

最佳優化水平:從機器學習中汲取目標最大化的經驗
TechFlow Selected深潮精選
最佳優化水平:從機器學習中汲取目標最大化的經驗
效率低不行,但是很高就一定好嗎?
撰文:DAN SHIPPER
編譯:Ines
Midjourney prompt:「從即將過橋的人的視角,想象一座繩板吊橋橫跨巨大而危險的天塹,水彩畫。」
我應該優化到什麼程度?這是我經常問自己的一個問題,我想你也一定問過。如果你在為一個目標進行優化,比如建立一家世代相傳的公司,尋找完美的生活伴侶,亦或是設計一套完美的鍛鍊計劃,那麼你的傾向就是努力做到盡善盡美。
優化是對完美的追求 -- 我們向著目標優化是因為不想將就。但是,一味追求完美是否更好呢?換句話說,優化到什麼程度才算過了?
長期以來,人們一直在試圖弄清楚優化的難度。你可以把他們放在一個光譜上。
一邊是約翰·梅爾(John Mayer),他認為少即是多。在他的代表作《地心引力》中,他唱道:
「哦,兩倍的好並不是真的有兩倍那麼好 / 也不能像一半那樣長久 / 想要更多的東西會將我逼至俯首。」
多莉·帕頓(Dolly Parton)則持相反意見。她的名言是:「少並不代表多。多就是多。」
亞里士多德不同意這兩種觀點。他在 2000 年前就提出了黃金分割點:當你針對一個目標進行優化時,你需要的是過多和過少之間的中間值。
我們該選哪一個呢?現在是 2023 年。我們希望在這個問題上多一點量化,少一點空泛。理想情況下,我們可以用某種方法來衡量針對目標進行優化的效果如何。
如今,我們經常可以向機器尋求幫助。目標優化是機器學習和人工智能研究人員研究的關鍵內容之一。為了讓神經網絡做任何有用的事情,你必須給它一個目標,並努力讓它更好地實現這個目標。計算機科學家在神經網絡方面找到的答案,可以教給我們很多關於優化的一般知識。
機器學習研究員 Jascha Sohl-Dickstein 最近發表的一篇文章讓我感到特別興奮,他提出了以下觀點:
機器學習告訴我們,過多地針對目標進行優化會讓事情變得錯得離譜 -- 你可以通過量化的方式看到這一點。當機器學習算法過度優化目標時,往往會忽略全局,導致研究人員所說的「過度擬合」。在實踐中,當我們過度專注於完善某個流程或任務時,我們就會過於適應手頭的任務,而無法有效地應對變化或新挑戰。
因此,說到優化——事實上,「多」並不意味著「多」。接招吧,多莉·帕頓。
這篇文章是我試圖總結亞薩(Jachsa)的文章,並用通俗易懂的語言解釋他的觀點。為了理解這一點,讓我們來看看機器學習模型的訓練是如何進行的。
Mindsera 利用人工智能幫助你發掘隱藏的思維模式,揭示思維盲點,更好地瞭解自己。
你可以根據有用的框架和心智模式,利用日誌模板來構建自己的思維,從而做出更好的決定,改善自己的健康狀況,提高工作效率。
Mindsera 人工智能導師模仿馬庫斯·奧勒留(Marcus Aurelius)和蘇格拉底(Socrates)等思想巨人的思維,為你提供洞察力的新途徑。
智能分析會根據你的寫作生成原創作品,測量你的情緒狀態,反映你的個性,並給出個性化建議,幫助你提高。
建立自我意識,理清思路,在日益不確定的世界中取得成功。
開始吧。
想要成為志願者?可戳此處。
👉https://www.passionfroot.me/every
過於高效會使一切變得更糟
設想一下,你期望創建一個機器學習模型,它在分類狗的圖片上有著出色的表現。你希望能夠輸入一張狗的照片,並獲得相應的狗的品種。但你不只是希望得到一個常規的狗圖片分類器。你追求的是無以倫比的機器學習分類器,不計代價、不懈編程、藉助無數的咖啡。(畢竟,我們正在優化。)
那麼,如何達成這一願景呢?雖然有多種策略,但你很可能選擇使用監督學習。監督學習猶如為你的機器學習模型配備一位導師:它通過不斷向模型提問並在其出錯時進行指正,讓模型逐漸熟悉並掌握問題的答案。在此訓練過程中,模型將逐步提高其答題的準確性。
首先,你需要準備一個圖片數據集來訓練你的模型。你為這些圖片預先定義好標籤,如:「貴賓犬」,「可卡貴賓」,「丹迪丁蒙梗」等。接著,你將這些圖片及其對應的標籤輸入到模型中,讓模型開始其學習之旅。
模型的學習方法很像是一個「試錯」過程。你展示一個圖片給它,它嘗試猜測這張圖片的標籤。如果答案不對,你會對模型進行微調,以期它下次能夠給出更為準確的答案。堅持這樣的方法,隨著時間的流逝,你會發現模型在預測訓練集內圖片的標籤時表現得越來越出色。
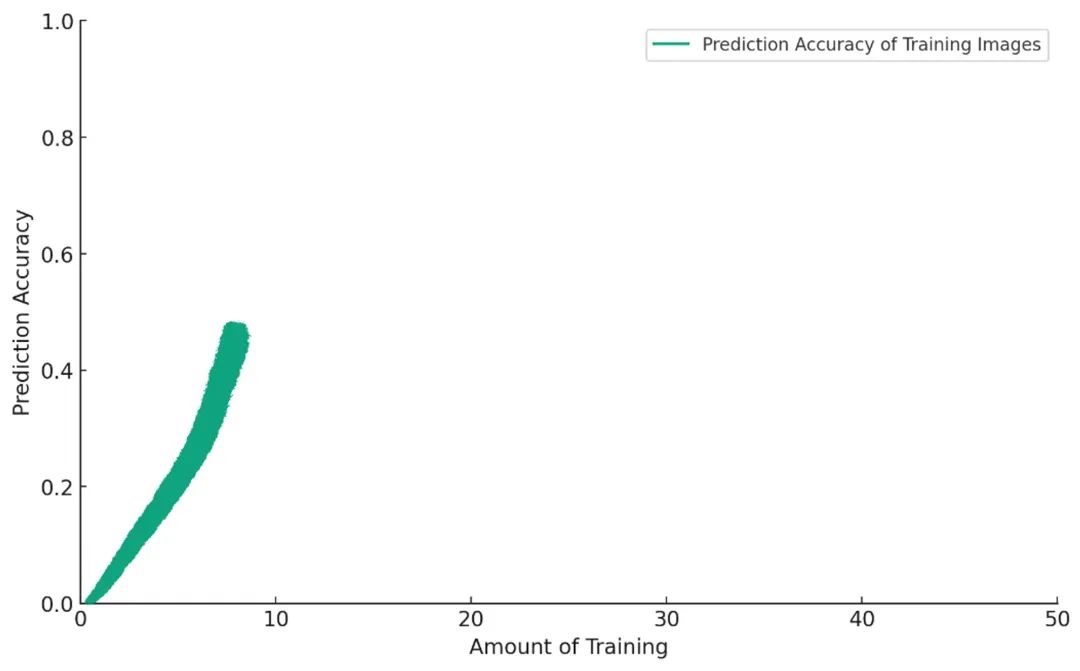
現在,模型在預測訓練集中的圖片標籤上表現得越來越好,你為它設置了一個新任務。你要求模型為那些它在訓練中從未見過的狗的圖片打標籤。
這是一個重要的測試:如果你只詢問模型之前見過的圖片,這就有點像是讓它在測試中作弊。因此,你再找來一些確信模型沒見過的狗的圖片。
起初,一切都非常順利。你越是訓練模型,它的表現就越好:
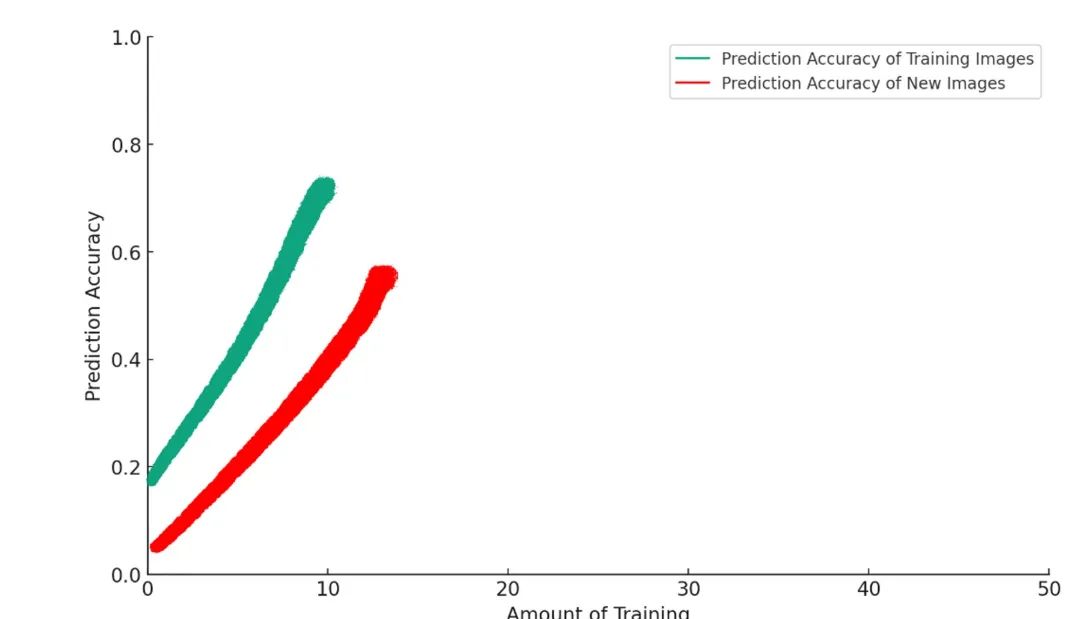
但如果你繼續訓練,模型將開始做出類似 AI 版的「在地毯上拉屎」的行為:這到底是怎麼回事?
這裡發生了什麼?
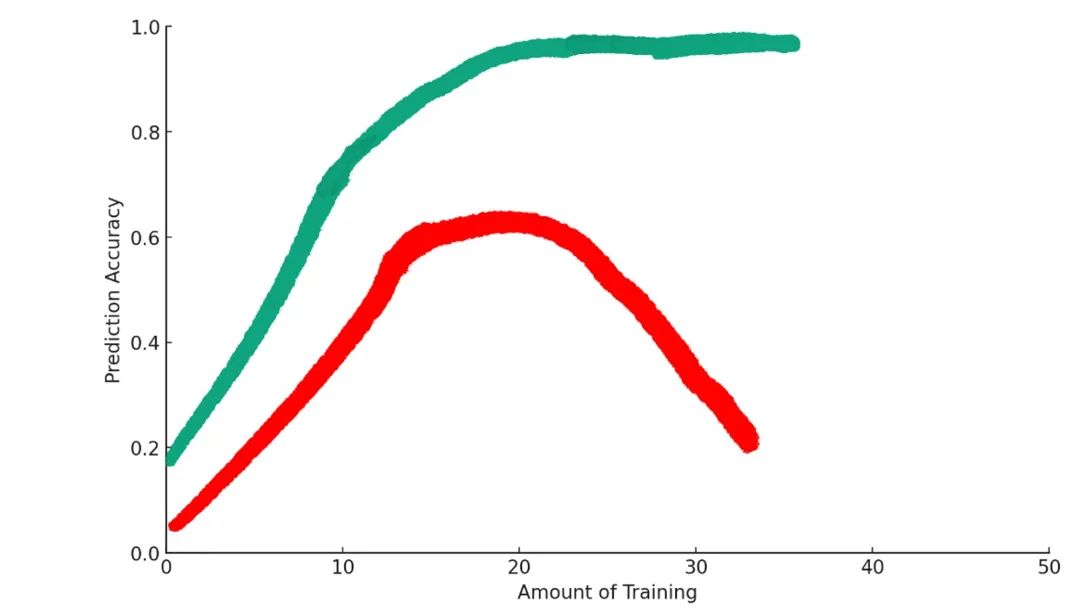
一些訓練會使模型在達到目標上更加優化。但是超過某個點,過多的訓練實際上會使情況變得更糟。這在機器學習中是一個被稱為「過擬合」的現象。
為什麼過擬合會使事情變得更糟
在模型訓練中,我們其實進行了一種微妙的操作。
我們希望模型能夠很好地為任意的狗狗圖片打上標籤——這是我們真正的目標。但我們不能直接為此進行優化,因為我們不可能獲取所有可能的狗狗圖片。取而代之的是,我們為一個代理目標進行優化:一個我們希望能代表真正目標的狗狗圖片的小子集。
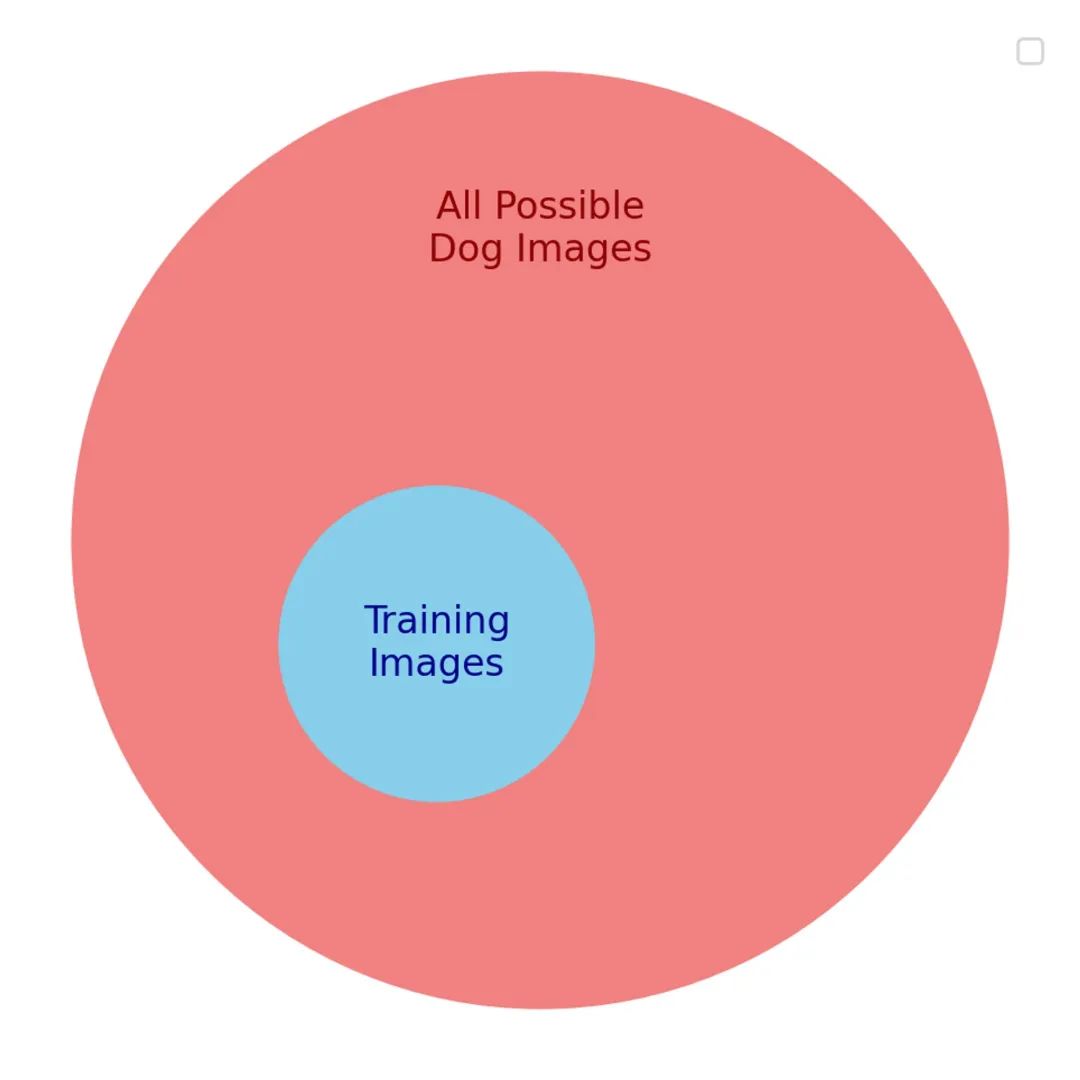
在代理目標和真實目標之間,有很多相似之處。因此在開始時,模型在這兩個目標上都得到了進步。但隨著模型訓練得越來越深入,這兩個目標之間有用的相似性逐漸減少。很快,模型僅僅擅長識別訓練集中的內容,而對其他內容則處理得不佳。
隨著模型的繼續訓練,它開始過於依賴你用來訓練它的數據集的細節。例如,可能訓練數據集中有過多的黃色拉布拉多貴賓犬的圖片。當模型過度訓練時,它可能錯誤地學習到所有黃色的狗都是拉布拉多貴賓犬。
當模型遇到與訓練數據集特性不同的新圖片時,這種過擬合的模型會表現得很糟糕。
過擬合揭示了我們在目標優化探索中的一個重要觀點。
首先,當你試圖優化任何事物時,你很少是直接優化該事物 —— 你優化的是一個替代措施。在狗狗分類問題中,我們不能針對所有可能的狗的圖片來訓練模型。相反,我們試圖對一組狗的圖片子集進行優化,並希望這能夠有效地泛化。它確實可以 —— 直到我們過度優化。
這也帶來了第二個觀點:當你過度優化一個代理函數時,你實際上會遠離你最初的目標。
一旦你瞭解了機器學習中的這種機制,你會開始在各處都能觀察到它。
如何將過擬合應用到現實世界
以學校為例:
在學校,我們希望優化對我們所學課程的學科知識的學習。但要衡量你對某個知識瞭解得有多深入是困難的,因此我們進行標準化測試。標準化測試在某種程度上可以很好地代表你是否瞭解一個學科。
但當學生和學校對標準化考試成績施加太大壓力時,優化考試成績的壓力開始損害真正的學習。學生變得過於適應提高考試分數的過程。他們學會如何參加考試(或作弊)以優化他們的分數,而不是真正地學習學科知識。
商業世界中也存在過擬合。在書籍《Fooled by Randomness》中,Nassim Taleb 寫到了一位名叫 Carlos 的銀行家,他是新興市場債券的一個穿著考究的交易員。他的交易風格是逢低買入:1995 年墨西哥貨幣貶值時,Carlos 低點買入,並在危機解除後債券價格上漲時獲利。
這種逢低買入的策略為他的公司帶來了 8000 萬美元的淨收益。但 Carlos 變得「過度適應」他所接觸的市場,而他對優化回報的追求最終導致了他的失敗。
1998 年夏天,他在一個低點買入了俄羅斯債券。隨著夏天的到來,跌勢加劇——Carlos 繼續買入。Carlos 不斷加倍下注,直到債券價格非常低,他最終損失了 3 億美元——這是他到那時為止在整個職業生涯中所賺取的三倍。
正如 Taleb 在他的書中指出的那樣,「在市場上,最成功的交易員可能是那些最適應最新週期的人。」
換句話說,過度優化回報可能意味著過度適應當前的市場週期。你的績效會在短期內顯著提高。但當前的市場週期只是市場行為整體的一個代表——當週期發生變化時,你之前成功的策略可能會突然使你破產。
相同的啟發適用於我的業務。Every 做的是訂閱制媒體的生意,我想要增加 MRR(每月重複收入)。為了實現這個目標,我可以通過獎勵作者獲得更多的頁面瀏覽量來增加我們的文章的流量。
這很可能會起作用!增加流量確實會增加我們的付費訂閱者——到一定程度。過了那個點,我敢打賭作者會開始通過點擊誘餌或者淫穢的文章提高頁面瀏覽量,這些文章不會吸引那些願意付費的、參與度高的讀者。最終,如果我把 Every 變成一個點擊誘餌工廠,我們的付費訂閱者可能會減少,而不是增長。
如果你繼續觀察你的生活或你的業務,你肯定會發現同樣的模式。問題是:我們該怎麼辦?
那麼,我們應該怎麼做呢?
機器學習研究者使用許多技術來防止過擬合。Jascha 的文章告訴我們可以採取的三大措施:提早停止、引入隨機噪聲和正則化。
提早停止
這意味著要始終檢查模型在其真正目標上的性能,並在性能開始下降時暫停訓練。
在 Carlos 的案例中,他是一位交易員,在購買債券下跌時損失了所有的資金,這可能意味著需要一個嚴格的虧損控制機制,迫使他在累計虧損達到一定數額後強制他解除交易。
引入隨機噪音
如果在機器學習模型的輸入或參數中引入噪音,它將更難出現過擬合現象。同樣的原理也適用於其他系統。
對於學生和學校來說,這可能意味著在隨機時間進行標準化測試,以增加填鴨式備考的難度。
正則化
在機器學習中,正則化用於對模型進行懲罰,以防止其變得過於複雜。模型越複雜,越容易對數據過擬合。這其中的技術細節並不是太重要,但在機器學習之外的其他系統中,可以應用同樣的概念來增加系統內的摩擦。
如果我想激勵 Every 的所有作者,通過提高頁面瀏覽量來增加我們的月度重複收入,我可以修改獎勵頁面瀏覽量的方式,使超過一定閾值的任何頁面瀏覽量逐漸減少計入。
這些都是解決過擬合問題的潛在解決方案,這再次引出了我們最初的問題:優化的最佳水平是什麼?
最佳優化水平
我們所學到的主要教訓是,你幾乎永遠無法直接為一個目標進行優化 - 相反,你通常是在為看起來像你的目標但略有不同的東西進行優化。它是一個代理。
因為你必須為代理進行優化,當你優化得太多時,你會過於擅長最大化你的代理目標 - 這往往會使你遠離真正的目標。
因此,需要牢記的一點是:知道你正在為什麼進行優化。要知道目標的代理並非目標本身。在優化過程中要保持靈活,當看起來你的代理目標與實際目標之間的有用相似性已經用盡時,要準備停止或切換策略。
至於約翰·梅爾(John Mayer)、多莉·帕頓(Dolly Parton)和亞里士多德(Aristotle)在優化智慧方面的看法,我認為我們必須把獎項頒給亞里士多德和他的黃金分割點。
當你為一個目標進行優化時,最佳的優化水平在過多和過少之間。它是「恰到好處」。
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News










