

Vitalik Buterin's Latest Article: X's Community Notes Embody Crypto Spirit, Looking Forward to the Future of New Social Media Experiments
TechFlow Selected TechFlow Selected
Vitalik Buterin's Latest Article: X's Community Notes Embody Crypto Spirit, Looking Forward to the Future of New Social Media Experiments
Although Community Notes is not a "crypto project," it may be the closest example of "crypto values" that we've seen in the mainstream world.
Written by: vitalik
Compiled by: TechFlow
Over the past two years, Twitter (X) has been nothing short of turbulent. Last year, Elon Musk acquired the platform for $44 billion and proceeded to overhaul its staffing, content moderation, business model, and site culture—changes that may stem more from Musk’s soft power than specific policy decisions. Yet amid these controversial actions, one new feature on Twitter has rapidly gained importance and appears to be embraced across political spectrums: Community Notes.
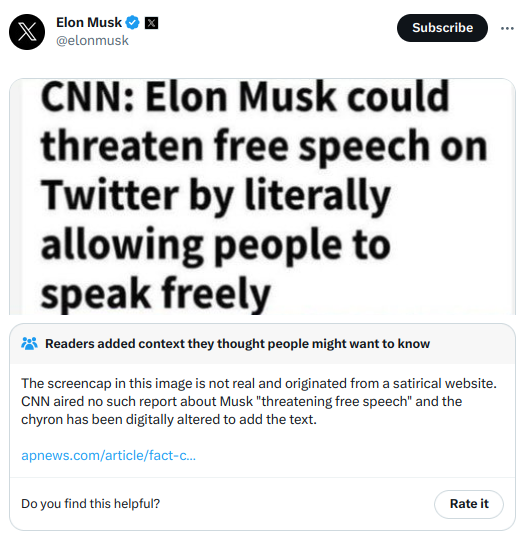
Community Notes is a fact-checking tool that sometimes adds contextual annotations to tweets—for example, as seen on this tweet by Elon Musk—serving as a mechanism for fact verification and countering misinformation. Originally called Birdwatch, it launched in January 2021 as a pilot project. Since then, it has gradually expanded, with the fastest growth coinciding with Elon Musk's takeover of Twitter last year. Today, Community Notes frequently appear on widely viewed tweets on Twitter, including those involving controversial political topics. In my view—and based on conversations I’ve had with people across various political affiliations—these Notes are informative and valuable when they do appear.
However, what fascinates me most about Community Notes is that, although it is not a “crypto project,” it may represent the closest real-world example we have seen of “crypto values.” Community Notes are not written or curated by a centrally selected group of experts; instead, anyone can write and vote on them, and which Notes appear is determined entirely by an open-source algorithm. Twitter provides a detailed, comprehensive guide explaining how the algorithm works, and you can download datasets containing published Notes and votes, run the algorithm locally, and verify whether the output matches what appears on the Twitter website. While imperfect, it surprisingly approaches the ideal of credible neutrality even in highly contentious situations—and remains highly functional at the same time.
How does the Community Notes algorithm work?
Any Twitter account meeting certain criteria (basically: active for over six months, no history of violations, phone number verified) can apply to join Community Notes. Participants are currently being accepted slowly and randomly, but the long-term plan is to allow any qualified user to join. Once accepted, you first participate in rating existing Notes. Once your ratings prove sufficiently accurate (measured by how well they align with final outcomes), you become eligible to write your own Notes.
When you write a Note, it receives a score based on evaluations from other Community Notes members. These evaluations function like votes along three levels: “helpful,” “somewhat helpful,” and “not helpful,” though reviewers can also include additional tags that factor into the algorithm. Based on these evaluations, each Note receives a score. If a Note’s score exceeds 0.40, it gets displayed; otherwise, it remains hidden.
The unique aspect of the algorithm lies in how scores are calculated. Unlike simple algorithms that merely sum or average user ratings, the Community Notes scoring system explicitly prioritizes Notes that receive positive evaluations from users with differing viewpoints. In other words, if users who typically disagree end up agreeing on a particular Note, that Note receives a higher score.
Let’s dive deeper into how it works. We have a set of users and a set of Notes—we can create a matrix M where cell Mij represents how user i rated Note j.
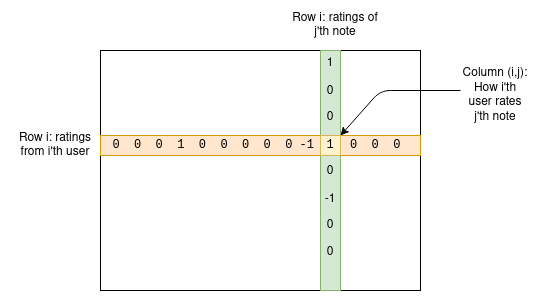
For any given Note, most users haven’t rated it, so most entries in the matrix will be zero—but that’s fine. The goal of the algorithm is to build a four-parameter model for users and Notes, assigning two statistics to each user—let’s call them “friendliness” and “polarity”—and two to each Note—“usefulness” and “polarity.” The model attempts to predict the matrix using these values according to the following formula:
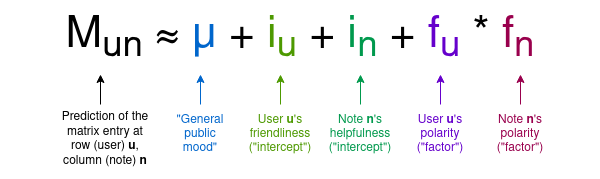
Note that here I introduce both the terminology used in the Birdwatch paper and my own intuitive interpretations of the variables’ meanings without relying on mathematical concepts:
-
μ is a “public sentiment” parameter measuring how high ratings tend to be overall.
-
iu is the user’s “friendliness,” indicating how likely they are to give high ratings.
-
in is the Note’s “usefulness,” reflecting how likely it is to receive high ratings. This is the variable we care about.
-
fu or fn is the “polarity” of a user or Note—its position along the dominant axis of political extremity. In practice, negative polarity roughly means “left-leaning,” positive means “right-leaning,” but crucially, this ideological axis is derived purely from analyzing user and Note data—the left/right dichotomy isn’t hardcoded.
The algorithm uses a fairly standard machine learning approach (gradient descent) to find optimal values that best predict the matrix. The assigned usefulness value becomes the final score for a Note. If a Note’s usefulness is at least +0.4, it gets displayed.
The key insight here is that “polarity” captures characteristics of a Note that cause it to be liked by some users and disliked by others, while “usefulness” only measures traits that lead to broad approval across all users. Thus, selecting for usefulness identifies Notes that gain cross-tribal recognition and filters out those celebrated within one group but reviled by another.
The above describes only the core part of the algorithm. In reality, many additional mechanisms are layered on top. Fortunately, these are documented publicly. They include:
-
The algorithm runs multiple times, each time adding randomly generated extreme “synthetic votes.” This means the actual output for each Note is a range of values, and the final result depends on comparing the “lower bound confidence” drawn from this range against a threshold of 0.32.
-
If many users—especially those with similar polarity to the Note—rate a Note as “not useful” and use the same tag (e.g., “argumentative or biased language,” “source doesn’t support claim”) as their reason, the usefulness threshold required for display increases from 0.4 to 0.5 (a small change that matters significantly in practice).
-
Once a Note is accepted, its usefulness must drop below the acceptance threshold by 0.01 points before it gets removed.
-
Multiple models run additional iterations, sometimes promoting Notes whose initial usefulness scores fall between 0.3 and 0.4.
All together, this results in complex Python code totaling 6,282 lines across 22 files. But it’s all open—you can download the Notes and voting data and run the algorithm yourself to verify whether outputs match what appears on Twitter.
So what does this look like in practice?
One of the biggest differences between this algorithm and simply averaging user votes may lie in the concept I call “polarity.” The algorithm documentation refers to them as fu and fn, using f for factor because the terms multiply; the more general term stems from the eventual goal of making fu and fn multidimensional.
Polarity is assigned to both users and Notes. The link between user IDs and underlying Twitter accounts is intentionally kept private, but Notes themselves are public. In practice, at least for the English dataset, the algorithm-generated polarity correlates strongly with left-right political alignment.
Here are some examples of Notes with polarity around -0.8:
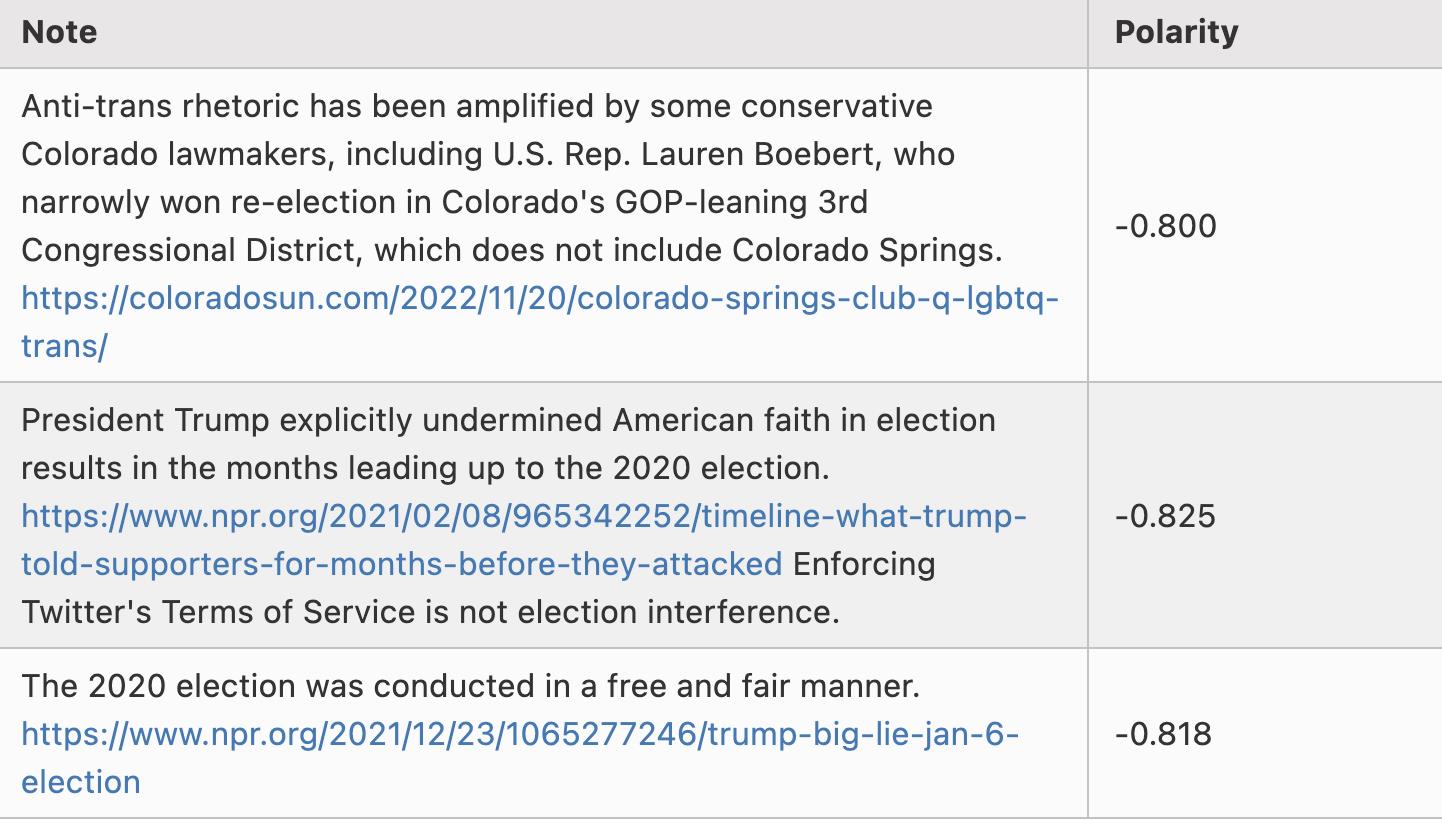
Note: I’m not cherry-picking here—these are literally the first three rows in the scored_notes.tsv spreadsheet generated when I ran the algorithm locally, with polarity scores (called coreNoteFactor1 in the file) below -0.8.
Now, here are some Notes with polarity around +0.8. It turns out many of these are either Portuguese speakers discussing Brazilian politics or Tesla fans angrily rebutting criticism of Tesla, so let me selectively choose a few outside those categories:
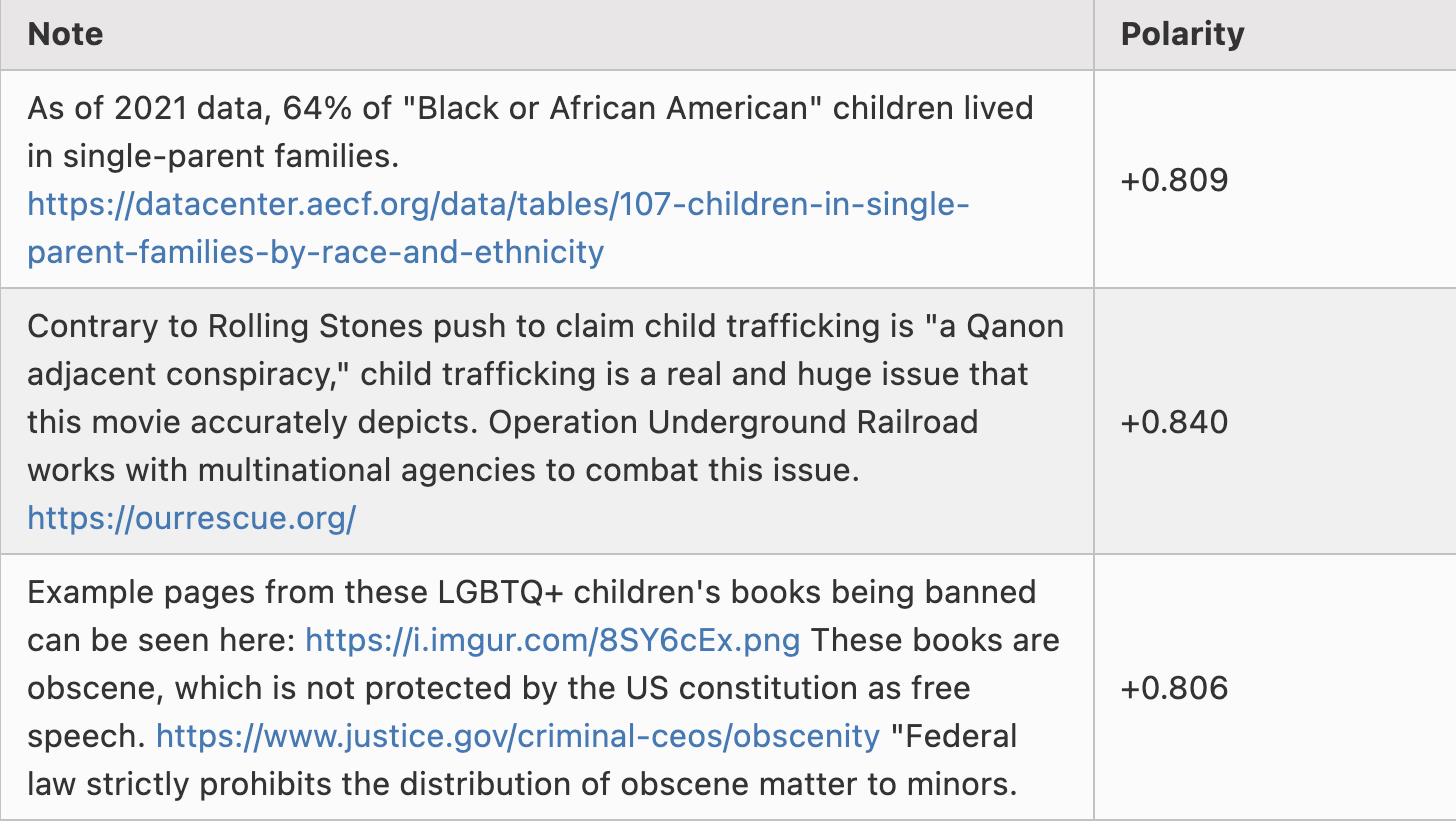
Again, the “left vs right” divide is not hardcoded into the algorithm in any way—it emerges through computation. This suggests that if applied to different cultural contexts, the algorithm could automatically detect major political divides and help bridge them.
Meanwhile, Notes receiving the highest usefulness scores look like this. This time, since these Notes actually appear on Twitter, I can just take screenshots directly:
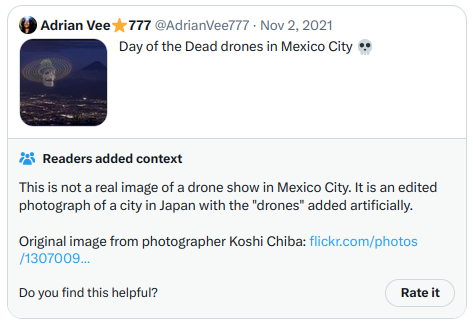
And another:
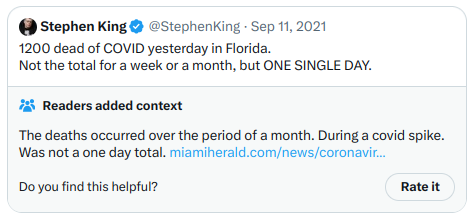
For the second Note, although it deals more directly with a highly partisan political topic, it’s clear, high-quality, and informative—hence earning a high score. Overall, the algorithm appears effective, and verifying its output by running the code seems feasible.
What do I think of the algorithm?
When analyzing this algorithm, what strikes me most is its complexity. There’s an “academic paper version” that uses gradient descent to fit five vectors and a matrix equation, and then there’s the real-world version—a complex series of algorithmic executions with many different runs and numerous arbitrary coefficients along the way.
Even the academic version hides underlying complexity. The equation being optimized is a negative quartic (due to the quadratic fu*fn term in the prediction formula and the cost function measuring squared error). While optimizing quadratic equations across any number of variables almost always yields a unique solution computable via basic linear algebra, optimizing quartic equations across many variables often results in multiple solutions, meaning gradient descent can converge on different local minima. Small input changes might flip the descent from one local minimum to another, drastically altering outputs.
This difference feels to me like the contrast between economists’ algorithms and engineers’ algorithms. Economists’ algorithms prioritize simplicity under ideal conditions, are relatively easy to analyze, and have clear mathematical properties proving optimality (or minimal suboptimality) for their intended task, ideally also bounding potential damage from exploitation. Engineers’ algorithms, by contrast, emerge from iterative trial and error to see what works and fails in real operational environments. They’re pragmatic and get the job done; economists’ algorithms don’t catastrophically fail under unexpected conditions.
Or, as respected internet philosopher roon (aka tszzl) put it on a related topic:

Of course, I’d argue the “theoretical elegance” aspect of crypto is essential because it allows us to clearly distinguish truly trustless protocols from those that merely seem good and superficially work well but actually rely on trusting centralized actors—or worse, might be outright scams.
Deep learning works well under normal conditions, but it has unavoidable vulnerabilities to adversarial machine learning attacks. When possible, technical safeguards and highly abstract frameworks can defend against such attacks. Hence, I wonder: can we transform Community Notes itself into something more like an economist’s algorithm?
To understand what that might mean practically, let’s examine an algorithm I designed years ago for a similar purpose: Pairwise-bounded quadratic funding (a new design for quadratic funding).
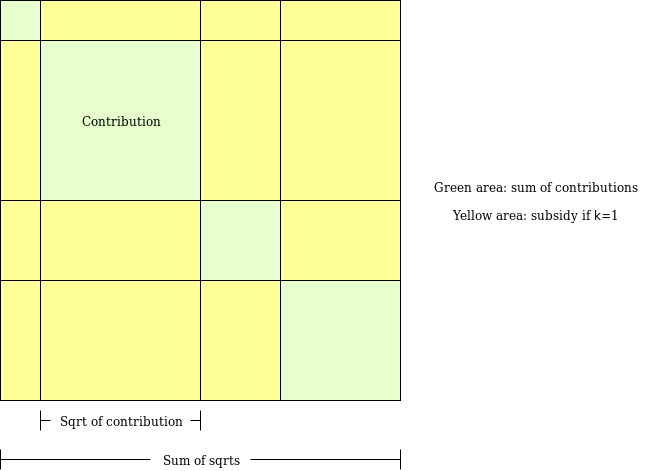
Pairwise-bounded quadratic funding aims to fix a vulnerability in “regular” quadratic funding: even two colluding participants can contribute large amounts to a fake project, recycle funds back to themselves, and extract massive subsidies draining the entire pool. In pairwise-bounded quadratic funding, we assign each pair of participants a limited budget M. The algorithm iterates over all possible pairs; if it decides to subsidize project P because both participant A and B support it, the subsidy is deducted from the (A,B) pair’s shared budget. Thus, even if k participants collude, the maximum amount they can extract is k*(k−1)*M.
This kind of algorithm doesn’t directly apply to Community Notes because each user casts very few votes: on average, the overlap between any two users’ votes is zero, so analyzing user pairs individually cannot reveal polarity. The machine learning model’s purpose is precisely to “fill in” the matrix from extremely sparse source data that can’t be analyzed directly in this way. But this approach requires extra effort to avoid highly unstable results in the face of a small number of bad votes.
Does Community Notes really resist left-right polarization?
We can analyze whether the Community Notes algorithm genuinely resists extremism—whether it performs better than a naive voting algorithm. Such a voting algorithm already offers some resistance to extremism: a post with 200 likes and 100 dislikes performs worse than one with 200 likes alone. But does Community Notes do better?
From an abstract perspective, it’s hard to say. Why couldn’t a highly rated but polarizing post achieve strong polarity and high usefulness? The idea is that conflicting votes should cause polarity to “absorb” the traits driving high ratings, but does it actually work?
To test this, I ran my simplified implementation for 100 rounds. Average results were as follows:

In this test, “good” Notes received +2 from users in the same political group and +0 from opposing groups, while “good but more polarizing” Notes got +4 from same-group users and −2 from opposite-group users. Despite identical average scores, their polarities differed. And indeed, the average usefulness of “good” Notes appeared higher than that of “good but more polarizing” ones.
An algorithm closer to an “economist’s algorithm” would offer a clearer explanation of how it penalizes polarization.
How useful is all this in high-stakes situations?
We can explore this through a concrete case. About a month ago, Ian Bremmer complained that a highly critical Community Note attached to a tweet by a Chinese government official had been removed.
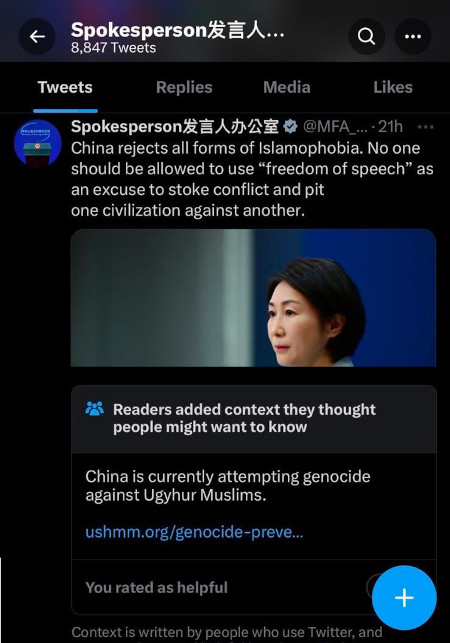
This is challenging. Designing mechanisms within an Ethereum community context—one where the worst outcome might be $20,000 going to an extreme Twitter influencer—is one thing. Dealing with geopolitical and political issues affecting millions, where everyone reasonably assumes the worst motives, is entirely different. But if mechanism designers want to make a real impact, engaging with these high-risk environments is essential.
In Twitter’s case, there’s an obvious reason to suspect centralized manipulation caused the Note’s removal: Elon Musk has significant business interests in China, raising the possibility he pressured the Community Notes team to interfere with the algorithm and remove this specific Note.
Fortunately, the algorithm is open-source and verifiable, so we can actually investigate! Let’s do that. The original tweet URL is https://twitter.com/MFA_China/status/1676157337109946369. The final number, 1676157337109946369, is the tweet ID. We can search downloadable data for this ID and locate the row corresponding to the Note:
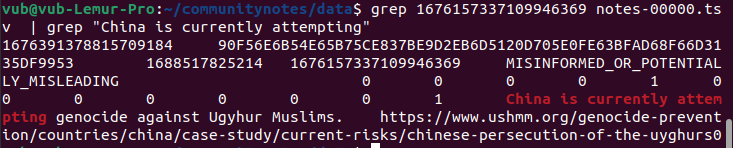
Here, we obtain the Note’s own ID: 1676391378815709184. Then we search the scored_notes.tsv and note_status_history.tsv files generated by running the algorithm for this ID. We get the following results:
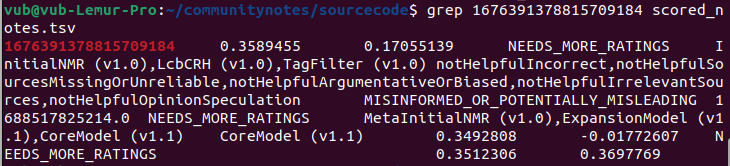

The second column in the first output shows the current score of the Note. The second output displays its history: its current status is in the seventh column (NEEDS_MORE_RATINGS), and its previous non-NEEDS_MORE_RATINGS state was in the fifth column (CURRENTLY_RATED_HELPFUL). So we can see the algorithm itself initially displayed the Note, then removed it after its score slightly dropped—appearing to involve no centralized intervention.
We can also examine the votes directly. By scanning the ratings-00000.tsv file, we can isolate all ratings for this Note and count how many were HELPFUL and NOT_HELPFUL:

But if we sort them by timestamp and look at the first 50 votes, we find 40 HELPFUL and 9 NOT_HELPFUL. So we reach the same conclusion: the initial audience rated the Note more positively, while later voters were less favorable, causing its score to decline over time.
Unfortunately, the exact logic behind state changes is difficult to interpret: it’s not simply “score was above 0.40, now below, so removed.” Instead, numerous NOT_HELPFUL responses triggered one of several exception conditions, increasing the usefulness threshold needed to remain visible.
This presents another important lesson: for a credibly neutral algorithm to be truly credible, it must remain simple. If a Note transitions from accepted to rejected, there should be a clear, straightforward explanation for why.
Of course, another entirely different way to manipulate the vote exists: brigading. People who dislike a Note can mobilize a highly engaged community—or worse, a botnet—to flood it with NOT_HELPFUL votes, potentially flipping it from “useful” to “rejected” with relatively few votes. Properly reducing the algorithm’s vulnerability to such coordinated attacks requires further analysis and work. One possible improvement: don’t let users freely vote on any Note. Instead, use a “for you” algorithm to randomly assign Notes to raters and only allow ratings on assigned Notes.
Is Community Notes not “bold” enough?
The main criticism I’ve seen of Community Notes is essentially that it doesn’t do enough. Two recent articles raised this point. Quoting one:
The program suffers from a serious limitation: for Community Notes to go public, there must be broad consensus across political lines.
“It needs ideological consensus,” he said. “That means left-wing and right-wing people must agree that the annotation should be attached to the tweet.”
He said that essentially, it requires “cross-ideological agreement on truth—which is nearly impossible in an environment of increasing partisanship.”
This is a tough issue, but ultimately I lean toward preferring that ten misleading tweets circulate freely rather than one tweet being unjustly annotated. We’ve already witnessed years of fact-checking that was bold, grounded in the belief that “we know the truth, and we know one side lies far more often than the other.” What was the result?

Frankly, there’s widespread distrust of the very concept of fact-checking. One strategy is to ignore critics, remember that fact-checking experts truly do know more about facts than any voting system, and persevere. But doubling down on this approach seems risky. Building cross-tribal institutions that are at least somewhat respected by all sides is valuable. Like William Blackstone’s maxim applied to courts, I believe maintaining such respect requires a system whose errors are omissions rather than active injustices. So to me, it seems valuable that at least one major organization takes this alternative path, treating its rare cross-tribal legitimacy as a precious resource.
Another reason I think it’s okay for Community Notes to be conservative is that I don’t believe every misleading tweet—or even most—should receive corrective annotations. Even if less than one percent of misleading tweets get contextual or corrective notes, Community Notes still serves an extremely valuable educational role. The goal isn’t to correct everything; rather, it’s to remind people that multiple perspectives exist, that some posts appearing compelling in isolation are actually quite wrong, and that yes, you usually can perform a basic internet search to verify they’re false.
Community Notes cannot be, nor is it intended to be, a panacea solving all problems in public epistemology. Whatever gaps it leaves open, there’s ample room for other mechanisms to fill—whether novel tools like prediction markets or traditional organizations hiring full-time experts with domain knowledge.
Conclusion
Community Notes is not only a fascinating social media experiment but also a compelling example of an emerging type of mechanism design: systems consciously designed to identify extremism and favor bridging divides over reinforcing them.
Two other examples I know of in this category are: (i) the pairwise-quadratic funding mechanism used in Gitcoin Grants, and (ii) Polis, a discussion tool that uses clustering algorithms to help communities identify statements broadly supported across typically divided groups. This area of mechanism design is valuable, and I hope to see more academic work in this space.
The algorithmic transparency offered by Community Notes isn’t fully decentralized social media—if you disagree with how Community Notes works, you can’t view the same content through a different algorithm. But it’s the closest large-scale application we’ve seen so far, and it already delivers substantial value by preventing centralized manipulation and ensuring platforms that refrain from such manipulation earn proper recognition.
I look forward to seeing Community Notes and many similarly inspired algorithms grow and evolve over the next decade.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














