推動產業崛起,無論是鋼鐵、稀土、太陽能、電動車,還是 PCB 行業,中國都依靠國家資本與政策扶持,逐步取得全球市場份額。如今,這一模式被複制到半導體與 AI 領域。中國政府通過“五年規劃”、“國家大基金”及地方財政政策,對半導體產業的累計投入已達 400–5000 億美元。這些投資的目標並不是要實現性能領先,而是要構建完整、可控的供應鏈體系,實現從材料到封裝的全鏈自給,來確保地緣緊張環境下的產業安全。
同時,在執行層面,中國展現出顯著的速度優勢與組織動員能力。如果中國決定建設一個 2–5GW 級的數據中心,可能只需數年,而美國在同等規模的建設上通常需要兩到三倍時間。
02.AI 技術路線討論
Scaling Law 不會出現邊際效益遞減現象
Dylan 不認為 Scaling Law 會出現邊際效益遞減的現象。在對數-對數座標下,即使沒有模型架構的改進,只要不斷增加計算量、數據量和模型規模,模型的性能仍會按一定的速度提升。
Dylan 將這種現象比作人類智能的成長曲線:人類從 6 歲到 16 歲的變化不是連續加法,而是階段性的跨越。換句話說,模型的智能提升是質變式的,雖然實現下一個階段的能力可能需要投入 10 倍算力,但帶來的經濟回報足以支撐這種投入。
但 Scaling Law 也隱含著風險。當模型規模與算力投入暴漲到數千億美元級別後,如果算法創新停滯或推理效率下降,投資回報率會迅速塌陷。所以,Dylan 認為,必須在鉅額投入與時間窗口之間精準押注才能成為贏家。如果 Scaling Laws 的回報消失,整個行業可能面臨系統性過度建設的風險。
Scaling Laws 不僅是技術議題,更是資本結構問題。它迫使企業在“模型更大”與“模型更可用”之間做出抉擇:過大模型意味著推理成本高企、延遲難降、用戶體驗下降,而適度規模化則能兼顧效率與可服務性。這種平衡成為當前 AI 工程最核心的挑戰之一
如何平衡 Inference Latency 與 Capacity?
幾乎所有 AI 工程問題都可以理解為是在一條曲線上的權衡,其中 inference latency 與 capacity 是最關鍵的平衡點。比如在硬件層面,GPU 可以在一定範圍內降低延遲,但成本會急劇上升;反之,追求高吞吐量則會犧牲響應速度。企業必須在用戶體驗與資金壓力之間找到平衡點。
Dylan 認為,如果有一個“魔法按鈕”可以同時解決 inference latency 與 capacity 的問題,AI 模型的潛能將被徹底釋放。但現實中,cost 仍是首要約束,推理速度已經足夠快,而算力卻嚴重不足。 即便我們現在能訓練出比 GPT-5 大 10 倍的模型,也無法為這個模型提供穩定的部署。因此,OpenAI 等公司需要思考這樣一個問題:是推出一個人人可用的高速模型,還是發佈一個更強但昂貴的模型?同時,這也意味著,AI 的發展不僅受限於硬件性能,還取決於人類願意接受怎樣的使用體驗。
但模型性能的真正突破並不完全取決於“更大”,單純把模型規模變化會面臨“過參數化(over-parameterization)”的陷阱:當模型規模持續擴大而數據量沒有同步增長時,模型只是在“記憶”數據,而非真正“理解”內容。真正的智能源自 grokking,也就是頓悟式的理解,就像人類從死記硬背到真正領會知識的瞬間。
可交互環境是 RL 發展的新方向
如前文所述,當今的挑戰已不再是如何讓模型更大,而是如何構建更高效的數據與學習環境。過去,人類只是採集並過濾互聯網數據,但互聯網上沒有教人只用鍵盤操作 Excel 的教程,也缺乏關於數據清洗或業務流程的真實訓練素材,模型無法僅憑閱讀互聯網獲取這些能力,因此模型需要新的體驗式學習空間。
為模型構建可交互的環境就是 RL 發展的新方向,這些環境可能是虛擬電商平臺,讓模型學會瀏覽、比較、下單;也可能是數據清洗任務,讓模型可以在無數格式中反覆嘗試、逐步優化;甚至可以是遊戲、數學謎題或醫學案例,模型通過不斷試錯、驗證與反饋,逐步形成真正的理解能力。Dylan 表示,灣區目前已有數十家初創公司專注構建 AI 學習環境。
而且,在 Dylan 看來,當下的 AI 所處的發展階段只是“我們剛投出的一球”。AI 依舊像一個嬰兒,還需要通過不斷的嘗試與失敗來校準感知。就像人類在成長中會遺忘大量無用信息,僅保留少數關鍵經驗,AI 模型也會在訓練中生成大量數據,卻只保留極少部分。因此,要讓模型真正理解世界,必須讓它進入環境中學習。
有些研究者認為,通向 AGI 的關鍵是具身化(embodiment),即讓模型能夠與物理世界互動。這種理解無法通過視頻或文本獲得,而需通過行動與反饋實現,因此 RL 的重要性將持續上升。
值得注意的是,Dylan 認為,在傳統的訓練範式中,AI 是通過數據去“讀懂世界”,而在 post-training 時代,AI 應該在環境中去“創造世界”。如前文所說,模型規模的擴大並不意味著智能的增長。真正的突破來自算法和架構的優化,讓模型能以更少的算力、更高的效率完成學習。因此,雖然 pre-training 依然是 AI 發展的基礎,但 post-training 將成為未來算力消耗的主要來源。
Dylan 表示,隨著 RL 的成熟,AI 將從“回答問題”走向“直接行動”。未來,AI 可能不再只是幫用戶決策,而是能在電商平臺上直接為他們下單。事實上,人類已經在不知不覺中把部分決策外包了 AI,從 Uber Eats 的首頁推薦到 Google Maps 的路線規劃。如今已有跡象顯示這一趨勢正在加速:Etsy超過 10% 的流量直接來自 GPT,如果亞馬遜沒有屏蔽 GPT,這一比例可能更高。OpenAI 的應用團隊也在推進 shopping agent,作為商業化的核心路徑。
而這種“執行智能”也將催生新的商業模式——AI 執行抽成。未來的平臺可能像信用卡體系一樣,從 AI 的執行環節中收取 0.1% 或者 1% 的費用,從而形成巨大的利潤空間。
模型的記憶系統不必模仿人腦
在算力有限的前提下,“推理時間”成為提升模型能力的另一條路徑:在模型規模不變的情況下,通過延長思考步數和推理深度,模型可以獲得顯著性能提升。
Dylan 認為,Transformer 架構的 attention 機制使模型在有限上下文中具備較強的回溯與關聯能力,但在長上下文和稀疏記憶(sparse memory)場景下仍存在明顯瓶頸。隨著上下文窗口不斷擴大,內存與帶寬的壓力急劇上升,HBM已成為支撐大模型推理的關鍵資源。這一趨勢正在驅動新一輪底層創新,未來模型性能的突破將取決於更高效的存儲架構與多芯片互連共享機制,從而緩解當前系統在長上下文處理中的物理限制。
Now, models are amazing. But what they really suck at is having infinite context....This is a big challenge with reasoning. This is why we had this HBM bullish pitch for a while. You need a lot of memory when you extend the context. Simple thesis.——Dylan Patel
但 Dylan 並不認為模型的記憶系統必須模仿人腦,外部寫作空間、數據庫、甚至文檔系統都可以成為模型的外部記憶,關鍵在於讓模型學會如何寫入、提取、複用信息,從而在任務過程中建立長期語義關聯。
OpenAI 的 Deep Research 就是這一理念的實踐。它讓模型能夠在較長時間內持續生成中間文本,不斷進行壓縮與回看,從而完成複雜的分析與創作任務。Dylan 將這一過程形容為“人工推理的顯微鏡”,它展示了 agent 未來可能的工作方式,也就是在長時記憶與短時計算之間持續循環,從而實現真正意義上的“思考”。
Dylan 認為這種新型的推理與記憶框架,將徹底改變算力需求結構。未來的百萬 GPU 集群,不僅用於訓練更大的模型,更用於支撐這些長思考的 agent。
能真正推動硬件創新的仍是巨頭
• 半導體制造(semiconductor manufacturing)
當今的半導體制造的難度已進入“太空時代級別”,成為人類工程中最複雜的系統之一,但背後的軟件體系仍然滯後。即便是一臺價值數億美元的製造設備,仍依賴過時的控制系統和低效的開發工具。
即便英偉達已佔據半導體行業的領先地位,它的供應鏈中仍保留著大量舊時代的部件。以電力系統為例,變壓器的基本工作原理幾十年來幾乎未曾改變。而如今,真正的創新正在發生在固態變壓器上:它們能將超高壓交流電逐級轉換為芯片可用的低壓直流電,大幅提升能源利用效率。正是這些看似傳統的工業環節,正在成為 AI 基礎設施新的利潤與創新源頭。
但 Dylan 並不看好加速器公司(accelerator companies),也就是那些試圖與英偉達、AMD、谷歌 TPU 或亞馬遜 Trainium 競爭的新興芯片公司。在他看來,這個行業資本密集、風險極高、技術創新空間有限。除非出現一次真正突破性的硬件躍遷,否則這些新玩家幾乎不可能撼動現有格局。
•芯片互聯(networking between chips)
隨著模型上下文長度不斷增加,內存需求激增。由於 DRAM行業創新受限,相比之下,反而是在網絡層面更容易取得突破:
1. 通過緊密互連實現芯片間的內存共享,例如英偉達在 Blackwell 架構中的 NVL72 模塊,已將大規模網絡互連能力集成於單一系統,顯著提升了數據交換效率;
2. 光學互連(optics space)仍是關鍵前沿,如何在電信號與光信號之間實現更高效的轉換與傳輸,將直接決定下一代數據中心的性能上限。
3. 在極端性能條件下,Blackwell 的超高帶寬互連也讓系統在可靠性與散熱方面逼近物理極限:同一機架中的每顆芯片都能以每秒 1.8TB 的速率與其他芯片通信。
Dylan 認為,芯片互聯領域仍存在大量創新空間,並對硬件技術的持續進步極度樂觀。但是需要注意的是,產業內部的結構性問題正在阻礙效率:
1. 英特爾落後的部分原因在於內部缺乏數據共享文化,比如光刻團隊與刻蝕團隊往往拒絕共享實驗數據,這些數據也無法上傳至雲端(如 AWS)進行關聯分析,導致整體的學習與迭代效率極低;
2. 臺積電雖在製造能力上更強,但同樣不允許數據外發,實驗與分析流程也很緩慢。
而要打破這一障礙,則需要改變企業文化。比如,陳立武正在推動這種轉變,希望能讓製造企業更加開放地利用自身數據,構建更好的仿真器,並以更高精度模擬現實世界。
• 世界模型(world model)
世界模型(World Model)的核心思想,是讓 AI 具備模擬世界的能力。這一概念不僅適用於軟件層面,也正在向物理層擴展。以 Google 的 Genie 3 為例,模型可以在虛擬環境中自由移動、觀察並與物體互動;而更先進的模型則能夠模擬分子反應、流體動力或火焰燃燒等複雜過程,用 AI 的方式去學習和重構物理規律。
這一領域的公司也正在快速湧現,其中一些專注於機器人訓練,另一些則聚焦在化學和材料的模擬。這類公司使 AI 不再僅僅是語言處理系統,而成為理解和模擬現實的計算框架。受此影響,機器人和物理仿真再次成為近期的創業和投資的焦點。但 Dylan 認為,能真正推動世界模型與硬件創新的,仍是那些巨頭公司:臺積電、英偉達、安費諾等。
But also I think most of the cool innovation is just happening at big companies or already existing companies. ——Dylan Patel
03.AI 算力,人才和能源
算力是工業產能,token 是產品單元
Nvidia 提出的 AI Factory 概念是 AI 行業的經濟學基石。與傳統工廠生產物質產品不同,智能工廠生產的是智能(intelligence),也就是通過算力生成的 token。Dylan 形象打了一個比喻:“一座 AI Factory 輸出的不是電,而是智能本身。”
AI Factory:由 Marco Iansiti 和 Karim R。 Lakhani 於 2020 年在 Competing in the Age of AI 中提出。它指一種專用計算基礎架構,能夠覆蓋整個 AI 生命週期,從數據獲取、訓練、微調,到大規模推理,從而將數據轉化為價值。AI Factory 的核心產品是智能,產出以 token 傳輸量衡量,這些傳輸量推動決策、自動化以及全新的 AI 解決方案。
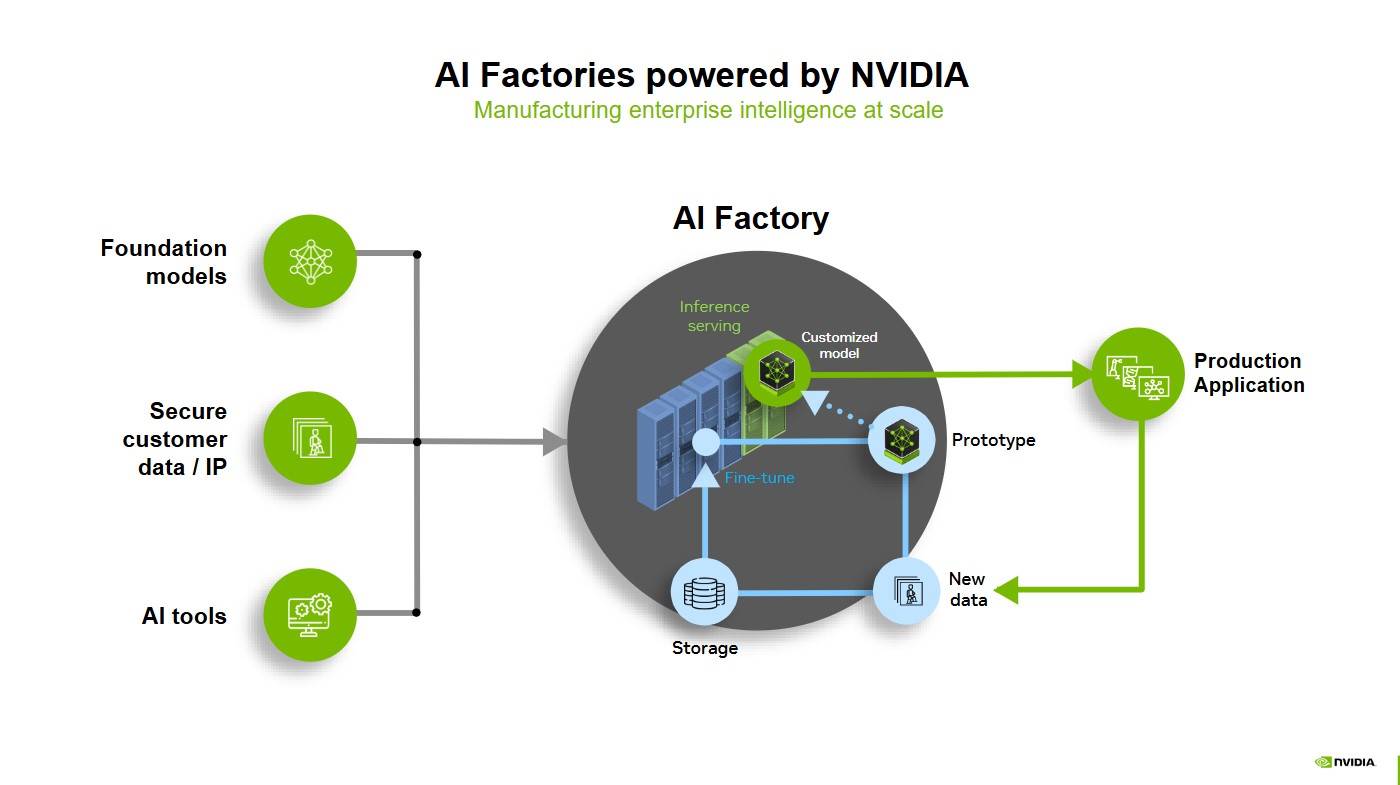
在 AI Factory 的概念下,每個 token 都體現了計算能力、算法效率與能源投入的成果。AI 企業要解決的問題不再是造出最強模型,而是如何在相同功率下實現最優的 token 產能配置。這意味著需要在“多次調用較弱模型”與“少量調用強模型”之間做出權衡。算力分配、模型規模、用戶數量以及推理延遲等因素,共同決定了 AI 工廠的經濟效率。
近兩年來,算法優化顯著降低了模型的服務成本。例如,對於 GPT-3 級別的推理,成本已比兩年前下降約 2000 倍,但成本的下降並沒有帶來 AI 普及速度的提升,因為算力依然是稀缺資源。因此,在 GPT-5 階段,OpenAI 選擇保持與 GPT-4 相近的模型規模和推理成本,來提高“思考模式”下的推理效率,讓更多用戶能夠實際使用,而不是盲目追求更大模型。
Dylan 認為,算力是工業產能,token 是產品單元。未來的競爭不在於誰訓練了最大的模型,而在於誰能以最低的 token 成本提供穩定、可規模化的智能服務。
能高效使用 GPU 的人比 GPU 更稀缺
雖然 GPU 非常稀缺,但更稀缺的是能高效使用 GPU 的人。
每一次無效實驗都意味著大量算力的浪費,因此,能夠將算力利用率提高 5% 的研究者的邊際貢獻在訓練和推理環節都能產生長期複利效應,這種效率提升足以抵消數億美元的設備投資成本。在這種背景下,天價年薪和股權激勵並非市場泡沫,而是一種理性的回報。
需要注意的是,雖然目前行業普遍存在浪費 H100 的現象,但這不是失敗,而是成長的代價。AI 研究的真正瓶頸在於實驗密度與反饋週期,而非理論匱乏。少數頂級研究者提升全局效率的價值,遠高於成千上萬的低效嘗試。
但人才擴張也會帶來副作用。隨著巨頭公司在全球範圍內收購式挖人,大量研究機構出現組織遲滯與算力浪費。Dylan 直言有太多人只會“說”卻不會“做”,規模化挖人往往導致結構性失配,他甚至主張美國應在高端製造與物理化學領域“反向挖人”,將關鍵工藝與實驗知識遷回本土。
美國必須重新掌握髮電能力
AI 的崛起確實帶來了前所未有的能源需求,但實際上,目前數據中心的電力消耗並不算龐大。整個美國的數據中心用電僅佔美國全國總電力的 3%–4%,其中大約一半來自 AI 數據中心。
根據美國能源信息管理局(EIA),2024 年美國的電力消耗為 40860 億千瓦時,預計在 2025 年達到 41650 億千瓦時。按照 1.5%-2%的比例估算,美國 AI 數據中心的 2025 年電力消耗量約為 624-833 億千瓦時。
但目前 AI 數據中心的規模正在迅速擴大,比如 OpenAI 正在建設一座耗電 2 吉瓦的設施,相當於整個費城的電力消耗。在業內,這類規模已逐漸成為常態,甚至不到 1 吉瓦的項目幾乎無人關注。實際上,500 兆瓦的項目就意味著約 250 億美元的資本支出。這樣的擴張速度和體量,遠超以往任何數據中心建設記錄。
因此,目前真正的挑戰不在於用電量過高,而是如何新增發電能力:過去 40 年間,美國能源體系在轉向天然氣後,新增發電能力幾乎停滯,如今重啟發電項目面臨多重障礙,比如監管複雜、勞動力短缺、供應鏈緊張。而且燃氣輪機、變壓器之類的關鍵設備的生產週期長、產能有限,使電廠擴建難度也大幅增加。
此外,模型訓練的高波動負載也在考驗電網。瞬時功率變化會擾亂頻率,造成設備損耗。即使不至於引發斷電,也會讓附近的家用電器提前老化。
Dylan 指出,美國必須重新掌握髮電能力。目前,燃氣機組和雙循環機組正在恢復建設,部分企業甚至用並聯柴油卡車發動機發電。供應鏈也正在重新活躍,比如馬斯克從波蘭進口設備,GE 和三菱宣佈擴大燃機產量,變壓器市場已全面售罄,能夠參與數據中心建設的電工工資幾乎翻倍。Dylan 認為,如果美國有足夠多的電工,這些數據中心能建得更快,但 Google、Amazon、EdgeConneX 等公司的供應鏈差異很大,導致資源非常分散、效率不一。
在監管方面,為了確保算力設施不會影響居民的日常用電,美國電網制定了“強制減少供電”的規定,比如得克薩斯州的 ERCOT 電網和美國東北地區的 PJM 電網在電力供應緊張的時候,電網運營方有權提前 24-72 小時通知大型用電企業,要求它們把用電量削減一半。
因此,為了維持 AI 運算,企業通常被迫啟用自備發電機,包括柴油機、燃氣機甚至氫能發電。但這又帶來了新問題:如果這些發電機持續運行超過法規規定的時間(如 8 小時),就會違反排放許可,觸碰環保紅線。
Dylan 認為,這場變化混亂卻令人振奮。AI 迫使美國重新啟動發電建設,重塑供應鏈,也讓整個國家重新理解電力的意義。
04.AI 讓傳統軟件的行業邏輯失效
今天的軟件領域已與 5-10 年前截然不同,軟件形態和商業模式都在經歷結構性轉變。SaaS 行業的繁榮已進入下行週期:估值倍數在 2021 年 4 月觸頂,2022 年 10 月仍處高位,但增長勢頭從 2021 年 11 月開始已經明顯放緩。
長期以來,SaaS 一直被視為軟件行業中商業邏輯最完善的模式:產品研發成本相對穩定、毛利率極高,公司的主要支出集中在獲客成本(CAC)上。通過削減銷售和管理費用,SaaS 企業可以釋放出可觀的業務現金流。換句話說,當 SaaS 企業的用戶規模達到一定臨界點,即獲客成本被充分攤薄,新增用戶幾乎直接轉化為利潤時,公司便會成為一臺“現金流機器(Cashflow Machine)”。
但這一邏輯成立的前提是:軟件開發本身是一件成本極高的事情。只有當自行開發的代價遠高於購買現成服務時,企業才會選擇以訂閱的方式長期租用軟件服務。
但如今隨著 AI 顯著降低了軟件開發成本,傳統 SaaS 的商業模式正面臨瓦解。比如在中國,軟件開發成本本就不高,中國軟件工程師的薪資大約僅為美國同行的五分之一,但能力還可能更強一倍,這意味著,在中國進行本地化開發的成本遠低於在美國購買或租用 SaaS 服務。因此,許多中國企業更傾向於自建系統或採用本地部署(on-prem),而不是長期訂閱外部 SaaS。這也解釋了為什麼中國的 SaaS 與雲服務滲透率一直顯著低於美國。
如今,AI 工具正在全球範圍內壓低軟件開發成本,讓自建變得越來越便宜。當這種趨勢擴散開來,SaaS 的原來“租比買更划算”的邏輯也將像在中國市場那樣逐漸失效。
此外,SaaS 行業的高獲客成本(CAC)依然普遍存在,而 AI 的興起又進一步抬高了成本結構中的 COGS:
•任何集成了 AI 功能的軟件,它的服務成本(例如每個 token 的計算成本)都會顯著上升;
• 同時,市場上又充斥著藉助 AI 輕鬆自建產品的競爭者,這會導致 SaaS 企業更容易陷入碎片化的市場,或被客戶的內部研發分流;
• 當用戶規模難以持續擴大,企業便難以達到足以攤薄 CAC 與研發支出的逃逸速度(escape velocity);
•在更高的 COGS 約束下,SaaS 公司的淨利潤拐點被迫延後,盈利情況也會逐漸逐漸惡化。
需要注意的是,Google 依然具備潛在的相對優勢。得益於 Google 自研的 TPU 以及垂直一體化的基礎設施體系,Google 在每個 token 的邊際服務成本上顯著低於同行,這使 Google 有機會在 AI 軟件的 COGS 結構中取得成本優勢。但整體上來說,純軟件公司的日子將越來越難,已經具備規模、生態與平臺勢能的企業會繼續佔據優勢。隨著內容生產與生成成本的持續下降,真正掌控平臺的公司將成為最大贏家。比如 YouTube 這樣的超級平臺,反而可能迎來新一輪的高光時刻。
但在具體廠商層面,許多軟件企業都將不得不直面同一個現實:COGS 上升、CAC 居高不下、競爭者急劇增加。隨著功能“買不如造”的門檻不斷降低,企業原有的競爭優勢被迅速壓縮,增長飛輪也難以重新啟動。這場“軟件清算”不僅源於 AI 帶來的技術衝擊,更是商業結構與成本結構聯動變化的結果。
05.對 AI 玩家的快評
• OpenAI:頂級優秀的公司
• Anthropic:Dylan 對 Anthropic 的看法甚至比對 OpenAI 更樂觀
Anthropic 的收入增長明顯更快,因為它專注的方向與價值約 2 萬億美元的軟件市場緊密相關。相比之下,OpenAI 的佈局較為分散,同時推進企業軟件、AI 科研、消費者應用以及平臺抽成等多條路線。雖然這些業務都具有潛力,但在執行上,Anthropic 更加穩健與聚焦,也更符合當前市場需求。
• AMD:
AMD 長期 Intel 和 Nvidia 抗衡,扮演著友善的挑戰者角色,這種“弱者精神”讓人難以不喜歡。而且,AMD 是 Dylan 人生中第一個十倍股的案例。作為一個從小熱愛組裝電腦的人,Dylan 對 AMD 這種“逆襲者”公司一直懷有好感。
• xAI:存在無法持續融資的風險
儘管馬斯克個人能夠吸引資金,但要維持與頂級競爭者相當的算力水平,所需資本規模非常龐大。xAI 正在建設名為“Colossus 2”的超級數據中心,建成後,它將成為全球最大的單體數據中心,可以部署 30 萬到 50 萬顆 Blackwell GPU。雖然這樣的基礎設施令人震撼,但公司在商業化上一直沒有找到合適的模式。當前唯一的產品 Grok 並未得到理想變現。
在 Dylan 看來,xAI 完全可以把 Grok 商業化做得更好,比如通過個性化內容、虛擬人物或訂閱互動模式增加收入,甚至可以與 OnlyFans 合作,將創作者數字化形象整合到 X 生態中,形成真正的超級應用。
總的來說,xAI 雖有出色的團隊與計算能力,但除非在商業和產品層面做出突破,否則會在競爭中掉隊。馬斯克的意志和資金可以支撐一個階段,但如果沒有可持續收入,即便他是世界首富,也無法獨力負擔一個 3 吉瓦級數據中心的長期投入。
• Meta:手中握有可能可以統治一切的牌
Dylan 特別提到 Meta 新推出的智能眼鏡,認為這標誌著人機交互方式的又一次革命。從打孔卡到命令行、從圖形界面到觸控屏,人機界面不斷演進,下一階段將是無接觸交互:用戶只需對 AI 說出需求,它便能直接執行,如發送郵件、下單購物等。
而 Meta 是唯一擁有完整體系的公司,即既有硬件(智能眼鏡),也有強大的模型能力、算力供應能力,以及業界領先的推薦算法系統。這四者疊加,再加上充足的資金,讓 Meta 有潛力成為這一代人機接口的主導者。
• Google:在兩年前還對 Google 相當悲觀,今天則非常看好
Dylan 認為 Google 在多個層面已徹底覺醒:開始對外銷售 TPU,積極推進 AI 模型的商業化,並在訓練和基礎設施投資方面展現出更強的進取心。
儘管 Google 內部仍存在一些低效和官僚問題,但 Google 擁有獨特的硬件基礎,可在 AI 時代靈活轉型。雖然在硬件體驗上可能不如 Meta 或 Apple,但 Google 有 Android、YouTube、搜索等龐大生態,一旦人機交互進入新階段,這些資產能被重新整合。在 Dylan 看來,Meta 可能在消費市場領先,但在專業與企業級應用方面,Google 更具潛力。
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News













