

7つの主要AI大規模モデルを実測、プライバシー保護の欠如が共通の問題に
TechFlow厳選深潮セレクト
7つの主要AI大規模モデルを実測、プライバシー保護の欠如が共通の問題に
各大モデル企業には、製品設計やプライバシーポリシーの自主的な最適化に積極的に取り組み、よりオープンで透明性の高い姿勢によりユーザーに対してデータの収集・利用の経緯を明確に説明し、ユーザーが安心して大規模モデル技術を利用できるようになってほしい。
著者:思原、TechFlow

画像出典:無界AIが生成
AI時代において、ユーザーが入力する情報はもはや個人のプライバシーにとどまらず、大規模モデルの進歩のための「足掛かり」となっている。
「PPTを作成してほしい」「新春ポスターを一版作ってほしい」「ドキュメントの内容を要約してほしい」——大規模モデルが注目を集めて以降、AIツールを使って業務効率を高めることがホワイトカラーの日常業務となり、中にはAIで出前を頼んだりホテルを予約したりする人も現れている。
しかし、このようなデータ収集・利用の方法は、大きなプライバシー上のリスクを伴っている。多くのユーザーは、デジタル技術やツールを利用する際の主な問題の一つである「透明性の欠如」に気づいていない。つまり、これらのAIツールがどのようにデータを収集・処理・保存しているのかを理解しておらず、データが悪用されたり漏洩したりしていないか不確かなのである。
今年3月、OpenAIはChatGPTに脆弱性があり、一部ユーザーのチャット履歴が漏洩したことを認めた。この事件は、大規模モデルにおけるデータセキュリティと個人情報保護への懸念を引き起こした。ChatGPTのデータ漏洩事件以外にも、MetaのAIモデルは著作権侵害で批判を浴びている。今年4月、米国の作家やアーティストらの団体が、MetaのAIモデルが許可なく彼らの作品を使用して学習しており、著作権を侵害していると訴えた。
同様に中国国内でも同様の事例が発生している。最近、爱奇艺(アイチイ)と「大規模モデルの六小虎」の一つである稀宇科技(MiniMax)が著作権紛争を巡って注目された。爱奇艺は海螺AIが許可なく自社の著作物素材を使用してモデルを学習させたとして提訴しており、これは中国国内で初めての動画プラットフォームによるAI動画大規模モデルに対する知的財産権侵害訴訟である。
こうした事例は、大規模モデルの学習データの出所や著作権問題への関心を高めている。AI技術の発展は、ユーザーのプライバシー保護を基盤とする必要があるということを示している。
現在の中国製大規模モデルの情報開示の透明性を把握するため、「TechFlow」は豆包、文心一言、kimi、腾讯混元、星火大模型、通義千問、快手可霊の7つの主流大規模モデル製品を対象に、プライバシーポリシーおよび利用規約の評価、製品機能設計の体験を通じて実測を行った。その結果、多くの製品がこの点で十分ではないことが明らかになり、ユーザーのデータとAI製品との間に存在する敏感な関係も明確になった。
01. 撤回権は形骸化
まず、「TechFlow」はログインページから明確に確認できるが、7つの中国製大規模モデル製品はいずれもインターネットアプリの「標準装備」となる利用規約およびプライバシーポリシーを踏襲しており、それぞれのプライバシーポリシー内に異なる章を設けて、ユーザーに対して個人情報をどのように収集・使用するかを説明している。
また、これらの製品の記述も基本的に一致しており、「サービス体験の最適化および改善のために、ユーザーが出力内容に対して行ったフィードバックや利用中に遭遇した問題を組み合わせてサービスを改善する可能性がある。安全な暗号化技術により処理され、厳密に匿名化された前提のもとで、ユーザーがAIに入力したデータ、発した指示、AIが生成した応答、製品へのアクセスおよび使用状況を分析し、モデル訓練に活用する可能性がある」とされている。
実際にユーザーのデータを利用して製品を訓練し、それを改良して再びユーザーに提供することは一見正の循環のように見えるが、ユーザーが関心を持つのは、AI訓練へのデータ「投入」を拒否または撤回できる権利があるかどうかという点である。
「TechFlow」がこれら7つのAI製品の規約を精査し、実際の操作テストを行ったところ、豆包、訊飛、通義千問、可霊の4社のみがプライバシーポリシーにおいて「製品が個人情報を継続的に収集する範囲を変更したり、同意を撤回したりする」ことができる旨を言及していた。
そのうち、豆包は主に音声情報に関する同意の撤回に焦点を当てており、ポリシーには「あなたが入力または提供した音声情報をモデル訓練および最適化に使用することを希望しない場合、『設定』→『アカウント設定』→『音声サービスの改善』をオフにすることで同意を撤回できます」と記載されている。ただし、他の情報については、公表されている連絡先を通じて公式に連絡しなければ、データの使用を撤回するよう要求できない。

図出典/(豆包)
実際に操作してみると、音声サービスの同意をオフにするのはそれほど難しくないが、他の情報の使用撤回に関しては、「TechFlow」が豆包の公式に連絡しても一向に返信が得られなかった。
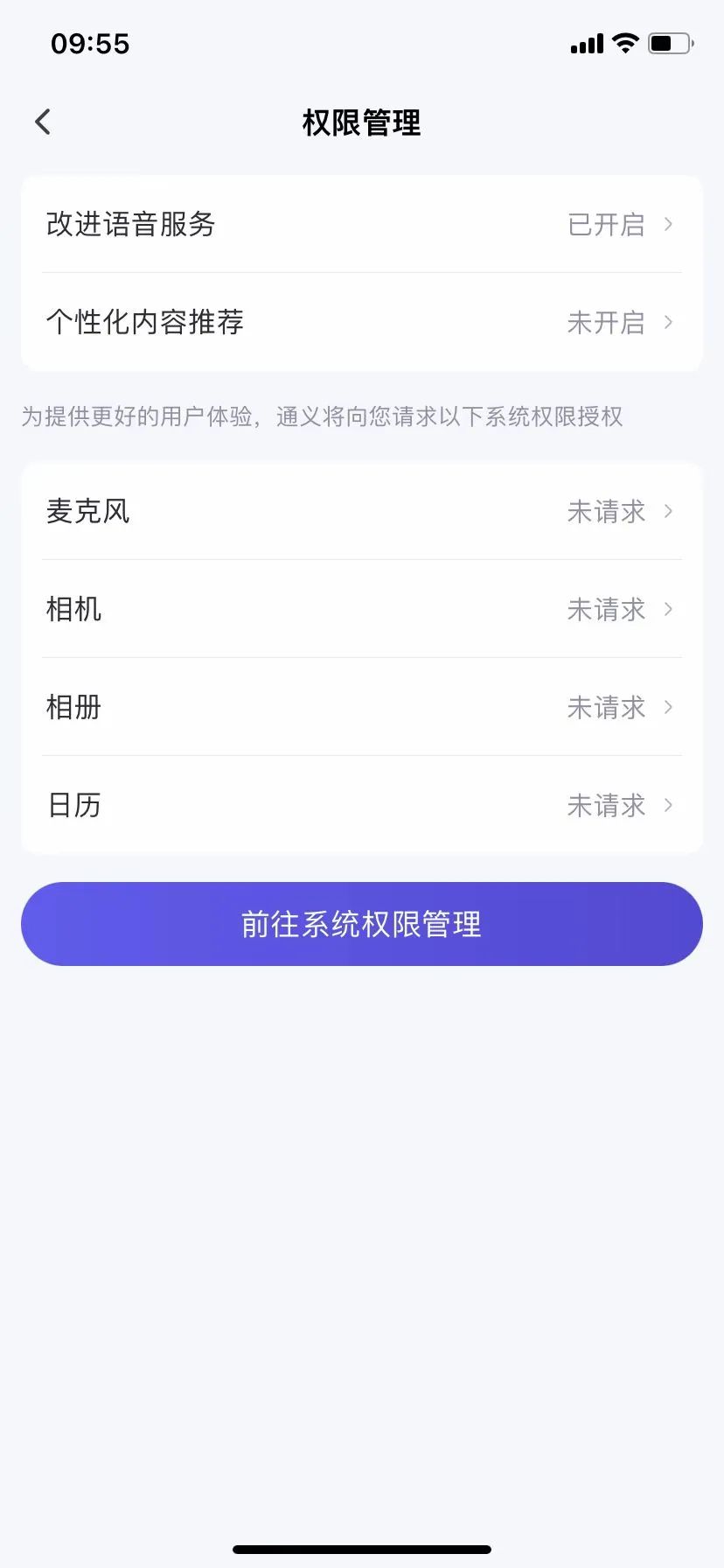
図出典/(豆包)
通義千問も豆包と同様で、ユーザー自身が操作できるのは音声サービスに関する同意の撤回のみであり、他の情報については、公開されている連絡先を通じて公式に連絡して、個人情報の収集および処理範囲を変更または取り消す必要がある。

図出典/(通義千問)
可霊は映像および画像生成プラットフォームとして、顔情報の使用について特に強調しており、「あなたの顔のピクセル情報を他の目的に使用したり、第三者と共有したりすることはありません」と述べている。ただし、同意を取り消したい場合は、メールで公式に連絡してキャンセルする必要がある。

図出典/(可霊)
豆包、通義千問、可霊と比べて、訊飛星火の条件はより厳しい。条項によると、ユーザーが個人情報の収集範囲を変更または撤回したい場合は、アカウントを削除することでしか実現できない。

図出典/(訊飛星火)
特筆すべきは、騰訊元宝(テンセントユアンバオ)は条項に情報の同意変更方法を記載していないものの、アプリ内で「音声機能改善計画」のスイッチが確認できることだ。

図出典/(騰訊元宝)
Kimiはプライバシーポリシー上で声紋情報を第三者と共有することを撤回でき、アプリ内で対応する操作が可能だと述べているが、「TechFlow」が長時間探しても変更入口は見つからなかった。また、他の文字情報に関しても、該当する条項は見当たらなかった。

図出典/(Kimi プライバシーポリシー)
実際、いくつかの主要な大規模モデルアプリを見ればわかるように、各社はユーザーの声紋管理を重視しており、豆包や通義千問などでは自主的な操作で同意を取り消せる。また、位置情報、カメラ、マイクなど特定のインタラクション場面での基本的な権限も自主的にオフにできるが、AI訓練への「投入」データの撤回に関しては、どの企業もスムーズではない。
ちなみに、海外の大規模モデルも「ユーザーのデータをAI訓練から除外する仕組み」において似たような対応をしている。GoogleのGeminiの関連条項では、「今後の会話の審査や、会話をもとにGoogleの機械学習技術を改善することを希望しない場合は、Geminiアプリのアクティビティ記録をオフにしてください」と規定している。
さらにGeminiは、自分のアクティビティ記録を削除しても、すでに人間の審査員によって審査または注釈された会話内容(および言語、デバイスタイプ、位置情報、フィードバックなどの関連データ)は削除されないと述べており、これらは別途保存されており、Googleアカウントと関連付けられていないため、最大3年間保持されるという。
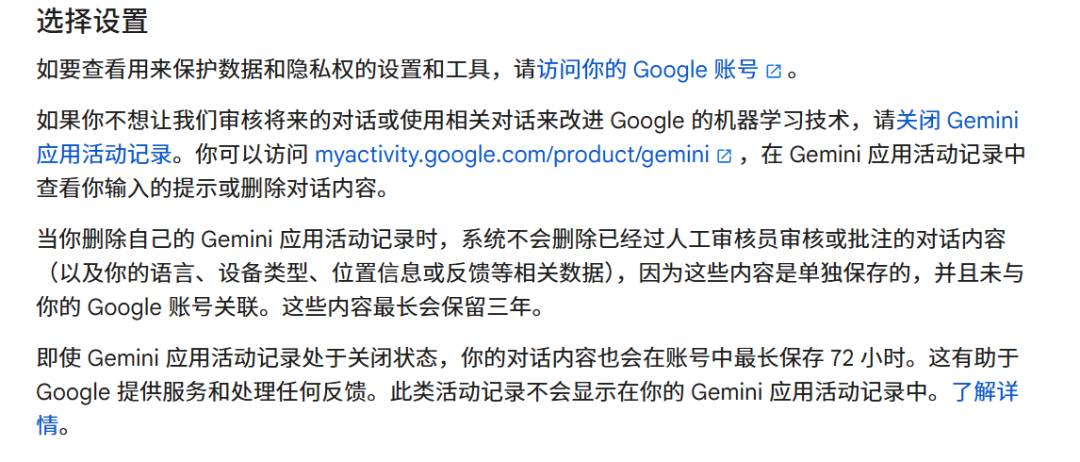
図出典/(Gemini 条項)
ChatGPTのルールはやや曖昧で、「ユーザーが個人データの処理を制限する権利を持つ可能性がある」としているが、実際の利用では、Plusユーザーのみがデータを訓練に使用しないよう手動で設定できるのに対し、無料ユーザーの場合、通常はデータが自動的に収集され訓練に使用される。退出を希望する場合は、公式にメールを送る必要がある。

図出典/(ChatGPT 条項)
実際、これらの大型モデル製品の条項から読み取れるのは、ユーザーの入力情報を収集することが一種の共通認識となっていることだ。しかし、よりプライバシー性の高い声紋、顔認証などのバイオ情報については、一部のマルチモーダルプラットフォームが若干言及している程度である。
これは経験不足というわけではない。特にインターネット大手企業にとってはなおさらだ。例えば、WeChatのプライバシーポリシーでは、データ収集の具体的なシーン、目的、範囲を詳細に列挙しており、明確に「チャット履歴は収集しません」と約束している。抖音(ドウイン)も同様で、ユーザーがアップロードした情報のほとんどについて、プライバシーポリシー内で使用方法、使用目的などを詳細に明示している。

図出典/(抖音 プライバシーポリシー)
インターネットソーシャル時代に厳しく管理されていたデータ取得行為が、AI時代ではむしろ常態化している。ユーザーが入力する情報は、大規模モデルメーカーによって「学習コーパス」という名目で自由に取得されており、ユーザーのデータはもはや厳重に扱うべき個人情報ではなく、モデル進化の「足掛かり」となってしまっているのだ。
ユーザーのデータ以外にも、大規模モデルにとって重要なのは学習コーパスの透明性である。これらのコーパスが合法的かつ正当なものであるか、知的財産権侵害を構成していないか、ユーザーの利用に潜在的なリスクがないかといった問題も重要である。こうした疑問を持ちながら、私たちは7つの大規模モデル製品に対して深く掘り下げ、評価を行った。その結果は私たちを驚かせた。
02. 学習コーパス「投入」の潜在的危険
大規模モデルの学習には計算能力だけでなく、高品質なコーパスが極めて重要である。しかし、こうしたコーパスにはしばしば著作権で保護されたテキスト、画像、動画などの多様な作品が含まれており、許可なく使用すれば明らかに著作権侵害となる。
「TechFlow」の実測によると、7つの大規模モデル製品はいずれも契約において大規模モデルの学習データの具体的な出所に言及しておらず、著作権付きデータの公開も行っていない。

なぜ皆が訓練コーパスを公開しないのかという理由は簡単だ。一方では、データの不適切な使用が容易に著作権紛争を引き起こす可能性があり、AI企業が著作権付き製品を訓練コーパスとして使用することが合規かつ合法であるかについて、現時点ではまだ明確な規定がない。もう一方では、企業間の競争とも関係しており、企業が訓練コーパスを公開すれば、食品メーカーが原材料を業界の同僚に教えるようなもので、他社がすぐに模倣し、製品レベルを向上させられるからである。
特筆すべきは、ほとんどのモデルのポリシーでは、ユーザーと大規模モデルのやり取りによって得られた情報を、モデルおよびサービスの最適化、関連研究、ブランドプロモーションおよび広報、マーケティング、ユーザー調査などに使用すると述べている点である。
率直に言って、ユーザーのデータは質がまちまちで、シーンの深さも不十分であり、限界効果も存在するため、モデルの能力向上にはほとんど貢献せず、余分なデータクリーニングコストを生む可能性さえある。それでも、ユーザーのデータの価値は依然として存在する。ただ、それはもはやモデル能力の向上の鍵ではなく、企業が商業的利益を得る新たな手段となっている。ユーザーとの会話を分析することで、企業はユーザー行動を洞察し、収益化の場面を発掘し、商業機能をカスタマイズし、広告主と情報を共有することさえ可能になる。そしてこれらはすべて、大規模モデル製品の使用ルールに合致している。
ただし、リアルタイム処理中に発生するデータはクラウドにアップロードされ処理され、クラウド上に保存されることにも注意が必要だ。大多数の大規模モデルはプライバシーポリシーで、業界標準以上の中立的な暗号化技術、匿名化処理、およびその他の可能な手段を用いて個人情報を保護すると述べているが、これらの対策の実際の効果については依然として懸念がある。
例えば、ユーザーの入力内容をデータセットとして使用した場合、時間が経ってから他のユーザーが類似の質問を大規模モデルに行えば、情報漏洩のリスクが生じる可能性がある。また、クラウドや製品が攻撃を受けた場合、関連付けや分析技術によって元の情報を復元できる可能性もあり、これが潜在的な危険である。
欧州データ保護委員会(EDPB)は最近、人工知能モデルによる個人データ処理に関するデータ保護ガイドラインを発表した。このガイドラインは明確に、AIモデルの匿名性は単なる宣言では確立されず、厳密な技術的検証と継続的な監視措置によって保証されなければならないと指摘している。また、企業はデータ処理活動の必要性を証明するだけでなく、処理過程で個人のプライバシーへの干渉が最小限となる方法を採用していることを示さなければならないと強調している。

したがって、大規模モデル企業が「モデル性能の向上」を理由にデータを収集するとき、我々はもっと警戒すべきである。これは本当にモデル進化のための必須条件なのか、それとも企業が商業目的でユーザーのデータを乱用しているだけなのか。
03. データセキュリティのあいまいな領域
従来の大規模モデルアプリに加えて、エージェント型AI、端末側AIの活用によるプライバシー漏洩リスクはさらに複雑である。
チャットボットなどのAIツールと比較して、エージェント型AIや端末側AIは使用時に、より詳細かつ価値の高い個人情報を取得する必要がある。従来のスマートフォンが取得する情報は主にユーザーのデバイスおよびアプリ情報、ログ情報、基本的な権限情報などであったが、端末側AIのシナリオおよび現在主流の画面読み取り・録画技術方式では、前述の包括的な情報権限に加え、エージェントは録画ファイルそのものを取得し、モデル分析を通じて身元、位置、支払いなどのさまざまなセンシティブ情報をさらに抽出できる。
例えば、HONOR(栄耀)が以前の発表会でデモンストレーションした出前注文のシナリオでは、位置情報、支払い情報、嗜好などがAIアプリによって静かに読み取られ記録され、個人のプライバシー漏洩リスクが高まる。

「騰訊研究院」が以前分析したように、モバイルインターネットエコシステムでは、直接消費者にサービスを提供するAPPは一般にデータ管理者と見なされ、EC、SNS、交通などのサービスシナリオにおいて、相応のプライバシー保護およびデータセキュリティ責任を負っている。しかし、端末側AIエージェントがAPPのサービス機能に基づいて特定のタスクを完了する際、端末メーカーとAPPサービス提供者の間のデータセキュリティ上の責任境界は曖昧になる。
多くの場合、メーカーは「より良いサービスを提供する」という言い訳を使うが、業界全体で見れば、これはもはや「正当な理由」とは言えない。Apple Intelligenceは明確に、クラウド上にユーザーのデータを保存せず、Apple自身を含むいかなる組織もユーザーのデータを取得できないようにするために複数の技術的手段を採用していると表明しており、ユーザーの信頼を得ている。
言うまでもなく、現在の主流の大規模モデルは透明性の面で解決すべき多くの問題を抱えている。ユーザーのデータ撤回が困難であること、学習コーパスの出所が不明瞭であること、エージェント型AIや端末側AIがもたらす複雑なプライバシーリスクなど、これらすべてが大規模モデルに対するユーザーの信頼の基盤を着実に蝕んでいる。

大規模モデルはデジタル化プロセスを推進する鍵となる存在であり、その透明性の向上は喫緊の課題である。これはユーザーの個人情報セキュリティおよびプライバシー保護にとどまらず、大規模モデル業界全体が健全かつ持続可能な発展を遂げられるかどうかの核心的要素でもある。
今後、各大規模モデルメーカーには積極的に対応し、製品設計およびプライバシーポリシーを自主的に最適化し、よりオープンで透明性の高い姿勢でユーザーにデータの流れを明確に説明し、ユーザーが安心して大規模モデル技術を利用できる環境を整えてほしい。同時に、規制当局も関連する法律・規制の整備を急ぎ、データ利用のルールおよび責任の境界を明確にし、大規模モデル業界に革新の活力と安全・秩序ある発展環境を両立させる場を提供し、大規模モデルが真に人類に利益をもたらす強力なツールとなるよう促すべきである。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














