

Optimal Optimization Level: Learning from Machine Learning to Maximize Objectives
TechFlow Selected TechFlow Selected
Optimal Optimization Level: Learning from Machine Learning to Maximize Objectives
Low efficiency is not good, but does high efficiency necessarily mean it's good?
By DAN SHIPPER
Translated by Ines
Midjourney prompt: "From the perspective of someone about to cross a bridge, imagine a rope-plank suspension bridge spanning a vast and dangerous chasm, watercolor painting."
How much should I optimize? This is a question I often ask myself, and I’m sure you’ve asked it too. If you’re optimizing toward a goal—like building a company that lasts generations, finding the perfect life partner, or designing the ideal workout plan—your instinct is to push as hard as possible toward perfection.
Optimization is the pursuit of perfection—we optimize because we don’t want to settle. But is relentlessly chasing perfection actually better? In other words, when does optimization go too far?
People have long tried to figure out how hard to optimize. You can place them along a spectrum.
On one end is John Mayer, who believes less is more. In his hit song “Gravity,” he sings:
"Oh, twice the good ain't twice as good / And can't sustain like half can do / Wanting more just bends me down to kneeling."
Dolly Parton takes the opposite view. Her famous quote: "Less is not more. More is more."
Aristotle disagrees with both. Over 2,000 years ago, he proposed the golden mean: when optimizing for a goal, what you need is a midpoint between too much and too little.
So which should we pick? It’s 2023. We’d like to be a bit more quantitative and less hand-wavy about this. Ideally, we could measure in some way how effective optimization toward a goal really is.
Nowadays, we can often turn to machines for help. Goal optimization is one of the key areas studied by machine learning and AI researchers. To get a neural network to do anything useful, you must give it a goal and work to improve its ability to achieve that goal. The answers computer scientists have found in neural networks can teach us a lot about optimization in general.
A recent article by machine learning researcher Jascha Sohl-Dickstein particularly excited me. He makes the following point:
Machine learning shows us that over-optimizing for a goal can go terribly wrong—and we can see this quantitatively. When machine learning algorithms over-optimize for a goal, they often lose sight of the bigger picture, leading to what researchers call "overfitting." In practice, when we hyper-focus on perfecting a particular process or task, we become overly adapted to that specific task and fail to handle change or new challenges effectively.
So when it comes to optimization—turns out, "more" doesn’t mean "more." Take that, Dolly Parton.
This article is my attempt to summarize Jascha’s piece and explain his ideas in plain language. To understand it, let’s look at how training machine learning models works.
Mindsera uses artificial intelligence to help you uncover hidden thinking patterns, reveal cognitive blind spots, and understand yourself better.
You can build your own thinking using journal templates based on useful frameworks and mental models to make better decisions, improve your health, and boost productivity.
Mindsera’s AI mentors emulate the thinking of intellectual giants like Marcus Aurelius and Socrates, offering new pathways to insight.
Smart analysis generates original insights from your writing, measures your emotional state, reflects your personality, and offers personalized recommendations to help you grow.
Build self-awareness, clarify your thoughts, and succeed in an increasingly uncertain world.
Get started.
Want to volunteer? Click here.
👉 https://www.passionfroot.me/every
Being too efficient makes everything worse
Imagine you want to create a machine learning model that excels at classifying dog images. You want to input a photo of a dog and get back the correct breed. But you don’t just want an average dog image classifier—you want an unparalleled machine learning classifier, no cost spared, endless coding, powered by countless coffees. (After all, we’re optimizing.)
So how do you achieve this vision? While there are many strategies, you’ll likely choose supervised learning. Supervised learning is like giving your machine learning model a tutor: it repeatedly asks the model questions and corrects it when it’s wrong, helping the model gradually learn the right answers. Through this process, the model steadily improves its accuracy.
First, you need to prepare a dataset of images to train your model. You pre-label these images with tags like “Poodle,” “Cockapoo,” “Dandie Dinmont Terrier,” etc. Then, you feed these images and their corresponding labels into the model to begin its learning journey.
The model learns through a trial-and-error process. You show it an image, and it tries to guess the label. If it’s wrong, you fine-tune the model so it performs better next time. With persistence, over time, you’ll find the model gets increasingly accurate at predicting labels for images in the training set.
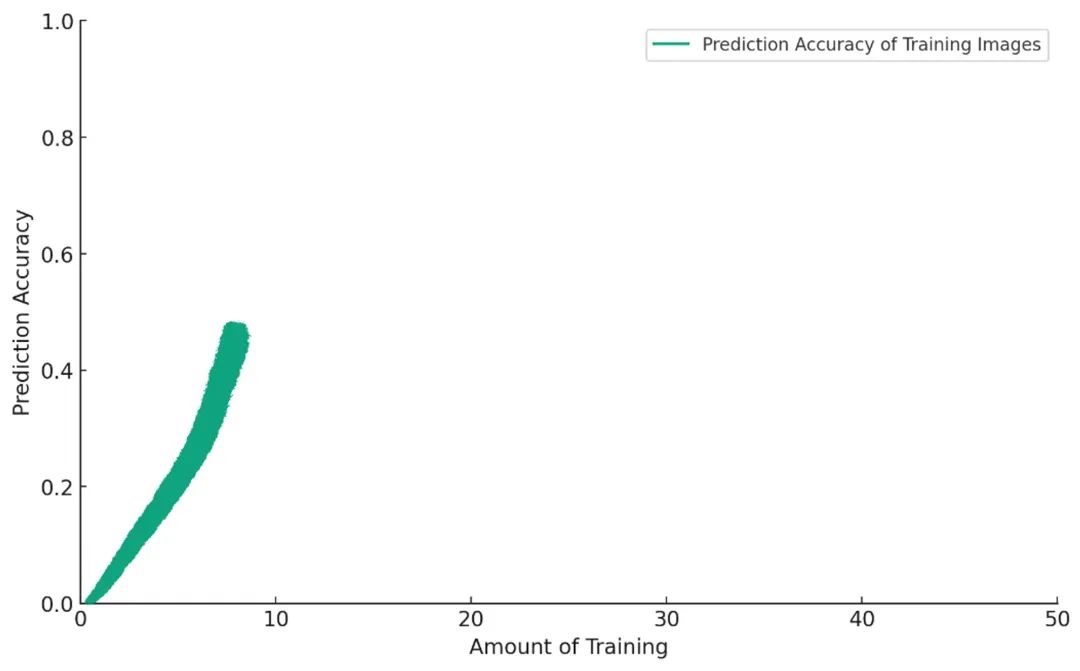
Now, the model is getting better and better at labeling images from the training set. So you give it a new task: label dog photos it has never seen during training.
This is a critical test: if you only ask about images it’s already seen, it’s like letting it cheat on a test. So you bring in new dog photos you’re confident the model hasn’t encountered before.
At first, everything goes smoothly. The more you train, the better it performs:
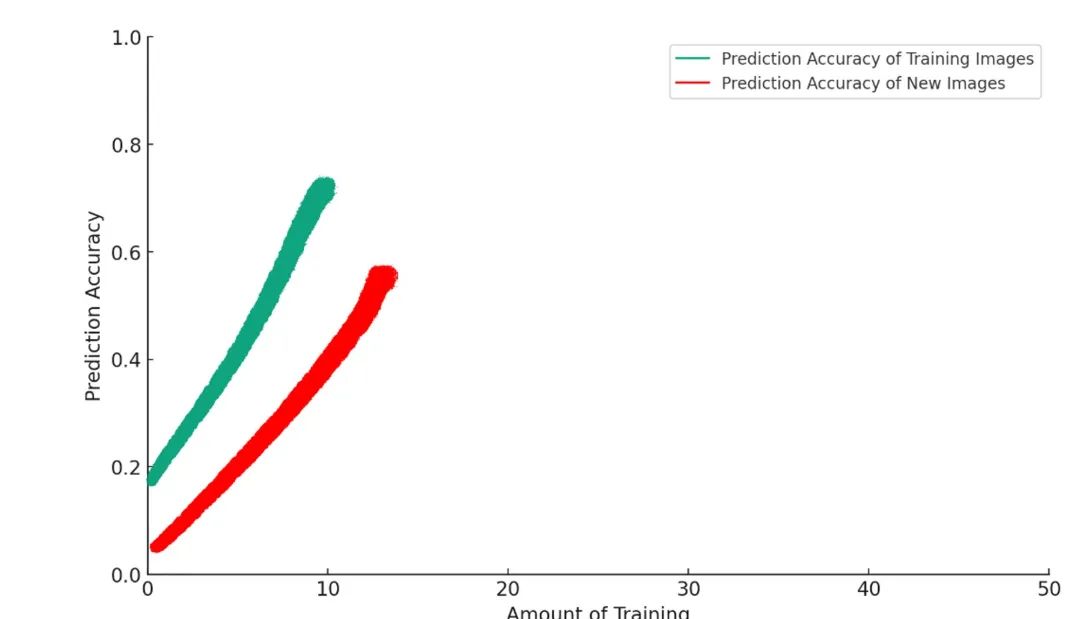
But if you keep training, the model starts doing something akin to an AI version of “pooping on the carpet.” What’s going on?
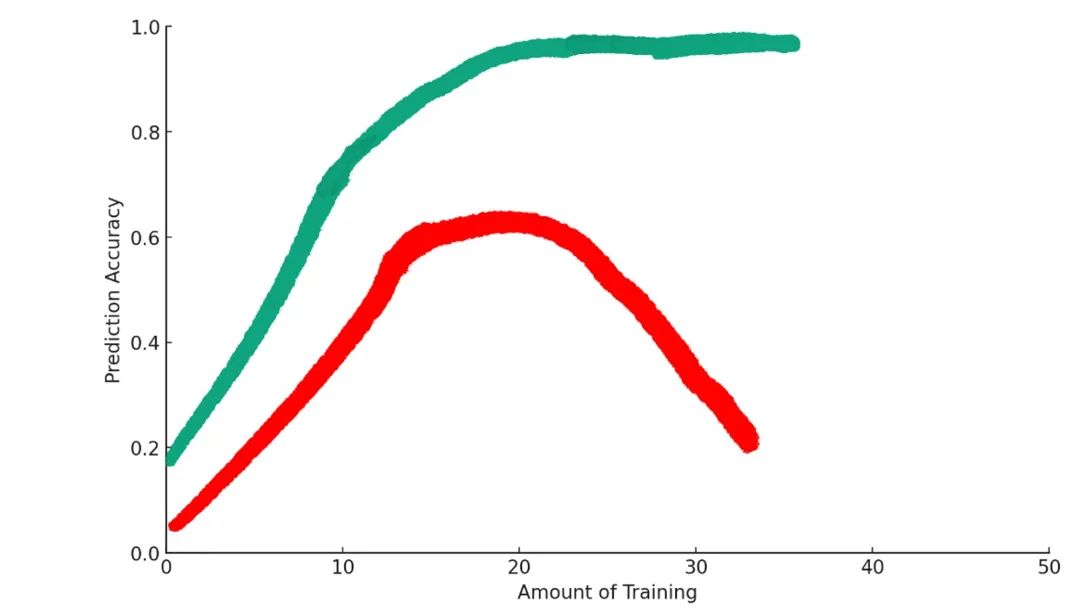
What’s happening here?
Some training helps the model better achieve its goal. But beyond a certain point, additional training actually makes things worse. This phenomenon is known in machine learning as “overfitting.”
Why overfitting makes things worse
In model training, we’re performing a subtle operation.
We want the model to be good at labeling any dog photo—that’s our true goal. But we can’t directly optimize for that, because we can’t possibly collect every possible dog photo. Instead, we optimize for a proxy goal: a small subset of dog photos that we hope represents the real goal.
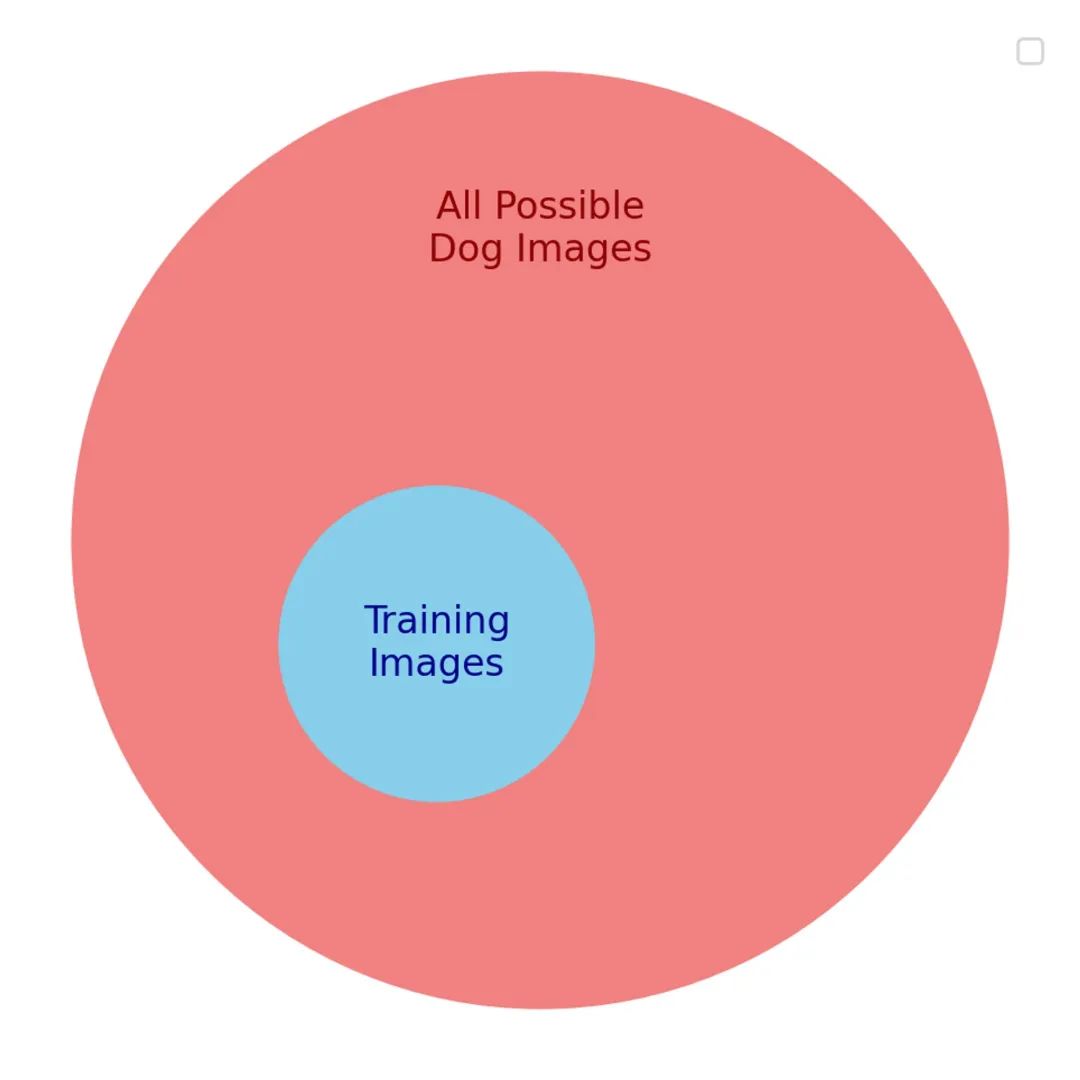
There are many similarities between the proxy and the true goal. So initially, the model improves on both. But as training progresses, the useful similarities between the two goals start to fade. Soon, the model becomes good only at recognizing content from the training set and performs poorly on anything else.
As training continues, the model starts relying too heavily on the details of the dataset used to train it. For example, maybe the training data contains an overabundance of yellow Labradoodles. When overtrained, the model might incorrectly learn that all yellow dogs are Labradoodles.
When the model encounters new images that differ from the characteristics of the training data, such an overfitted model performs poorly.
Overfitting reveals an important insight in our exploration of goal optimization.
First, when trying to optimize anything, you rarely optimize the thing itself—you optimize a substitute. In the dog classification problem, we can’t train on all possible dog photos. Instead, we try to optimize performance on a subset, hoping it generalizes well. It does—until we over-optimize.
This leads to a second insight: when you over-optimize a proxy function, you actually drift away from your original goal.
Once you understand this mechanism in machine learning, you start seeing it everywhere.
Applying overfitting to the real world
Take school, for example:
In school, we want to optimize for deep subject-matter knowledge. But measuring how deeply someone understands a topic is hard, so we use standardized tests. Standardized tests are a decent proxy for subject mastery.
But when students and schools put too much pressure on test scores, the drive to optimize scores begins to undermine real learning. Students become overly adapted to the process of raising test scores. They learn how to take (or game) tests to boost their scores, rather than truly mastering the material.
Overfitting exists in business too. In the book Fooled by Randomness, Nassim Taleb writes about Carlos, a sharply dressed banker who traded emerging market bonds. His strategy was buying low: when Mexico devalued its currency in 1995, Carlos bought low and profited when bond prices rose after the crisis passed.
This buy-low strategy netted his firm $80 million. But Carlos became “over-adapted” to the markets he had experienced, and his pursuit of optimized returns ultimately led to his downfall.
In the summer of 1998, he bought Russian bonds at a low. As the summer wore on, prices kept falling—and Carlos kept buying. He doubled down repeatedly until the bonds were extremely cheap, eventually losing $300 million—three times what he’d earned in his entire career up to that point.
As Taleb notes in his book: “In the market, the most successful traders may simply be those best adapted to the most recent cycle.”
In other words, over-optimizing returns means over-adapting to the current market cycle. Your performance will rise sharply in the short term. But the current market cycle is just a proxy for overall market behavior—when the cycle shifts, your previously successful strategy may suddenly bankrupt you.
The same insight applies to my business. Every runs a subscription media business, and I want to increase MRR (monthly recurring revenue). To achieve this, I could incentivize authors to generate more pageviews, increasing traffic to our articles.
That would probably work! Increased traffic does lead to more paying subscribers—up to a point. Beyond that, I suspect authors would start using clickbait or salacious content to boost pageviews, content that doesn’t attract engaged, paying readers. Ultimately, if I turn Every into a clickbait factory, our paying subscribers might decline instead of grow.
If you keep observing your life or your business, you’ll surely spot the same pattern. The question is: what should we do about it?
So what should we do?
Machine learning researchers use many techniques to prevent overfitting. Jascha’s article outlines three key approaches we can adopt: early stopping, introducing random noise, and regularization.
Early Stopping
This means constantly monitoring the model’s performance on its true goal and pausing training when performance begins to decline.
In Carlos’s case, as a trader who lost all his capital buying sinking bonds, this might mean implementing a strict loss-control mechanism that forces him to exit trades once cumulative losses reach a certain threshold.
Introducing Random Noise
Adding noise to a machine learning model’s inputs or parameters makes overfitting harder. The same principle applies to other systems.
For students and schools, this could mean administering standardized tests at random times, making last-minute cramming more difficult.
Regularization
In machine learning, regularization penalizes models to prevent them from becoming too complex. The more complex a model, the more prone it is to overfitting data. The technical details aren’t crucial, but the same concept can be applied outside machine learning by adding friction within a system.
If I want to incentivize all Every authors to boost pageviews and thus increase our monthly recurring revenue, I could modify the reward structure so that any pageviews beyond a certain threshold count less and less.
These are potential solutions to overfitting, which brings us back to our original question: what is the optimal level of optimization?
The Optimal Level of Optimization
The main lesson we’ve learned is that you almost never optimize directly for a goal—instead, you usually optimize for something that looks like your goal but is slightly different. It’s a proxy.
Because you must optimize for a proxy, when you optimize too much, you become overly skilled at maximizing that proxy—often at the expense of the real goal.
So here’s the key takeaway: know what you’re optimizing for. Understand that the proxy is not the goal itself. Stay flexible in your optimization efforts, and be ready to stop or switch strategies when the useful similarity between your proxy and the actual goal has run its course.
As for the wisdom of John Mayer, Dolly Parton, and Aristotle on optimization, I think the award must go to Aristotle and his golden mean.
When optimizing for a goal, the optimal level lies between too much and too little. It’s “just right.”
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News










