

發佈 ChatGPT 健康 6 天后,OpenAI 在自家醫療健康 Benchmark 上被反超
TechFlow Selected深潮精選
發佈 ChatGPT 健康 6 天后,OpenAI 在自家醫療健康 Benchmark 上被反超
百川智能表示今年上半年,將陸續發佈兩款 to C 的醫療產品。
作者:Li Yuan
你有沒有向 AI 助手問過你的健康問題?
如果你和我一樣是一個 AI 的深度用戶,大概率你也試過。
OpenAI 自己給出來的數據是,健康已成為 ChatGPT 最常見的使用場景之一,全球每週有超過 2.3 億人提出與健康和保健相關的問題。
正因如此,跨入 2026 年,健康領域也大有成為 AI 領域必爭之地的跡象了。
1 月 7 日,OpenAI 發佈 ChatGPT 健康,允許用戶連接電子醫療記錄和各類健康應用,讓用戶能夠獲得更針對性的醫療回覆;而 1 月 12 日,Anthropic 也立馬推出了 Claude for Healthcare,並強調了新模型的醫學場景能力。
不過有趣的是,這次,中國公司沒有落下,甚至大有領先之意。
1 月 13 日,百川智能宣佈發佈百川 M3 模型,在 OpenAI 發佈的醫療健康領域評估測試集 HealthBench,反超 OpenAI 的 GPT-5.2 High,獲得 SOTA。
在宣佈 All-in 醫療受到諸多質疑後,百川智能似乎終於證明了自己。極客公園此次也專程與王小川聊了聊百川智能如何看待此次 M3 模型的能力,以及 AI 醫療的終局。
01 首次在健康領域測試集超越 OpenAI
此次發佈的 M3 模型,最亮眼的成績之一,在於模型第一次在 OpenAI 發佈的醫療健康領域評估測試集 HealthBench,超越 OpenAI 的 GPT-5.2 High,獲得 SOTA。
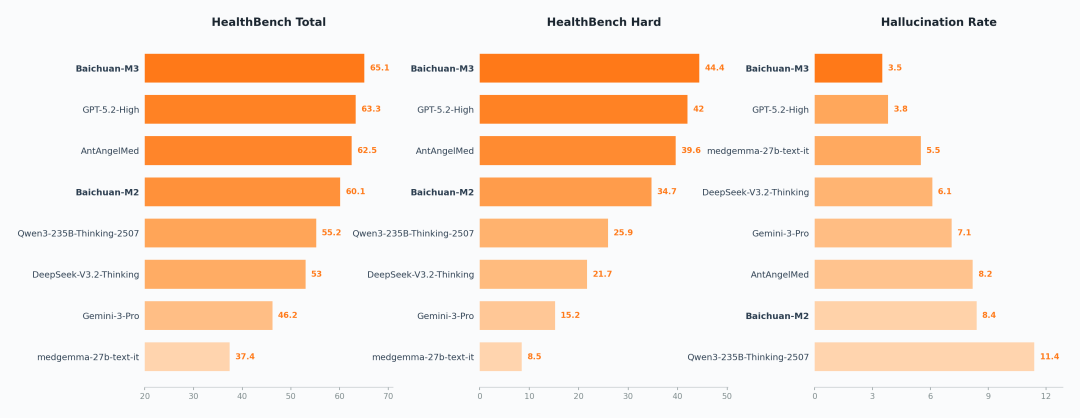
SOTA On Healthbench、Healthbench Hard and Hallucination Evaluation
Healthbench 是 OpenAI 在 2025 年 5 月份發佈的醫療健康領域評估測試集,由 262 位來自 60 個國家的醫生共同構建,收錄了 5000 組高度逼真的多輪醫療對話,是目前全球最權威、也最貼近真實臨床場景的醫療評測集之一。
發佈後,OpenAI 的模型一直霸榜。
而此次,百川智能的新一代開源醫療大模型 Baichuan-M3,則獲得了 65.1 分的綜合成績位列全球第一,甚至在專門考驗複雜決策能力的 HealthBench Hard 上,M3 也成功奪冠,刷新了最高分。
百川還同步公佈了一個幻覺率的測試結果,在幻覺率,M3 模型達到了 3.5%,屬於全球最低。
值得注意的是,這個幻覺率是不依賴外部檢索工具,純模型設置下的醫療幻覺率。
百川智能表示,能夠達到這兩點,關鍵的模型提升在於為醫療引入了合適於醫療的強化學習算法。
百川在 M3 模型上首次使用了 Fact Aware RL(事實感知強化學習)技術,達到了既讓模型不說套話,也不讓模型亂說話的效果。
這在醫療領域實際上是非常關鍵的。
在沒有優化的模型中提問醫療問題,最容易出現的問題就是兩類,一是模型直接胡編亂造你的症狀,臆測一個疾病出來;而另一個則是語義模糊,最終提示你還是得去看醫生,而這無論對於醫生還是患者,都沒有太大幫助。
這正是因為很多模型以純幻覺率作為優化目標,此時模型可能通過堆砌簡單正確的事實來稀釋整體幻覺率。而百川引入語義聚類與重要性加權機制——聚類消除冗餘表述的干擾,加權確保核心醫學論斷獲得更高權重。
同時,如果單純引入高權重的幻覺懲罰,極易迫使模型陷入「少說少錯」的保守策略,因此 Fact Aware RL 的算法中還設計了動態權重調節機制,根據模型當前的能力水平自適應地平衡這兩個目標——在能力構建階段,側重醫療知識的學習與表達(高 Task Weight);在能力成熟後,逐步收緊事實性約束(提升 Hallucination Weight)。
當可以聯網搜索時,百川還加入了基於多輪搜索的在線校驗模塊,同時引入了高效的緩存系統,進行海量醫療知識的對齊。
02 問診水平超過人類醫生,步入可用階段
不過,在 Healthbench 上超過 OpenAI 並不是此次唯一的亮點。
此次更有趣的一個點,百川自己創造性地構建了一個 SCAN-benche 評測集。比起刷榜 OpenAI 的評測集,百川自己構建的評測集,或許更能說明百川智能在醫療上想要優化的方向。
此次百川構建的測評集,關鍵點在於優化「端到端的問診能力」。這源於百川自己做的實驗洞察:問診準確度每增加 2%,診療結果準確度就會增加 1%。
也就是說相比於 OpenAI 的 HealthBench,仍然主要關注「AI 會不會回答問題」,百川的 SCAN-benche 希望評測出的是:AI 是否能在一問一答中,獲取有效信息,同時給出正確的診療結果和醫療意見。
通常情況下,我們向 AI 助手提問,如果只是提到「你是一位經驗豐富的醫生」,通常並不會得到太好的模型效果。因為真正的醫生,問診的流程是十分規範的——百川將其歸納為四個象限的 SCAN 原則:Safety Stratification(安全分層)、Clarity Matters(信息澄清)、Association & Inquiry(關聯追問)與 Normative Protocol(規範化輸出)。
圍繞 SCAN 原則,百川借鑑醫學教育里長期使用的 OSCE 方法,聯合 150 多位一線醫生,搭建了 SCAN-bench 評測體系,將診療過程拆解為病史採集、輔助檢查、精準診斷三大階段,通過動態、多輪的方式進行考核,完整模擬醫生從接診到確診的全過程,也以在這幾個流程中,都獲得更好的結果,來優化模型。
此次百川也公佈了 M3 模型在 SCAN-benche 上的測評結果。
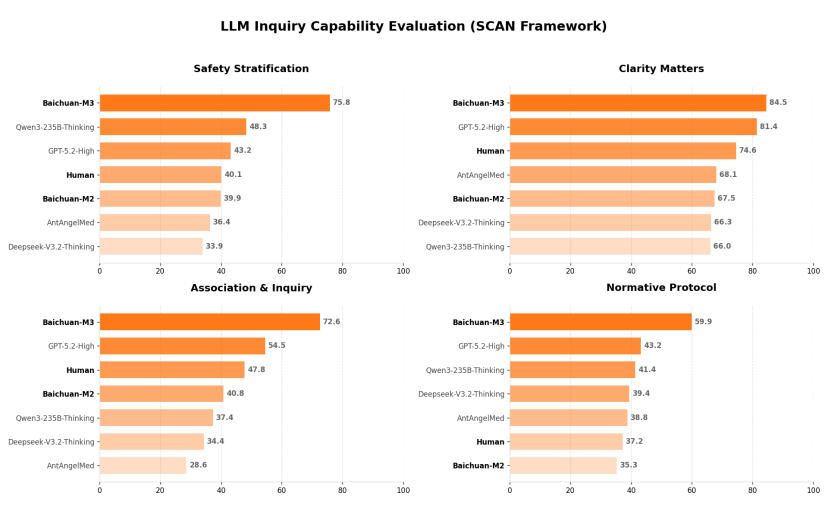
結果十分有趣。百川此次不僅和模型進行了對比,還找來了真人醫生進行對比。而在四個象限中,真人醫生實際上都已經落後於模型能夠達到的水平了。
極客公園特意對此向百川團隊進行了提問,得到的回答是:此次的測評,全都是真人的專科醫生在專科案例上與模型進行的比較。模型能夠獲勝,其一,在於模型更耐心,但更重要的是,模型擁有更好的跨學科的知識的掌握能力。
比如在一個案例中,提到 10 歲孩子反覆發熱,而發熱是一個非常綜合的醫療現象,如果只詢問咳嗽等肺部情況,就容易忽略關節和泌尿系統中的嚴重問題,誤判為普通感染。
人類醫生通常只對分科的病情比較擅長,這也是複雜症狀常常需要專家會診,或者疑難病症專家也常常要去翻書找資料的原因。
而沒有經過專門訓練,只是扮演醫生的普通模型,往往也很難回答好這類問題。
03 下一步:逐漸開始做 C 端產品,推進更嚴肅的醫療
對於百川智能而言,超過人類醫生這個節點,意義十分重大:這意味著 AI 開始邁過可用性的門檻,開始能夠被部署到使用場景中了。
從 1 月 13 日起,用戶已經可以開始在百小應的網站和 app 中,體驗到 M3 模型提供的回答了。
目前的網站設計十分有趣,雖然都是使用 M3 模型進行回答,但是區分醫生版和用戶版。在醫生版,回答更加簡潔,引用更多參考文獻,也更「不說人話」。而在普通病人版,模型幾乎不會一次性給出回答,都會進行更多追問,進行更明確的診斷。

百川智能提到,模型在後臺的思考很有意思。 「 我們經常能看到這個模型在思維鏈中提到,『這個患者沒有理我的這個問題,但是這個問題我必須要問。』甚至我們有看到過那種極端的,說我已經問了患者 20 輪了,這個已經超出了設定的最大輪數,但是這個問題我還是要問。這是因為在訓練的過程中模型把話說得討巧,是得不到獎勵的,它必須真的得到了足夠多的關鍵的信息,得到正確的診斷,才能得到獎勵。這個是我們跟其他人訓練模型的一個明顯的不同。」
近來很多 AI 公司都開始介入醫療領域。這也是百川智能認為自己的最大不同之處——要做更嚴肅的醫療。
「這意味著百川在選擇場景時,並不是看哪個場景最好做就去做哪個。相反,百川堅持要不斷上推技術能力,挑戰更難的問題。」王小川講到。
一個典型的例子是未來百川會優先做腫瘤專科的解決場景,而心理療愈排在百川的優先級的比較靠後的位置。
在通俗觀點中,普遍認為 AI 提供心理療愈會更簡單,也是一個更容易落地的場景。百川的判斷邏輯則不同。他們認為腫瘤領域有更嚴格的科學依據。在這裡,AI 更有可能做出嚴肅的醫療效果,從而達到或者超越人類醫生的水平。相比之下,心理學領域缺乏這種確定性的科學錨點。
再比如有的公司選擇給醫生做分身,王小川則認為這種方向並不是百川想要做的方向。醫生的分身本身不能完整複用醫生的水平,更不能超越醫生的水平。這樣的 AI 最終只能淪為幌子和獲客工具,並不能真正推動嚴肅醫療。
這種對嚴肅性的堅持,深刻影響了百川的很多商業選擇。
這直接關係到王小川對醫療 AI 下個階段根本問題的思考。他認為,當前這個階段最重要的任務是在增強 AI 能力的基礎上,逐漸提供更多的醫療供給。
中國多年來一直嘗試推行分級診療和全科醫生制度。初衷是希望老百姓先在基層看病,解決大醫院掛號難、排隊長、擁堵不堪的現狀。
這個制度之所以推行困難,本質上是因為醫療資源的供給不足。基層醫療機構缺乏高水平的醫生。大家即便只是感冒也願意去三甲醫院排隊,是因為對基層的診療水平不放心。
這正是醫療 AI 發揮作用的關鍵點。大模型能夠把頂尖的醫學知識實現規模化分發。它填補了基層的供給缺口,讓每一個社區、每一個家庭都能擁有像三甲醫院專家一樣的診療能力。
而長遠來開,這還能有更廣泛的影響,可能讓醫療的讓決策權從醫生手中逐漸轉移到用戶身上。在傳統的醫療場景中,患者是利益的受益方,但往往沒有決策權。決策權集中在醫生手中。這種權力的不對稱往往會帶來溝通成本和治療中的痛苦。
而百川希望通過 AI,讓患者能夠更容易地獲得優質醫療資源的供給。「很多人覺得醫療太複雜了,患者是永遠理解不了的。但我們想的在美國的司法體系裡面有個叫陪審團制度。法律也是非常專業的一個事,陪審團的普通人不懂,那就要求在法官、律師和檢察官能夠進行帶領,做充分的辯論,把話說清楚,說到一個普通人能判斷有罪沒罪的程度,讓普通人能依據邏輯正常判斷即可。」王小川講到。
這也是百川智能不願意只做簡單場景,而是希望不斷向高難度的嚴肅診療推進的原因之一。
當被問到解決高難度問題是否在商業上最有回報時,王小川給出了深刻的回答。
他認為,解決感冒發燒這類小問題,很難在用戶心中建立起足夠的信任。醫療是一個高度依賴信任的行業。只有當 AI 能夠解決重疾等高難度難題時,才能真正建立起信任的基礎。
從商業邏輯上看,患者面對嚴肅的健康問題時,也更有意願為高質量的 AI 服務付費。這種信任不僅是商業回報的前提,更是 AI 醫療能夠規模化應用的核心。
而從更根本的意義上講,醫療對於百川智能和王小川本人而言,仍然意味著是一條接近通用人工智能(AGI)的路徑。
王小川認為,AI 目前在文、理、工、藝等領域都已找到了切實的解法,醫療則是一個極為獨特的領域。人類對醫學的探索尚未窮盡,AI 在這一領域也正處於摸索階段。
百川的路線圖非常清晰。首先通過 AI 提升診病效率,解決當前醫療供給短缺的問題。在此基礎上,百川致力於建立與患者之間的深度信任。當患者願意使用 AI 工具,長期進行醫療諮詢,AI 就能在長期的陪伴中積累真實且高質量的醫療數據。
這些數據的終極目標是構建生命的數學模型。這是一條人類醫生至今尚未完全走通的道路,未來很有可能由 AI 率先實現。如果能完成對生命本質的建模,這將成為推動通用人工智能邁向更高階進步的關鍵一步。
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News










