

Test réel de 7 grands modèles d'IA dominants : l'exposition des données personnelles devient un problème courant
TechFlow SélectionTechFlow Sélection
Test réel de 7 grands modèles d'IA dominants : l'exposition des données personnelles devient un problème courant
Nous espérons que les principaux fabricants de modèles prendront l'initiative d'améliorer activement la conception de leurs produits et leurs politiques de confidentialité, en adoptant une attitude plus ouverte et transparente afin d'expliquer clairement aux utilisateurs l'origine et l'utilisation des données, leur permettant ainsi d'utiliser la technologie des grands modèles en toute sérénité.
Auteur : Siyuan, TechFlow

Crédit image : Généré par Wujie AI
À l'ère de l'IA, les informations saisies par les utilisateurs ne relèvent plus uniquement de la vie privée individuelle, mais deviennent une « pierre angulaire » du progrès des grands modèles.
« Aide-moi à créer une présentation PowerPoint », « Aide-moi à concevoir une affiche pour le Nouvel An chinois », « Résume-moi le contenu de ce document ». Depuis que les grands modèles ont fait fureur, utiliser des outils d'IA pour gagner en efficacité est devenu une pratique courante dans le travail des employés de bureau. Certains vont même jusqu'à commander des repas ou réserver des hôtels via l'IA.
Cependant, cette collecte et utilisation des données soulève de graves risques en matière de confidentialité. De nombreux utilisateurs ignorent un problème majeur à l’ère numérique : le manque de transparence. Ils ne savent pas comment leurs données sont collectées, traitées et stockées par ces outils d’IA, ni s’il y a un risque d’usage abusif ou de fuite.
En mars dernier, OpenAI a reconnu qu'une faille dans ChatGPT avait entraîné la divulgation partielle de certains historiques de conversations. Cet incident a suscité une inquiétude publique croissante quant à la sécurité des données et à la protection de la vie privée liées aux grands modèles. Outre cet événement, les modèles d’IA de Meta ont également été critiqués pour violation de droits d’auteur. En avril dernier, des écrivains, artistes et organisations américaines ont accusé Meta d’avoir utilisé illégalement leurs œuvres pour entraîner ses modèles d’IA, portant atteinte à leurs droits.
Des cas similaires se sont produits en Chine. Récemment, iQiyi a attiré l’attention en poursuivant MiniMax (l’un des « six petits tigres des grands modèles ») pour violation de droits d’auteur. iQiyi accuse l’outil HeLuo AI d’avoir utilisé sans autorisation ses contenus protégés pour entraîner un modèle, marquant ainsi la première affaire judiciaire en Chine opposant une plateforme vidéo à un grand modèle IA générant des vidéos.
Ces incidents ont attiré l’attention sur l’origine des données d’entraînement des grands modèles et les questions relatives aux droits d’auteur, montrant clairement que le développement de l’IA doit reposer sur une base solide de protection de la vie privée des utilisateurs.
Pour évaluer le niveau de transparence actuel des grands modèles nationaux chinois en matière de divulgation d’informations, TechFlow a sélectionné sept grands modèles populaires du marché : DouBao, Wenxin Yiyan, Kimi, HunYuan de Tencent, Spark Model, Tongyi Qianwen et Kuaishou KeLing. Nous avons mené une étude approfondie via l’analyse de leurs politiques de confidentialité, conditions d’utilisation et tests pratiques. Les résultats montrent que de nombreuses entreprises font encore peu d’efforts dans ce domaine, révélant clairement la relation délicate entre les données utilisateur et les produits d’IA.
01. Un droit de retrait quasi inexistant
Tout d’abord, TechFlow observe clairement que les sept grands modèles chinois adoptent tous la norme habituelle des applications Internet : présenter des conditions d’utilisation et une politique de confidentialité. Tous mentionnent dans leur politique des sections spécifiques expliquant comment les données personnelles sont collectées et utilisées.
Leurs formulations sont très similaires : « Pour optimiser et améliorer l’expérience utilisateur, nous pouvons analyser les retours des utilisateurs sur les contenus générés, ainsi que les problèmes rencontrés lors de l’utilisation. Sous réserve de techniques de chiffrement sécurisées et d’anonymisation rigoureuse, les données saisies par l’utilisateur, les commandes envoyées, les réponses générées par l’IA, ainsi que les données d’accès et d’utilisation du produit peuvent être analysées et utilisées pour l’entraînement du modèle. »
En théorie, utiliser les données des utilisateurs pour améliorer progressivement le produit semble former un cercle vertueux. Mais la question centrale pour les utilisateurs est de savoir s'ils peuvent refuser ou retirer leur consentement concernant l'utilisation de leurs données pour l'entraînement du modèle.
Après examen attentif et tests pratiques de ces sept produits IA, TechFlow constate que seuls DouBao, iFlytek, Tongyi Qianwen et KeLing mentionnent explicitement la possibilité de « modifier l’étendue de la collecte des données personnelles ou de retirer son consentement ».
Dans le cas de DouBao, cette option concerne principalement les données vocales. La politique indique : « Si vous ne souhaitez pas que vos informations vocales soient utilisées pour l’entraînement et l’optimisation du modèle, vous pouvez désactiver l’option “Améliorer le service vocal” dans Paramètres > Paramètres du compte. » Pour les autres types de données, il faut contacter l’équipe officielle via les coordonnées publiées afin de demander le retrait de l’autorisation d’utiliser les données à des fins d’entraînement.

Source image : (DouBao)
En pratique, désactiver l'autorisation relative au service vocal n'est pas difficile. Cependant, concernant le retrait pour d'autres types de données, après avoir contacté l'équipe officielle de DouBao, TechFlow n'a jamais obtenu de réponse.
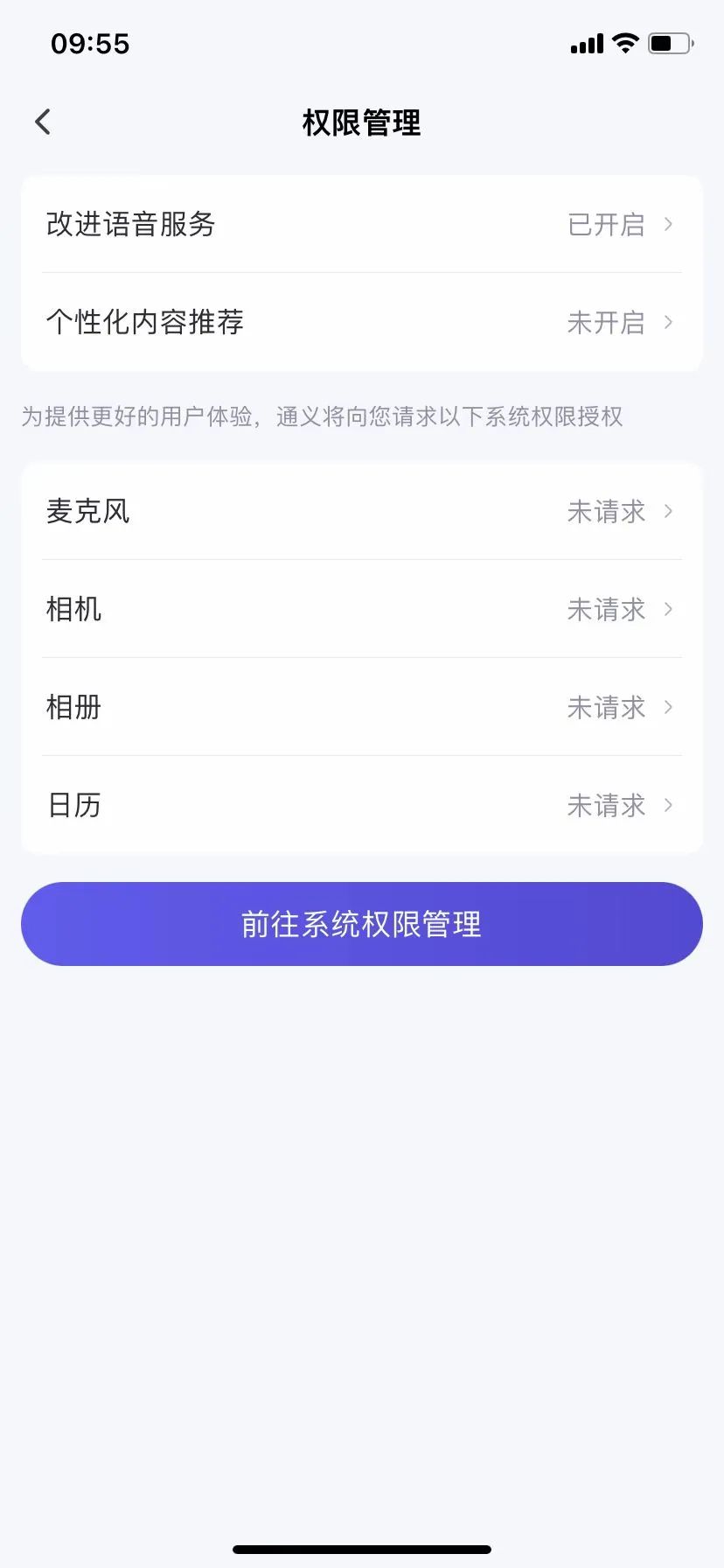
Source image : (DouBao)
Tongyi Qianwen fonctionne de manière similaire à DouBao : l'utilisateur peut uniquement désactiver l'utilisation de ses données vocales. Pour tout autre type de données, il faut aussi contacter l’équipe officielle via les coordonnées fournies afin de modifier ou retirer son consentement.

Source image : (Tongyi Qianwen)
KeLing, en tant que plateforme de génération d'images et vidéos, accorde une attention particulière à l'utilisation du visage. Elle affirme ne pas utiliser les pixels de votre visage à d'autres fins ni les partager avec des tiers. Toutefois, pour annuler cette autorisation, il faut envoyer un e-mail à l’équipe officielle.

Source image : (KeLing)
Comparé à DouBao, Tongyi Qianwen et KeLing, iFlytek Spark impose des exigences plus strictes : selon ses conditions, l'utilisateur doit supprimer complètement son compte pour modifier ou retirer son consentement à la collecte de données personnelles.

Source image : (iFlytek Spark)
Fait notable, bien que Tencent Yuanbao ne précise pas dans ses conditions comment modifier les autorisations, l’application propose néanmoins un interrupteur intitulé « Programme d’amélioration des fonctions vocales ».

Source image : (Tencent Yuanbao)
Kimi mentionne dans sa politique de confidentialité la possibilité de retirer le partage de ses données biométriques vocales, et permet une action directe dans l’application. Néanmoins, après de longues recherches, TechFlow n’a trouvé aucune entrée pour effectuer ce changement. Quant aux autres données textuelles, aucune disposition correspondante n’a été identifiée.

Source image : (Clause de confidentialité de Kimi)
Il est facile de constater que, parmi les principaux grands modèles, une attention particulière est accordée à la gestion des données vocales. Des applications comme DouBao et Tongyi Qianwen permettent une désactivation autonome. Concernant les autorisations fondamentales telles que la géolocalisation, la caméra ou le microphone, les utilisateurs peuvent également les désactiver eux-mêmes. En revanche, le retrait des données « alimentant » l’entraînement du modèle reste extrêmement mal aisé.
Notons que les grands modèles étrangers adoptent des pratiques similaires en matière de « mécanisme de sortie des données utilisateur ». Par exemple, Google Gemini stipule : « Si vous ne souhaitez pas que nous examinions vos futures conversations ou que celles-ci soient utilisées pour améliorer les technologies d’apprentissage automatique de Google, veuillez désactiver l’enregistrement des activités dans l’application Gemini. »
En outre, Gemini précise que lorsque vous supprimez vos enregistrements d’activité, les conversations déjà examinées ou annotées par des humains (ainsi que les données associées telles que la langue, le type d’appareil, la localisation ou les retours) ne seront pas effacées, car elles sont conservées séparément et non liées à votre compte Google. Ces données peuvent être conservées jusqu’à trois ans.
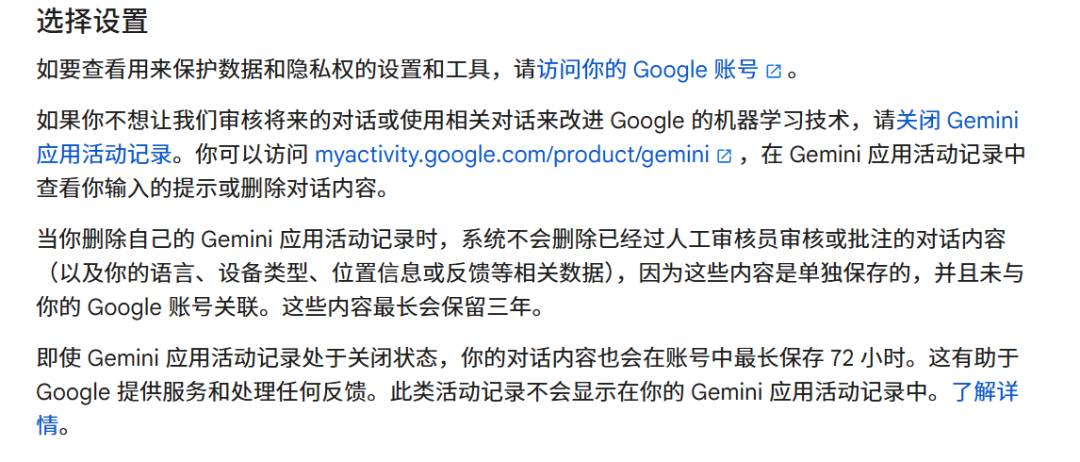
Source image : (Conditions de Gemini)
Les règles de ChatGPT sont plus ambiguës : elles indiquent que les utilisateurs « peuvent avoir le droit de limiter le traitement de leurs données personnelles ». En pratique, on constate que les utilisateurs payants (Plus) peuvent désactiver manuellement l’utilisation de leurs données pour l’entraînement, tandis que pour les utilisateurs gratuits, la collecte est activée par défaut. Pour refuser, les utilisateurs doivent envoyer un message à l’équipe officielle.

Source image : (Conditions de ChatGPT)
Ces exemples montrent clairement que la collecte des données saisies par les utilisateurs est devenue une pratique généralisée. Toutefois, concernant des données plus sensibles comme les empreintes vocales ou faciales, seules certaines plateformes multimodales apportent des mentions spécifiques.
Mais cela ne relève pas d’une simple lacune technique, surtout chez les grands groupes technologiques. Par exemple, la politique de confidentialité de WeChat détaille précisément chaque scénario de collecte de données, leurs objectifs et leur portée, allant jusqu’à promettre expressément « de ne pas collecter les messages privés des utilisateurs ». TikTok suit une démarche similaire : presque toutes les informations téléchargées par les utilisateurs font l’objet d’une description détaillée dans la politique de confidentialité, précisant leur mode d’utilisation et leur finalité.

Source image : (Politique de confidentialité de TikTok)
Les comportements strictement encadrés d’acquisition de données à l’ère du Web social sont désormais devenus une norme à l’ère de l’IA. Les informations saisies par les utilisateurs sont librement récupérées par les fabricants de grands modèles sous le prétexte de « corpus d’entraînement ». Les données personnelles ne sont plus considérées comme une information sensible nécessitant une protection stricte, mais plutôt comme une « marchepied » vers le progrès du modèle.
Au-delà des données utilisateur, la transparence des corpus d’entraînement est cruciale pour les grands modèles. Le caractère légal et licite de ces corpus, le risque d’infraction aux droits d’auteur, ou encore les dangers potentiels pour les utilisateurs, sont autant de questions essentielles. Armés de ces interrogations, nous avons mené une enquête approfondie sur les sept produits, dont les résultats nous ont profondément surpris.
02. Risques liés au « nourrissage » des données d’entraînement
Outre la puissance de calcul, la qualité des corpus d’entraînement est primordiale pour les grands modèles. Or, ces corpus contiennent souvent des œuvres variées — textes, images, vidéos — protégées par le droit d’auteur. Leur utilisation non autorisée constitue manifestement une infraction.
Notre investigation révèle que les sept grands modèles testés ne mentionnent aucunement dans leurs contrats la source exacte de leurs données d’entraînement, encore moins la liste des données soumises à copyright.

La raison de ce mutisme concerté est simple. D’une part, une mauvaise gestion des données pourrait rapidement entraîner des litiges sur les droits d’auteur. À ce jour, aucune réglementation claire ne définit si l’utilisation d’œuvres sous copyright pour entraîner un modèle d’IA est légale. D’autre part, cela touche à la compétitivité entre entreprises : rendre public le corpus d’entraînement reviendrait, pour une entreprise alimentaire, à divulguer ses ingrédients à ses concurrents, qui pourraient alors reproduire rapidement le produit et améliorer leur propre offre.
Fait notable, la plupart des politiques mentionnent que les informations issues des interactions entre l’utilisateur et le modèle peuvent être utilisées pour optimiser le modèle et le service, réaliser des recherches, promouvoir la marque, faire du marketing ou mener des études utilisateurs.
Franchement, en raison de la qualité inégale des données utilisateur, de leur faible profondeur contextuelle et de leur rendement marginal, elles contribuent peu à améliorer réellement les capacités du modèle, voire augmentent les coûts de nettoyage des données. Malgré cela, ces données conservent une valeur. Elles ne sont plus essentielles à l'amélioration du modèle, mais deviennent une nouvelle voie vers des bénéfices commerciaux. En analysant les conversations, les entreprises peuvent comprendre le comportement des utilisateurs, identifier des opportunités monétaires, personnaliser des fonctionnalités commerciales, voire partager des informations avec des annonceurs. Et tout cela respecte parfaitement les règles d’utilisation des produits d’IA.
Néanmoins, il convient de noter que les données générées pendant le traitement en temps réel sont transférées puis stockées dans le cloud. Bien que la majorité des grands modèles affirment protéger les données personnelles par des techniques de chiffrement comparables aux standards du secteur, des traitements d’anonymisation et d’autres mesures réalisables, l’efficacité réelle de ces protections reste sujette à caution.
Par exemple, si les saisies des utilisateurs sont intégrées à un jeu de données, il existe un risque futur de fuite d’information : quelqu’un interrogeant ultérieurement le modèle sur un sujet similaire pourrait indirectement accéder à ces données. En outre, en cas d’attaque informatique contre le cloud ou le produit lui-même, il pourrait rester possible, grâce à des techniques d’analyse ou de corrélation, de reconstituer les informations originales — un risque majeur.
Récemment, le Comité européen de la protection des données (CEPD) a publié des orientations sur le traitement des données personnelles par les modèles d’IA. Il y précise clairement que l’anonymisation d’un modèle d’IA ne peut pas être affirmée par simple déclaration : elle doit être validée techniquement de manière rigoureuse et surveillée continuellement. En outre, les entreprises doivent non seulement prouver la nécessité de leurs traitements, mais aussi démontrer qu’elles ont recours aux méthodes les moins intrusives possibles pour la vie privée des individus.

Ainsi, lorsque les entreprises invoquent « l’amélioration des performances du modèle » pour justifier la collecte de données, nous devons rester vigilants : s’agit-il d’une condition nécessaire au progrès du modèle, ou d’un abus commercial basé sur les données des utilisateurs ?
03. Zones grises en matière de sécurité des données
Au-delà des applications classiques de grands modèles, les agents intelligents et l’IA côté terminal introduisent des risques de fuite de données encore plus complexes.
Contrairement aux chatbots ou outils IA classiques, les agents intelligents et l’IA côté terminal nécessitent des données personnelles plus détaillées et plus sensibles. Traditionnellement, les applications mobiles collectent principalement des informations sur l’appareil, les journaux d’utilisation et les permissions système. Dans les scénarios d’IA côté terminal — notamment ceux reposant sur des technologies de lecture ou d’enregistrement d’écran —, outre ces données classiques, les agents peuvent accéder directement aux fichiers d’enregistrement d’écran, puis analyser ces données via le modèle pour extraire des informations sensibles telles que l’identité, la localisation ou les paiements.
Par exemple, lors de la présentation de Honor, un scénario de commande de repas a été démontré. Dans ce cas, des données telles que la localisation, les préférences et les informations de paiement sont silencieusement lues et enregistrées par l’application IA, augmentant ainsi fortement le risque de fuite de données personnelles.

Comme l’a analysé précédemment le « Tencent Research Institute », dans l’écosystème mobile, les applications grand public sont généralement considérées comme responsables du traitement des données, assumant la responsabilité de la protection de la vie privée et de la sécurité des données dans des services tels que le commerce électronique, les réseaux sociaux ou les transports. Cependant, lorsque des agents intelligents côté terminal s’appuient sur les fonctionnalités d’une application pour accomplir une tâche, la frontière de responsabilité entre le fabricant du terminal et le fournisseur du service devient floue.
Les fabricants invoquent souvent l’amélioration de l’expérience utilisateur comme justification. Mais à l’échelle de l’industrie, ce n’est pas une « raison légitime ». Apple Intelligence, par exemple, affirme clairement que les données utilisateur ne sont pas stockées dans le cloud, et utilise diverses techniques pour empêcher toute récupération, y compris par Apple elle-même, renforçant ainsi la confiance des utilisateurs.
Il est indéniable que les grands modèles actuels souffrent de graves lacunes en matière de transparence. Que ce soit la difficulté à retirer ses données, l’opacité des sources d’entraînement ou les risques complexes liés aux agents intelligents et à l’IA côté terminal, tous ces facteurs sapent progressivement la confiance des utilisateurs dans les grands modèles.

En tant que moteur clé de la transformation numérique, l’amélioration de la transparence des grands modèles est urgente. Cela ne concerne pas seulement la sécurité des données personnelles et la protection de la vie privée, mais aussi la santé et la durabilité du secteur dans son ensemble.
À l’avenir, nous espérons que les principaux fabricants de grands modèles répondront activement à ce défi, en optimisant volontairement la conception de leurs produits et leurs politiques de confidentialité. Adoptant une attitude plus ouverte et transparente, ils devraient expliquer clairement aux utilisateurs l’origine et l’utilisation de leurs données, afin que chacun puisse utiliser ces technologies en toute confiance. Parallèlement, les autorités de régulation doivent accélérer l’élaboration de lois et règlements, clarifier les normes d’utilisation des données et les limites de responsabilité, afin de créer un environnement de développement innovant, sûr et ordonné pour l’industrie des grands modèles, faisant ainsi de l’IA un véritable outil au service de l’humanité.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














