

Thực tế kiểm thử 7 mô hình AI lớn chủ lưu, rò rỉ thông tin cá nhân thành vấn đề phổ biến
Tuyển chọn TechFlowTuyển chọn TechFlow
Thực tế kiểm thử 7 mô hình AI lớn chủ lưu, rò rỉ thông tin cá nhân thành vấn đề phổ biến
Hy vọng các nhà sản xuất mô hình lớn có thể tích cực hưởng ứng, chủ động tối ưu hóa thiết kế sản phẩm và chính sách bảo mật, bằng thái độ cởi mở và minh bạch hơn, rõ ràng giải thích cho người dùng về nguồn gốc và quá trình xử lý dữ liệu, để người dùng có thể yên tâm sử dụng công nghệ mô hình lớn.
Tác giả: Tư Nguyên,TechFlow

Hình ảnh: Được tạo bởi AI Vô Giới
Trong thời đại AI, thông tin người dùng nhập vào không còn chỉ thuộc về quyền riêng tư cá nhân, mà đã trở thành "bậc thang" giúp các mô hình lớn phát triển.
"Giúp tôi làm một bản trình chiếu PowerPoint", "Giúp tôi thiết kế một poster chào xuân", "Tóm tắt nội dung tài liệu này giúp tôi"... Kể từ khi các mô hình lớn bùng nổ, việc sử dụng công cụ AI để nâng cao hiệu suất đã trở thành thói quen hàng ngày của dân văn phòng, thậm chí nhiều người bắt đầu dùng AI đặt đồ ăn, đặt khách sạn.
Tuy nhiên, cách thức thu thập và sử dụng dữ liệu này cũng mang đến rủi ro bảo mật riêng tư rất lớn. Nhiều người dùng bỏ qua một vấn đề chính trong thời đại số hóa – thiếu minh bạch khi sử dụng các công nghệ và công cụ kỹ thuật số. Họ không rõ dữ liệu của mình được thu thập, xử lý và lưu trữ như thế nào, cũng không chắc liệu dữ liệu có bị lạm dụng hay rò rỉ hay không.
Vào tháng 3 năm nay, OpenAI thừa nhận ChatGPT tồn tại lỗ hổng khiến một phần lịch sử trò chuyện của người dùng bị rò rỉ. Sự cố này đã làm dấy lên lo ngại của công chúng về an toàn dữ liệu mô hình lớn và bảo vệ quyền riêng tư cá nhân. Ngoài sự kiện rò rỉ dữ liệu ChatGPT, mô hình AI của Meta cũng vướng phải tranh cãi vì vi phạm bản quyền. Tháng 4 năm nay, các tổ chức nhà văn, nghệ sĩ tại Mỹ cáo buộc mô hình AI của Meta lấy cắp tác phẩm của họ để huấn luyện mô hình, xâm phạm bản quyền của họ.
Tương tự, ở Trung Quốc cũng xảy ra sự kiện tương tự. Gần đây, iQiyi và công ty Xí Vũ (MiniMax), một trong "sáu con hổ nhỏ mô hình lớn", gây chú ý do tranh chấp bản quyền. iQiyi cáo buộc Hải Loa AI sử dụng trái phép tài nguyên bản quyền của họ để huấn luyện mô hình. Đây là vụ kiện xâm phạm quyền sở hữu trí tuệ đầu tiên tại Trung Quốc giữa một nền tảng video và mô hình AI tạo video.
Những sự kiện này đã thu hút sự chú ý của dư luận về nguồn dữ liệu huấn luyện mô hình lớn và các vấn đề liên quan đến bản quyền, cho thấy rằng sự phát triển công nghệ AI cần được xây dựng trên cơ sở bảo vệ quyền riêng tư người dùng.
Để tìm hiểu mức độ minh bạch hiện tại trong việc công bố thông tin của các mô hình lớn nội địa, TechFlow đã chọn 7 sản phẩm mô hình lớn phổ biến trên thị trường gồm Đậu Đỗ, Văn Tâm Nhất Ngôn, Kimi, Hỗn Nguyên Tencent, Tinh Hỏa Mô Hình, Thông Nghĩa Thiên Văn, Khai Tư Khả Linh làm mẫu nghiên cứu, thực hiện đánh giá thông qua chính sách bảo mật, thỏa thuận người dùng và trải nghiệm thiết kế chức năng sản phẩm. Kết quả cho thấy nhiều sản phẩm chưa làm tốt ở khía cạnh này, đồng thời chúng tôi cũng nhìn rõ mối quan hệ nhạy cảm giữa dữ liệu người dùng và sản phẩm AI.
01. Quyền rút lại gần như vô hiệu
Đầu tiên, từ trang đăng nhập, TechFlow dễ dàng nhận thấy cả 7 sản phẩm mô hình lớn nội địa đều áp dụng "tiêu chuẩn bắt buộc" của ứng dụng Internet là Thỏa thuận Sử dụng và Chính sách Bảo mật, đồng thời đều dành các mục riêng trong văn bản chính sách bảo mật để giải thích với người dùng cách thu thập và sử dụng thông tin cá nhân.
Các sản phẩm này đều đưa ra lời lẽ tương tự nhau: "Để tối ưu và cải thiện trải nghiệm dịch vụ, chúng tôi có thể kết hợp phản hồi của người dùng đối với nội dung đầu ra và các vấn đề gặp phải trong quá trình sử dụng nhằm cải thiện dịch vụ. Dưới điều kiện xử lý bằng công nghệ mã hóa an toàn, loại bỏ định danh nghiêm ngặt, chúng tôi có thể phân tích dữ liệu người dùng nhập vào AI, chỉ dẫn phát ra, câu trả lời được AI tạo ra tương ứng, tình trạng truy cập và sử dụng sản phẩm của người dùng, và dùng cho việc huấn luyện mô hình."
Thực tế, việc dùng dữ liệu người dùng để huấn luyện sản phẩm, sau đó cải tiến sản phẩm tốt hơn phục vụ người dùng, dường như là một vòng tuần hoàn tích cực. Nhưng vấn đề người dùng quan tâm là liệu họ có quyền từ chối hoặc rút lại việc "nuôi dữ liệu" cho AI huấn luyện hay không.
Sau khi đọc kỹ và kiểm tra thực tế 7 sản phẩm AI này, TechFlow phát hiện chỉ có Đậu Đỗ, Tuyết Phi, Thông Nghĩa Thiên Vấn và Khả Linh là 4 trong số đó đề cập trong điều khoản bảo mật về khả năng "thay đổi phạm vi sản phẩm tiếp tục thu thập thông tin cá nhân hoặc rút lại ủy quyền".
Trong đó, Đậu Đỗ chủ yếu tập trung vào việc rút lại ủy quyền thông tin giọng nói. Chính sách ghi rõ: "Nếu bạn không muốn thông tin giọng nói bạn nhập hoặc cung cấp được dùng để huấn luyện và tối ưu mô hình, bạn có thể tắt 'Cài đặt' - 'Cài đặt tài khoản' - 'Cải thiện dịch vụ giọng nói' để rút lại ủy quyền của bạn"; tuy nhiên đối với các thông tin khác, người dùng phải liên hệ với ban quản trị qua thông tin liên lạc được công bố mới có thể yêu cầu ngừng sử dụng dữ liệu cho việc huấn luyện và tối ưu mô hình.

Nguồn ảnh/(Đậu Đỗ)
Trong thực tế vận hành, việc tắt ủy quyền dịch vụ giọng nói không quá khó khăn, nhưng đối với việc rút lại việc sử dụng các thông tin khác, sau khi liên hệ với ban quản trị Đậu Đỗ, TechFlow vẫn chưa nhận được phản hồi.
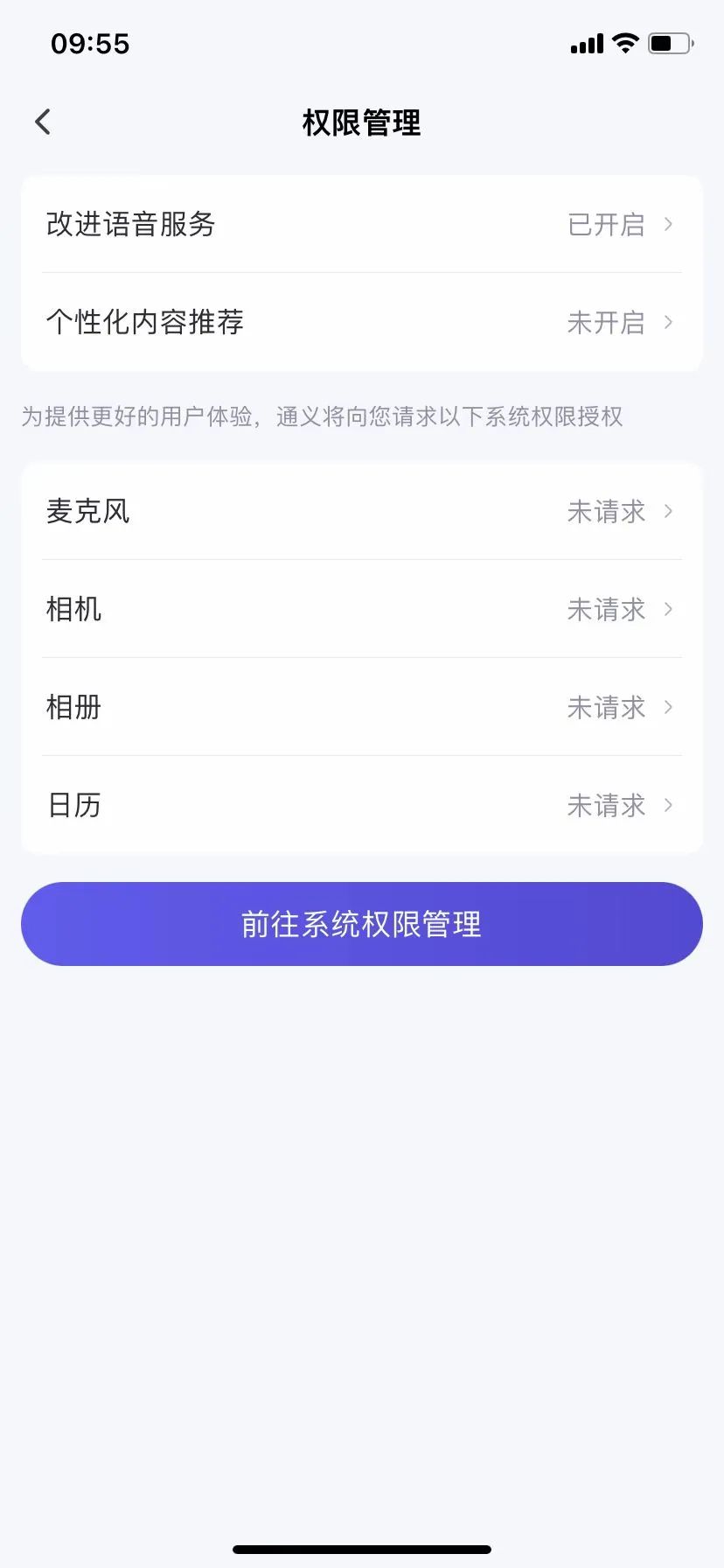
Nguồn ảnh/(Đậu Đỗ)
Thông Nghĩa Thiên Vấn tương tự Đậu Đỗ, người dùng chỉ có thể tự thao tác rút lại ủy quyền đối với dịch vụ giọng nói; còn đối với các thông tin khác, cũng phải liên hệ với ban quản trị qua thông tin liên lạc đã công bố để thay đổi hoặc thu hồi phạm vi thu thập và xử lý thông tin cá nhân.

Nguồn ảnh/(Thông Nghĩa Thiên Vấn)
Khả Linh, với tư cách là nền tảng tạo video và hình ảnh, nhấn mạnh đặc biệt về việc sử dụng khuôn mặt, tuyên bố sẽ không dùng thông tin pixel khuôn mặt của bạn cho bất kỳ mục đích nào khác hoặc chia sẻ với bên thứ ba. Tuy nhiên, nếu muốn hủy ủy quyền, người dùng phải gửi email liên hệ với ban quản trị để hủy bỏ.

Nguồn ảnh/(Khả Linh)
So với Đậu Đỗ, Thông Nghĩa Thiên Văn và Khả Linh, Tuyết Phi Tinh Hỏa đặt điều kiện khắt khe hơn: theo điều khoản, nếu người dùng muốn thay đổi hoặc rút lại phạm vi thu thập thông tin cá nhân, họ phải thực hiện bằng cách hủy tài khoản.

Nguồn ảnh/(Tuyết Phi Tinh Hỏa)
Đáng chú ý, mặc dù Tencent Nguyên Bảo không đề cập trong điều khoản cách thay đổi ủy quyền thông tin, nhưng trong ứng dụng, chúng ta có thể thấy công tắc "Kế hoạch cải thiện chức năng giọng nói".

Nguồn ảnh/(Tencent Nguyên Bảo)
Còn Kimi, dù trong điều khoản bảo mật có nhắc đến việc có thể hủy chia sẻ thông tin giọng nói với bên thứ ba và có thể thực hiện thao tác tương ứng trong ứng dụng, nhưng sau nhiều lần thử nghiệm, TechFlow vẫn không tìm thấy nơi thay đổi. Còn các thông tin dạng văn bản khác thì hoàn toàn không thấy điều khoản liên quan.

Nguồn ảnh/(Điều khoản bảo mật Kimi)
Thực tế, từ vài ứng dụng mô hình lớn phổ biến, có thể thấy các công ty đều coi trọng hơn việc quản lý giọng nói người dùng; Đậu Đỗ, Thông Nghĩa Thiên Văn... đều có thể tự thao tác hủy ủy quyền. Đối với các quyền cơ bản như vị trí, camera, micrô trong các tình huống tương tác cụ thể, người dùng cũng có thể tự tắt, nhưng việc rút lại dữ liệu "nuôi" cho AI thì các hãng đều làm chưa trơn tru.
Đáng chú ý, các mô hình lớn nước ngoài cũng có cách làm tương tự về "cơ chế người dùng rút dữ liệu khỏi việc huấn luyện AI". Các điều khoản liên quan Gemini của Google quy định: "Nếu bạn không muốn chúng tôi xem xét các cuộc trò chuyện tương lai hoặc sử dụng các cuộc trò chuyện liên quan để cải thiện công nghệ học máy của Google, hãy tắt nhật ký hoạt động Gemini."
Bên cạnh đó, Gemini cũng nêu rõ: khi bạn xóa nhật ký hoạt động ứng dụng của mình, hệ thống sẽ không xóa nội dung cuộc trò chuyện đã được kiểm duyệt hoặc ghi chú bởi nhân viên (cũng như các dữ liệu liên quan như ngôn ngữ, loại thiết bị, thông tin vị trí hoặc phản hồi), vì những nội dung này được lưu riêng biệt và không liên kết với tài khoản Google. Những nội dung này sẽ được lưu trữ tối đa ba năm.
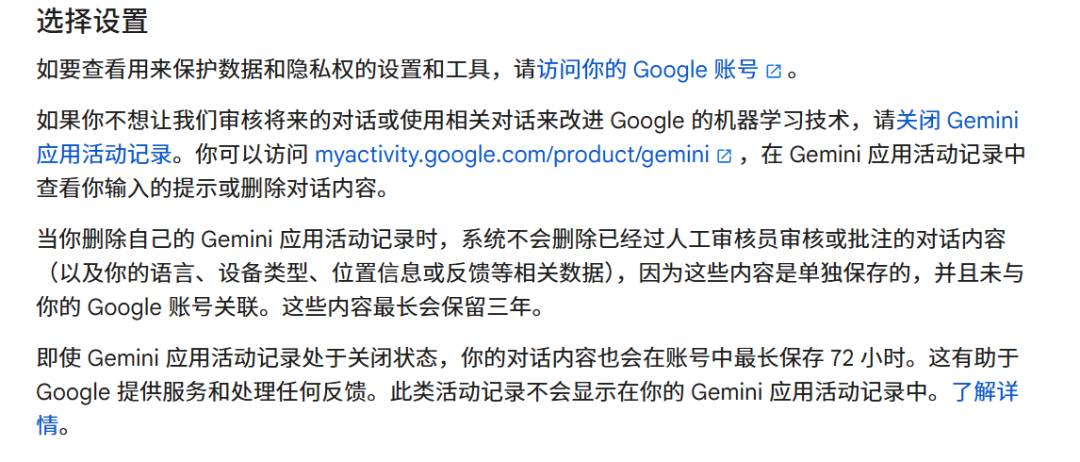
Nguồn ảnh/(Điều khoản Gemini)
Quy tắc của ChatGPT khá mơ hồ, cho biết người dùng "có thể có quyền hạn chế việc xử lý dữ liệu cá nhân", nhưng trong thực tế sử dụng, người dùng Plus có thể chủ động thiết lập tắt việc dùng dữ liệu để huấn luyện; còn người dùng miễn phí thì dữ liệu thường bị thu thập mặc định và dùng để huấn luyện, người dùng muốn từ chối phải gửi thư cho ban quản trị.

Nguồn ảnh/(Điều khoản ChatGPT)
Thực tế, từ các điều khoản của các sản phẩm mô hình lớn này, chúng ta dễ dàng nhận thấy việc thu thập thông tin người dùng dường như đã trở thành sự đồng thuận. Tuy nhiên, đối với các thông tin riêng tư hơn như giọng nói, khuôn mặt – các thông tin sinh trắc học – chỉ một vài nền tảng đa phương tiện có đề cập.
Nhưng đây không phải do thiếu kinh nghiệm, nhất là với các tập đoàn Internet lớn. Ví dụ, điều khoản bảo mật WeChat liệt kê chi tiết từng trường hợp cụ thể thu thập dữ liệu, mục đích và phạm vi, thậm chí cam kết rõ ràng "không thu thập nhật ký trò chuyện của người dùng". TikTok cũng vậy, hầu hết thông tin người dùng tải lên đều được quy định rõ cách sử dụng, mục đích sử dụng trong điều khoản bảo mật.

Nguồn ảnh/(Điều khoản bảo mật TikTok)
Hành vi thu thập dữ liệu từng bị kiểm soát chặt chẽ trong thời đại mạng xã hội Internet, nay trong thời đại AI lại trở thành điều bình thường. Thông tin người dùng nhập vào đã bị các nhà sản xuất mô hình lớn tự do thu thập dưới khẩu hiệu "tài liệu huấn luyện", dữ liệu người dùng không còn được coi là quyền riêng tư cá nhân cần xử lý nghiêm ngặt, mà trở thành "bậc thang" cho sự tiến bộ mô hình.
Ngoài dữ liệu người dùng, đối với các mô hình lớn, tính minh bạch của tài liệu huấn luyện cũng rất quan trọng. Việc tài liệu này có hợp pháp, có cấu thành vi phạm bản quyền hay không, có tiềm ẩn rủi ro gì đối với người dùng hay không, đều là những vấn đề cần quan tâm. Chúng tôi带着 nghi vấn đi sâu tìm hiểu, đánh giá 7 sản phẩm mô hình lớn này, kết quả khiến chúng tôi vô cùng ngạc nhiên.
02. Nguy cơ tiềm ẩn từ việc "nuôi dữ liệu" huấn luyện
Việc huấn luyện mô hình lớn ngoài sức mạnh tính toán, còn cần tài liệu chất lượng cao, tuy nhiên những tài liệu này thường chứa các tác phẩm đa dạng như văn bản, hình ảnh, video được bảo hộ bản quyền, việc sử dụng trái phép rõ ràng sẽ cấu thành vi phạm.
Sau khi kiểm tra thực tế, TechFlow phát hiện cả 7 sản phẩm mô hình lớn đều không đề cập trong thỏa thuận về nguồn cụ thể của dữ liệu huấn luyện mô hình, càng không công khai dữ liệu bản quyền.

Lý do tất cả đều "ăn ý" không công khai tài liệu huấn luyện khá đơn giản: một mặt, việc sử dụng dữ liệu không đúng cách dễ dẫn đến tranh chấp bản quyền, trong khi việc các công ty AI dùng sản phẩm bản quyền làm tài liệu huấn luyện có hợp pháp hay không hiện vẫn chưa có quy định cụ thể; mặt khác, có thể liên quan đến cạnh tranh giữa các doanh nghiệp – việc công khai tài liệu huấn luyện giống như công ty thực phẩm tiết lộ nguyên liệu cho đối thủ, đối thủ có thể nhanh chóng sao chép, nâng cao chất lượng sản phẩm.
Đáng chú ý, hầu hết các mô hình đều đề cập trong chính sách thỏa thuận rằng họ sẽ sử dụng thông tin thu được sau tương tác giữa người dùng và mô hình lớn cho việc tối ưu mô hình và dịch vụ, nghiên cứu liên quan, quảng bá thương hiệu, marketing, khảo sát người dùng, v.v.
Thẳng thắn mà nói, do chất lượng dữ liệu người dùng không đồng đều, độ sâu bối cảnh không đủ, hiệu ứng biên tế,... nên dữ liệu người dùng khó có thể nâng cao năng lực mô hình, thậm chí có thể gây thêm chi phí làm sạch dữ liệu. Tuy nhiên, giá trị của dữ liệu người dùng vẫn tồn tại. Chỉ là chúng không còn là chìa khóa nâng cao năng lực mô hình, mà trở thành con đường mới để doanh nghiệp thu lợi nhuận. Bằng cách phân tích cuộc trò chuyện người dùng, doanh nghiệp có thể hiểu hành vi người dùng, khám phá các kịch bản kiếm tiền, tùy chỉnh chức năng thương mại, thậm chí chia sẻ thông tin với nhà quảng cáo. Và những điều này đều phù hợp với quy tắc sử dụng sản phẩm mô hình lớn.
Tuy nhiên, cũng cần lưu ý rằng dữ liệu được tạo ra trong quá trình xử lý thời gian thực sẽ được tải lên đám mây để xử lý, đồng thời cũng được lưu trữ trên đám mây. Mặc dù hầu hết các mô hình lớn đều nêu trong thỏa thuận bảo mật rằng họ sử dụng công nghệ mã hóa không thấp hơn tiêu chuẩn ngành, xử lý ẩn danh và các biện pháp khả thi khác để bảo vệ thông tin cá nhân, nhưng hiệu quả thực tế của các biện pháp này vẫn còn đáng lo.
Ví dụ, nếu dùng nội dung người dùng nhập vào làm tập dữ liệu, có thể một thời gian sau khi người khác hỏi mô hình lớn nội dung liên quan, sẽ gây rủi ro rò rỉ thông tin; ngoài ra, nếu đám mây hoặc sản phẩm bị tấn công, liệu có thể khôi phục thông tin gốc thông qua kỹ thuật liên kết hoặc phân tích hay không – đây cũng là điểm tiềm ẩn rủi ro.
Ủy ban Bảo vệ Dữ liệu châu Âu (EDPB) gần đây đã ban hành hướng dẫn về bảo vệ dữ liệu cá nhân khi mô hình AI xử lý dữ liệu cá nhân. Hướng dẫn nhấn mạnh rõ ràng rằng tính ẩn danh của mô hình AI không thể được xác lập chỉ bằng một tuyên bố trên giấy, mà phải được đảm bảo thông qua kiểm chứng kỹ thuật nghiêm ngặt và giám sát liên tục. Ngoài ra, hướng dẫn cũng nhấn mạnh, doanh nghiệp không chỉ phải chứng minh tính cần thiết của hoạt động xử lý dữ liệu, mà còn phải chứng minh họ đã áp dụng phương pháp ít xâm phạm quyền riêng tư cá nhân nhất trong quá trình xử lý.

Vì vậy, khi các công ty mô hình lớn thu thập dữ liệu với lý do "để nâng cao hiệu suất mô hình", chúng ta cần cảnh giác suy nghĩ xem đây là điều kiện cần thiết cho sự tiến bộ mô hình, hay là sự lạm dụng dữ liệu người dùng vì mục đích thương mại của doanh nghiệp.
03. Khu vực mờ trong an toàn dữ liệu
Ngoài các ứng dụng mô hình lớn thông thường, sự xuất hiện của các tác nhân thông minh (agent) và AI ở thiết bị đầu cuối (end-side AI) mang đến rủi ro rò rỉ riêng tư phức tạp hơn.
So với các công cụ AI như chatbot, các tác nhân thông minh và end-side AI khi sử dụng cần thu thập thông tin cá nhân chi tiết và có giá trị hơn. Trước đây, điện thoại di động chủ yếu thu thập thông tin thiết bị và ứng dụng người dùng, thông tin nhật ký, quyền truy cập cấp thấp,...; trong bối cảnh end-side AI và công nghệ chủ yếu dựa trên đọc màn hình và ghi màn hình hiện nay, ngoài các quyền thông tin toàn diện nói trên, tác nhân thông minh đầu cuối còn có thể thu được file ghi màn hình, và tiếp tục phân tích bằng mô hình để lấy được các thông tin nhạy cảm như danh tính, vị trí, thanh toán, v.v.
Ví dụ, trước đây Honor đã minh họa cảnh đặt đồ ăn tại buổi ra mắt sản phẩm, lúc này thông tin vị trí, thanh toán, sở thích,... đều bị ứng dụng AI âm thầm đọc và ghi lại, làm tăng rủi ro rò rỉ riêng tư cá nhân.

Theo phân tích trước đây của "Viện Nghiên cứu Tencent", trong hệ sinh thái Internet di động, các ứng dụng trực tiếp cung cấp dịch vụ cho người tiêu dùng thường được coi là bên kiểm soát dữ liệu, chịu trách nhiệm tương ứng về bảo vệ riêng tư và an toàn dữ liệu trong các bối cảnh dịch vụ như thương mại điện tử, mạng xã hội, di chuyển. Tuy nhiên, khi tác nhân AI ở thiết bị đầu cuối hoàn thành nhiệm vụ cụ thể dựa trên khả năng dịch vụ của ứng dụng, ranh giới trách nhiệm về an toàn dữ liệu giữa nhà sản xuất thiết bị và nhà cung cấp dịch vụ ứng dụng trở nên mờ nhạt.
Các nhà sản xuất thường lấy lý do "cung cấp dịch vụ tốt hơn" để biện minh, nhưng xét trên quy mô toàn ngành, điều này không phải là "lý do chính đáng". Apple Intelligence đã tuyên bố rõ ràng rằng đám mây của họ sẽ không lưu trữ dữ liệu người dùng, đồng thời sử dụng nhiều biện pháp kỹ thuật để ngăn chặn mọi tổ chức, kể cả Apple, truy cập dữ liệu người dùng, từ đó giành được sự tin tưởng của người dùng.
Không thể phủ nhận, các mô hình lớn hiện nay đang tồn tại nhiều vấn đề cấp bách về độ minh bạch. Dù là việc rút lại dữ liệu người dùng khó khăn, nguồn tài liệu huấn luyện không minh bạch, hay rủi ro riêng tư phức tạp do tác nhân thông minh và end-side AI mang lại, đều đang từng bước xói mòn nền tảng niềm tin của người dùng đối với mô hình lớn.

Mô hình lớn, với tư cách là lực lượng then chốt thúc đẩy quá trình số hóa, việc nâng cao độ minh bạch là nhiệm vụ cấp thiết. Điều này không chỉ liên quan đến an toàn thông tin cá nhân và bảo vệ quyền riêng tư của người dùng, mà còn là yếu tố cốt lõi quyết định liệu ngành công nghiệp mô hình lớn có thể phát triển lành mạnh, bền vững hay không.
Trong tương lai, mong rằng các nhà sản xuất mô hình lớn có thể tích cực phản hồi, chủ động tối ưu hóa thiết kế sản phẩm và chính sách bảo mật, với thái độ cởi mở, minh bạch hơn, giải thích rõ ràng cho người dùng về nguồn gốc và quá trình xử lý dữ liệu, để người dùng có thể yên tâm sử dụng công nghệ mô hình lớn. Đồng thời, các cơ quan quản lý cũng cần nhanh chóng hoàn thiện luật pháp và quy định liên quan, làm rõ quy tắc sử dụng dữ liệu và ranh giới trách nhiệm, tạo ra môi trường phát triển vừa đầy sáng tạo vừa an toàn, trật tự cho ngành mô hình lớn, giúp mô hình lớn thực sự trở thành công cụ mạnh mẽ phục vụ nhân loại.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News













