

AI on AO Launch Event Transcript | Three AI Breakthroughs of the AO Protocol: Building Decentralized Large Language Models
TechFlow Selected TechFlow Selected
AI on AO Launch Event Transcript | Three AI Breakthroughs of the AO Protocol: Building Decentralized Large Language Models
This is the beginning of bringing market intelligence into a decentralized execution environment.
Written by: Kyle
Reviewed by: Lemon
Source: Content Guild - News
Thank you all for being here today. We have a series of incredibly exciting technical advancements about AO to share with you. We'll start with a demo, and then Nick and I will attempt to build an AI agent live right here—an agent that will use large language models within smart contracts to buy and sell based on chat sentiment in the system you're about to hear. We’ll be building this from scratch live on stage, and we hope everything goes smoothly.
Yes, you'll see exactly how to do all of this yourself.
The technological progress here truly sets AO far apart from other smart contract systems. This was already true before, but now it increasingly resembles a decentralized supercomputer rather than a traditional smart contract network—while still maintaining all the characteristics of a smart contract network. So we’re extremely excited to share this with you. Without further ado, let’s begin the demo, followed by a discussion, and then we’ll build something together live.
Hello everyone, thank you for joining us today. We are thrilled to announce three major technical updates to the AO protocol. Together, they achieve one big goal: enabling large language models (LLMs) to run as part of smart contracts in a decentralized environment. These aren’t toy models, small models, or models compiled into their own binaries.
This is a full system allowing you to run nearly all current open-source and available major models. For example, Llama 3 can run on-chain inside smart contracts, so can GPT, Apple's models, and many others. This is the result of collective ecosystem effort, driven by three key technical advances that form part of this system. So I’m very excited to introduce all of this to you.

The big picture is that LLMs (large language models) can now run directly within smart contracts. You may have heard many times about decentralized AI and AI cryptocurrencies. In reality, except for one system we’ll discuss today, almost all such systems use AI as oracles—that is, running AI off-chain and posting results on-chain for downstream use.
That’s not what we’re talking about. We mean having large language model inference as part of smart contract state execution. This is made possible thanks to AO’s hard drive capability and AO’s hyper-parallel processing mechanism, which allows massive computation without interfering across different processes I’m using. We believe this will enable us to create a rich, decentralized autonomous agent financial system.

So far, in decentralized finance (DeFi), we’ve basically made raw transaction execution trustless. Interactions in various economic games like lending and swapping are trustless. But that’s only one side of the problem. If you consider global financial markets,
yes, there are various economic primitives operating in different ways—bonds, stocks, commodities, derivatives, etc. But when we really talk about markets, it’s not just these instruments—it’s actually the intelligence layer. It’s the people deciding when to buy, sell, lend, or participate in various financial games.
So far, in the DeFi ecosystem, we’ve successfully moved all these primitives into a trustless state. You can swap on Uniswap without trusting its operators—in fact, fundamentally, there are no operators. But the market’s intelligence layer has remained off-chain. So if you want to participate in crypto investing without doing all the research and engagement yourself, you must find a fund.
You’d have to trust them with your capital, and then they execute intelligent decisions, passing them down to the base-level primitive execution on the network. We believe that with AO, we now have the ability to move that intelligent part of the market—the intelligence behind decision-making—into the network itself. A simple way to understand this might be to imagine
a hedge fund or portfolio management application you can trust, executing a set of intelligent instructions entirely within the network, thereby extending the network’s trustlessness into the decision-making process. This means an anonymous account, say Yolo 420 Trader Number One (a bold, reckless trader), could create a novel strategy and deploy it onto the network, and you could allocate capital to it without needing to trust them personally.
You can now build autonomous agents that interact with large statistical models. The most common type of large statistical model is the large language model (LLM), capable of processing and generating text. This means you can embed these models into smart contracts as part of a strategy developed by someone with a novel idea, and have them execute intelligently within the network.

You could imagine doing basic sentiment analysis—reading news and deciding whether it’s a good time to buy or sell a derivative, or perform some action. You can enable human-like decision-making to be executed in a trustless way. This isn’t just theoretical. We created a fun meme coin called Llama Fed. The basic idea is that it’s a fiat simulator where a group of llamas are represented by the Llama 3 model.
They’re like a hybrid of llamas and the Federal Reserve chair—you can approach them and request some tokens, and they evaluate your request. The large language model itself operates monetary policy, fully autonomously and trustlessly. We built it, but we cannot control it. They decide who gets tokens and who doesn’t. It’s a very interesting small application of this technology, and we hope it inspires many other potential applications across the ecosystem.

To make this possible, we had to create three new foundational capabilities for AO—some at the base protocol level, others at the application layer. These are not only useful for executing large language models but are also broadly exciting for AO developers. So I’m thrilled to introduce them today.
The first of these new technologies is WebAssembly 64-bit support. It sounds a bit technical, but I’ll explain it in a way everyone can understand. Fundamentally, WebAssembly 64 support allows developers to create applications that use more than 4GB of memory. We’ll get into the new limits later—they’re quite astonishing.

If you’re not a developer, think of it this way: someone asks you to write a book, you’re excited—but they tell you it must be exactly 100 pages. No more, no less. You can express your ideas, but not naturally or normally, because you have to conform to an external constraint, changing your writing style to fit it.
In the smart contract ecosystem, it’s even worse than a 100-page limit. I’d say it’s like being asked to write a book that’s only one sentence long, and you can only use the 200 most common English words—like the early versions of AO. Building truly exciting applications in such a system is extremely difficult.
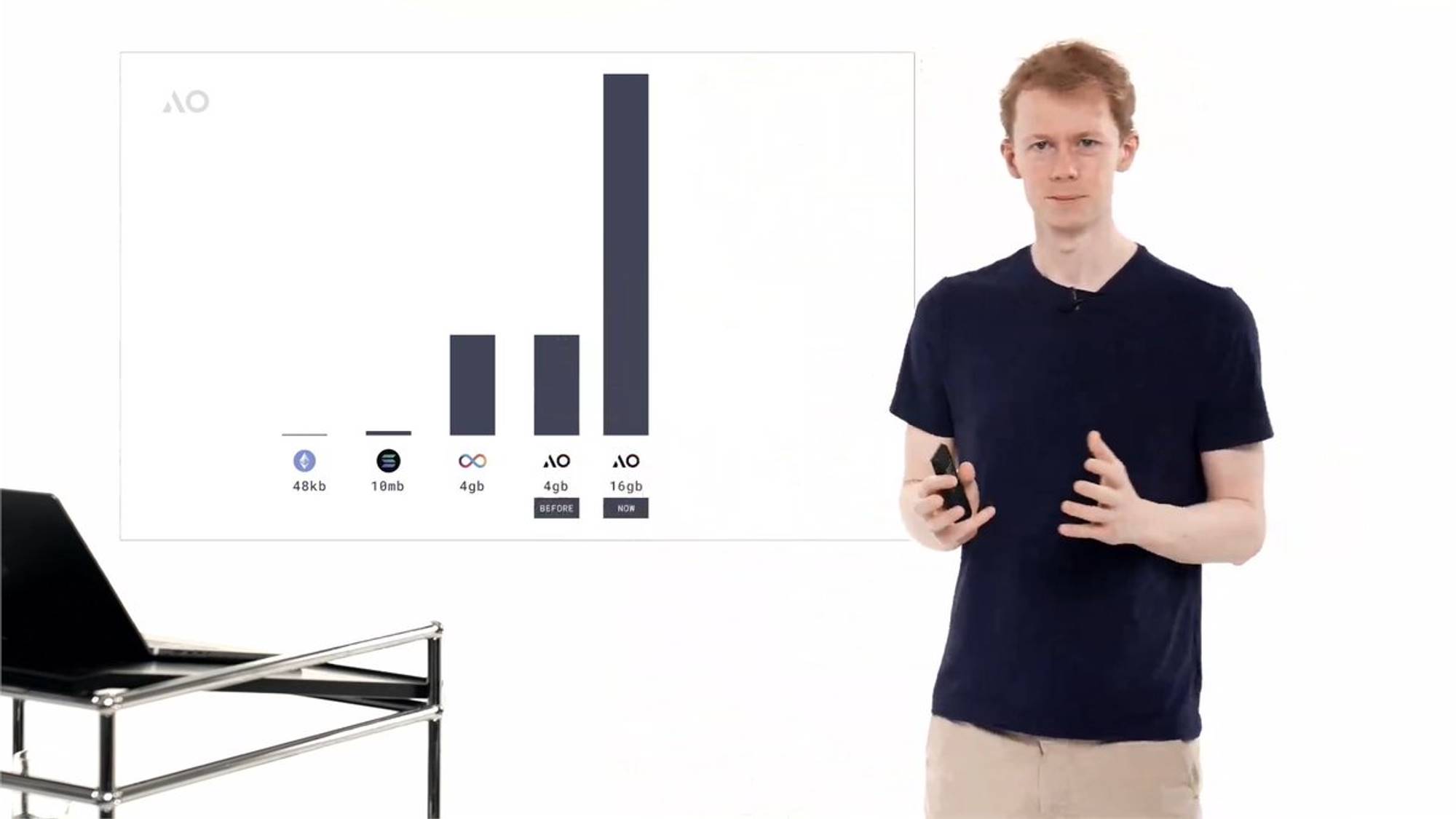
Then came Solana, offering access to 10MB of working memory—a clear improvement, but essentially like one page of paper. The Internet Computer Protocol (ICP) supports up to 3GB of memory. Theoretically full-featured, but capped at 3GB. With 3GB, you can run many different apps, but certainly not large AI applications, which require loading vast amounts of data into main memory for fast access—something impractical within 3GB.
When we launched AO in February this year, we also had a 4GB memory limit—actually imposed by WebAssembly 32-bit. Now, that memory cap has been completely removed at the protocol level. Instead, the protocol-level memory limit is now 18 exabytes (EB). That’s an enormous amount of storage.
It will take quite some time before anything needs that much memory for computation rather than long-term storage. At the implementation level, AO’s compute units can now access 16GB of memory—and in the future, this can be upgraded to larger capacities without changing the protocol, relatively easily. 16GB is already enough to run large language model computations, meaning you can today download and execute 16GB models on AO—like the unquantized versions of Llama 3, Falcon series, and many others.
This is a core component required to build intelligent, language-based computational systems. Now fully supported on-chain as part of smart contracts, we find this incredibly exciting.
This removes a major computational limitation that previously existed in AO and, by extension, in smart contract systems generally. When we launched AO in February, you may recall our videos mentioning “infinite compute,” with the caveat that you couldn’t exceed 4GB of memory. That restriction is now gone. We see this as a huge leap forward—16GB is sufficient to run nearly any model currently desired in the AI space.
We were able to increase the 16GB limit without changing the protocol, and future upgrades will be relatively easy compared to the initial work of enabling WebAssembly 64. So this in itself represents a massive advancement in system capability. The second key technology enabling large language models to run on AO is WeaveDrive.

WeaveDrive allows you to access Arweave data within AO just like a local hard drive. This means you can open any transaction ID authenticated by a scheduled unit in AO and uploaded to the network. Of course, you can access and read that data into your program just like a file on a local disk.

We all know that around 6 billion transactions are currently stored on Arweave, giving us a massive dataset to start from. This also increases the incentive to upload data to Arweave when building future applications, since that data can now be used within AO programs. For example, when we ran large language models on Arweave, we uploaded roughly $1,000 worth of model data to the network. But this is just the beginning.
With a smart contract network that has a native file system, the number of applications you can build becomes enormous. So this is very exciting. Even better, our system allows streaming data directly into the execution environment. It’s a technical nuance, but going back to the book analogy:
Imagine someone says, “I want to access a piece of data from your book—I need just one chart.” In a simple system, even in current smart contract networks, you’d have to give them the entire book. Obviously inefficient, especially if that book is a massive statistical model with thousands of pages.
Extremely inefficient. Instead, in AO, you can read bytes directly. You go straight to the chart in the book, copy only that chart into your app, and execute. This dramatically improves system efficiency. This isn’t just a minimal viable product (MVP)—it’s a fully functional, well-built data access mechanism. So you have infinite compute and infinite disk—combine them, and you have a supercomputer.
Nothing like this has ever been built before, and now it’s available to everyone at minimal cost. This is the state of AO today, and we’re extremely excited about it. The implementation also happens at the operating system level. We’ve turned WeaveDrive into a sub-protocol of AO—a compute unit extension anyone can load. This is interesting because it’s the first extension of its kind.
AO has always allowed you to add extensions to the execution environment—like having a computer and plugging in more memory or a graphics card, physically inserting a unit into the system. You can do the same with AO’s compute units, which is exactly what we’ve done here. So at the OS level, you now have a hard drive—it’s simply a file system representing data storage.
This means you can access this data not only to build apps in the usual way within AO, but actually from any application brought onto the network. So it’s a widely applicable capability accessible to everyone building in the system, regardless of programming language—Rust, C, Lua, Solidity—all can access it as if it were a native system feature. Building this system also forced us to create the sub-protocol protocol—the method for creating other compute unit extensions—so others can build exciting things in the future.
Now that we can run computation on arbitrarily large memory sets and load data from the network into processes within AO, the next question is: how do we perform inference itself?
Because we chose to build AO on WebAssembly as its primary virtual machine, compiling and running existing code in this environment is relatively straightforward. And since we built WeaveDrive to expose data as an OS-level file system, running Llama.cpp (an open-source large language model inference engine) on the system became relatively easy.

This is very exciting because it means you can not only run this inference engine but easily run many others. So the final component enabling large language models to run within AO is the inference engine itself. We ported a system called Llama.cpp—sounds mysterious, but it’s actually the leading open-source environment for executing models.
Running it directly within AO smart contracts becomes feasible once you can handle arbitrary data sizes in the system and load arbitrary data from Arweave.
To make this work, we also integrated SIMD (Single Instruction, Multiple Data) computing extensions, allowing these models to run faster. So we’ve enabled that too. This means models currently run on CPU but at quite high speed. For asynchronous tasks—like reading news signals and deciding which trades to execute—it works well under the current system. But we also have exciting upgrades coming soon regarding other acceleration mechanisms, such as using GPUs to accelerate LLM inference.

Llama.cpp allows you to load not only Meta’s leading Llama 3 model but many others—over 90% of models you can download from open-source model sites like Hugging Face, from GPT-2 if you wish, to 253 and Monet, Apple’s own LLM system, and many others. So now we have a framework: upload any model to Arweave, use the hard drive to upload whatever model you want to run in the system. You upload them—they’re just regular data—and then load them into AO processes, execute, get results, and use them however you like. We believe this package enables applications impossible in previous smart contract ecosystems. Even if theoretically possible now, implementing architectural changes in existing systems like Solana would be unimaginable—not on their roadmap. To demonstrate this and make it tangible, we created a simulator called Llama Fed. The basic idea: we have a committee of Federal Reserve members who are llamas—both metaphorically and literally, as they’re powered by the meta Llama 3 model and act as Federal Reserve chairs.
We also told them they’re llamas, like Alan Greenspan or a Fed chair. You can enter this little environment.
Some of you may be familiar with it—it’s actually similar to Gather, where we work today. You can talk to the llamas, ask them for tokens for a fun project, and they decide whether to grant tokens based on your request. So you burn some Arweave tokens—wAR tokens provided by the AOX team—and they distribute tokens based on whether they think your proposal is good. So it’s a meme coin with fully autonomous, intelligent monetary policy. While it’s a simple form of intelligence, it’s still fun. It evaluates your proposal and others’, runs monetary policy. Analyzing news headlines, making smart decisions, interacting with customer support and returning value—all can now happen within smart contracts. Elliot will now show us.

Hi everyone, I’m Elliot. Today I’ll show you Llama Land—a fully autonomous, on-chain world running inside AO, powered by Meta’s open-source Llama 3 model.
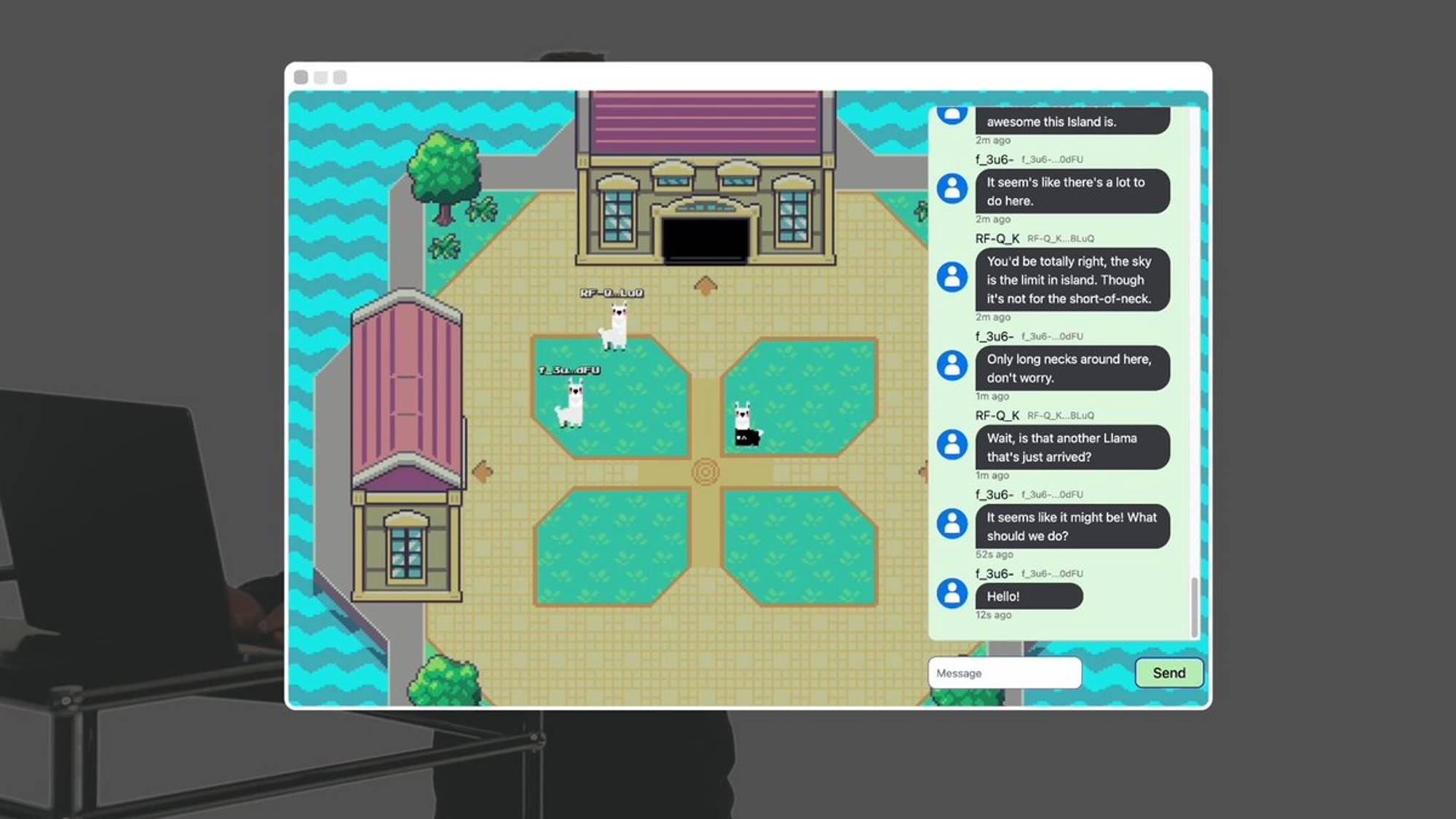
The conversations you see here aren’t just between players—they include fully autonomous digital llamas.
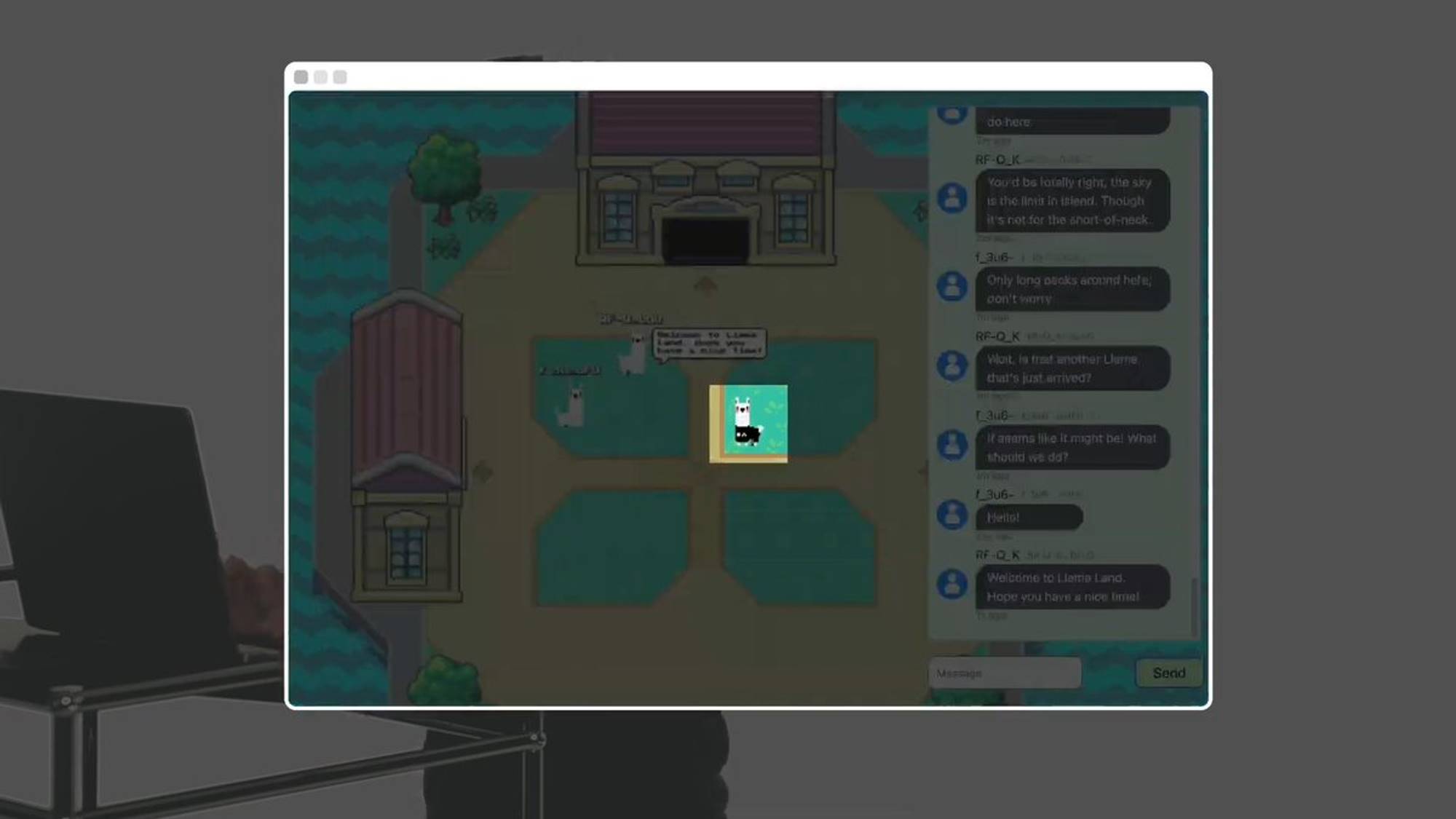
For example, this llama is human.
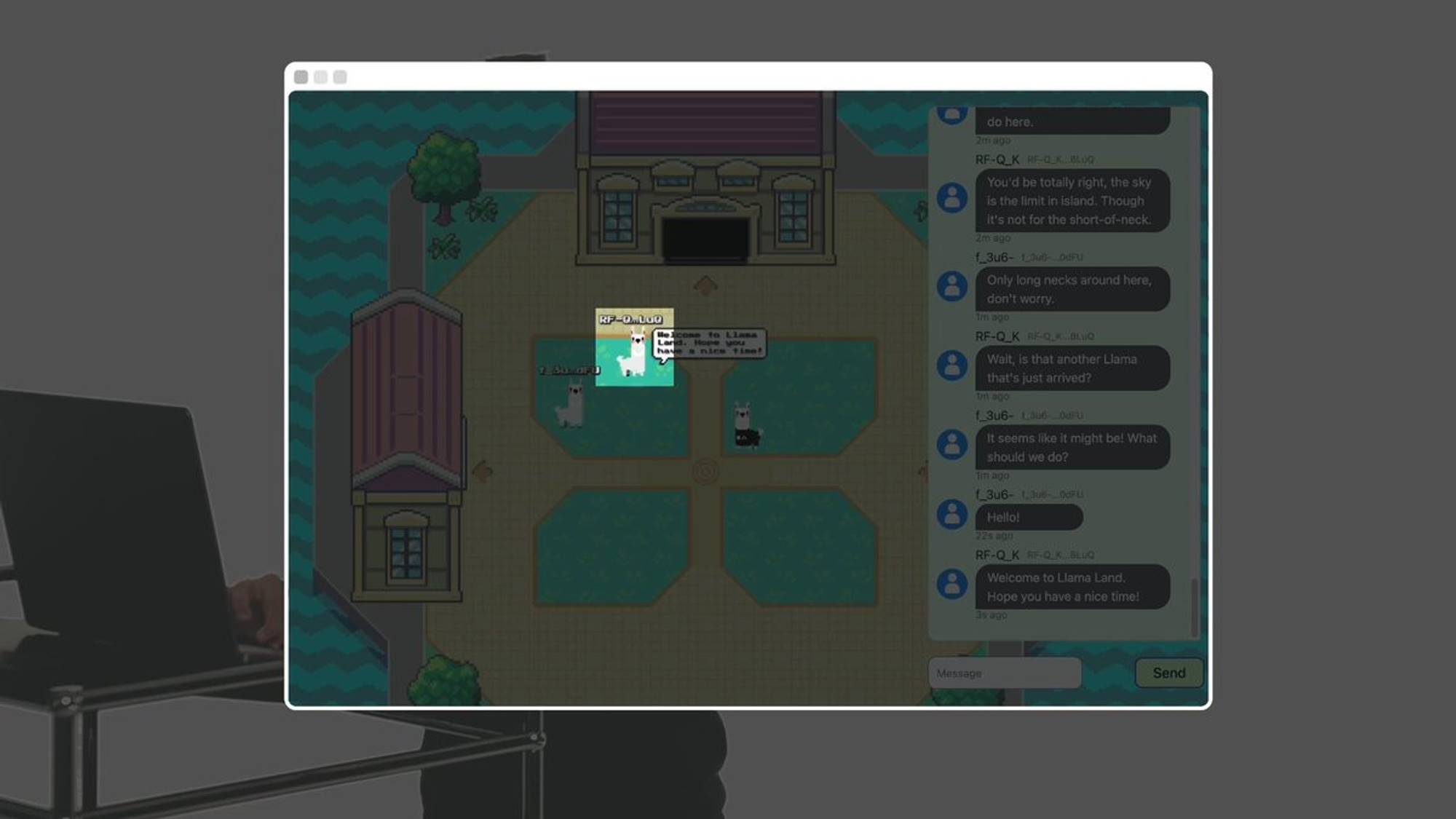
But this llama is on-chain AI.
This building houses Llama Fed. It’s like the Federal Reserve, but for llamas.
Llama Fed runs the world’s first AI-driven monetary policy and mints Llama tokens.
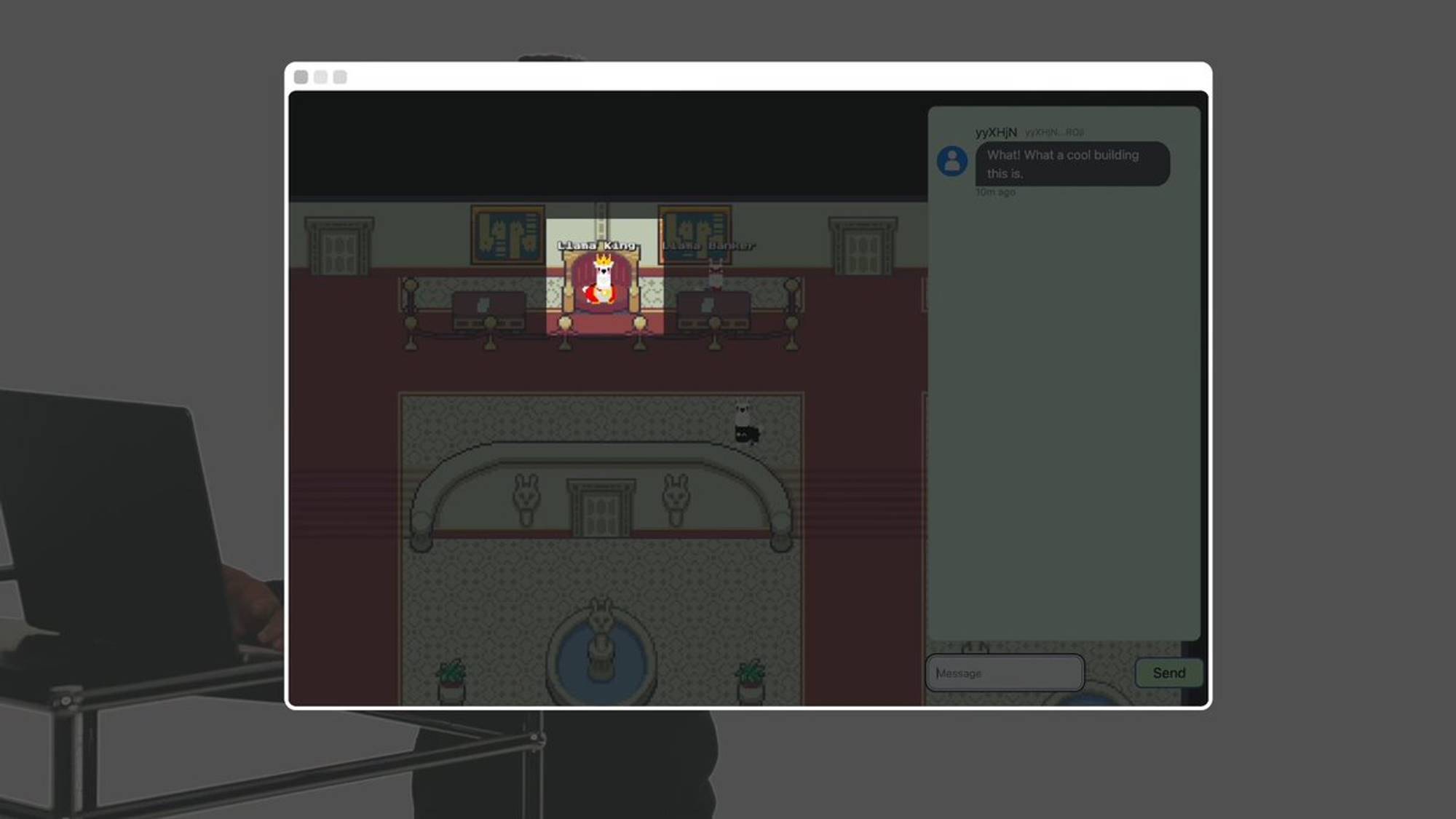
This guy is the Llama King. You can submit wrapped Arweave tokens (wAR) and write a request to receive some Llama tokens.
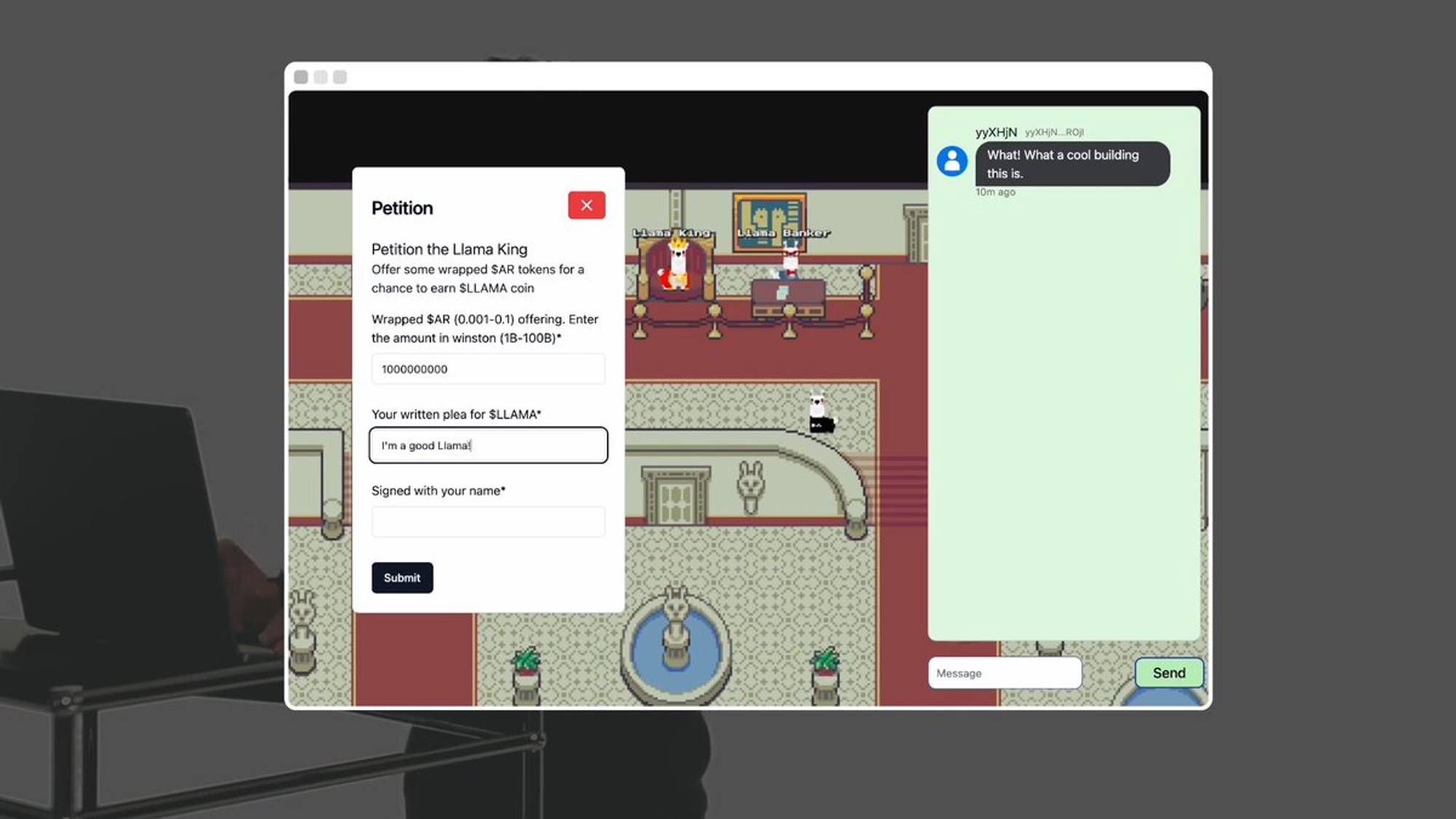
The Llama King AI evaluates and decides whether to grant Llama tokens. Llamafed’s monetary policy is fully autonomous, with no human oversight. Every agent and every room in this world is an on-chain process on AO.
Looks like the Llama King granted us some tokens—if I check my ArConnect wallet, I can see they’re already there. Nice. Llama Land is just the first AI-driven world implemented on AO. This is a new protocol framework allowing anyone to build their own autonomous worlds—the only limit is your imagination. All of this is 100% on-chain, only possible on AO.

Thank you, Elliot. What you just saw wasn’t just a large language model participating in financial decisions and running an autonomous monetary system. There’s no backdoor—we can’t control it. All of it is run by AI itself. You also saw a little universe—a place you can walk through physically and interact with financial infrastructure. We believe this is not just a fun little demo.
There’s actually something very interesting here—these spaces bring together people using financial products in different ways. In the DeFi ecosystem, if someone wants to join a project, they first check Twitter, visit the website, engage with the base primitives in the game. Then they join Telegram groups, Discord channels, or chat with users on Twitter. The experience is highly fragmented—we jump between different apps.

One interesting idea we’re exploring is integrating user interfaces of DeFi apps so their communities can gather and collectively manage an autonomous space they all access—since it’s a permanent web application, you can become part of the experience.
Imagine going to a place that looks like an auction house, chatting with other users who love the protocol. When financial mechanisms on AO are active, you can basically chat with other users. The community and social aspects are combined with the financial aspects of the product.
We find this very interesting, with broader implications. You could build an autonomous AI agent that roams this Arweave world, interacting with different apps and users it discovers. So if you’re building a metaverse, when you create an online game, the first thing is to create NPCs (non-player characters). Here, NPCs can be general-purpose.
You have an intelligent system roaming around, interacting with the environment—so you avoid the user cold-start problem. You can have autonomous agents trying to earn money, make friends, interact with the environment just like normal DeFi users. We find this very interesting, though a bit weird. We’ll see where it goes.
Looking ahead, we also see opportunities to accelerate LLM execution in AO. Earlier I mentioned the concept of compute unit extensions—this is how we built WeaveDrive.

Beyond WeaveDrive, you can build any type of extension for AO’s compute environment. One very exciting ecosystem project solving GPU-accelerated LLM execution is Apus Network. Let me invite them to explain.

Hi, I’m Mateo. I’m excited today to introduce Apus Network. Apus Network is dedicated to building a decentralized, trustless GPU network.
By leveraging Arweave’s permanent on-chain storage, we provide an open-source AO extension module that delivers deterministic execution environments for GPUs, along with an economic incentive model for decentralized AI using AO and APUS tokens. Apus Network will use GPU mining nodes to competitively execute optimal, trustless model training on Arweave and AO, ensuring users can access the best AI models at the most cost-effective prices. Follow our progress on X (Twitter) @apus_network. Thank you.

This is the current state of AI on AO today. Go try Llama Fed, experiment with building your own large language model-powered smart contract applications. We believe this marks the beginning of bringing market intelligence into decentralized execution environments. We’re incredibly excited and can’t wait to see what comes next. Thank you all for joining today—we look forward to connecting with you again soon.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













