

谷歌官方“GEO 指南”:GEO 不存在,這是真話也是話術
TechFlow Selected深潮精選
谷歌官方“GEO 指南”:GEO 不存在,這是真話也是話術
理解谷歌的動機,比記住谷歌說的話更重要。
作者:深潮 TechFlow
5 月 15 日,谷歌悄悄發佈了一份名為《Optimizing your website for generative AI features on Google Search》的官方指南。這是谷歌第一次正式回應過去一年喧囂甚囂塵上的 GEO(生成式引擎優化)話題。
如果你只看英文 SEO 圈的快訊,你會得到一個簡單的結論:“谷歌官方說 GEO 不存在,那就是 SEO。”
這個結論既對,也不對。
對的部分是,谷歌確實在這份文檔裡幾乎否定了過去一年所有關於 GEO 的"奇技淫巧":llms.txt、內容分塊(chunking)、為 AI 重寫文案、刷"mentions"……谷歌的態度只有兩個字:沒用。
不對的部分是,谷歌只能代表谷歌自己。這份指南里有一個關鍵事實從頭到尾都沒被點破:AI 搜索的市場不只屬於谷歌。Perplexity、ChatGPT、Claude、Gemini API、各家垂直 AI 助手,它們各自有不同的檢索系統、不同的引用邏輯、不同的內容偏好。把谷歌的立場當成整個 AI 搜索市場的立場,是這份指南最危險的誤讀。
谷歌說了什麼?
谷歌這份文檔的核心邏輯鏈非常清晰,只有三步。
第一步:AI 搜索的底層就是 SEO。
谷歌明確說,AI Overviews 和 AI Mode 的工作原理基於兩項技術,RAG(檢索增強生成,也叫 grounding)和 query fan-out(查詢擴散)。前者負責從谷歌的搜索索引裡撈出相關網頁作為 AI 回答的依據,後者負責把一個用戶查詢拆解成多個相關查詢並行檢索。
關鍵點在於:RAG 的"R"(檢索)依賴的就是谷歌現有的搜索排名系統。一個頁面要在 AI Overview 裡被引用,先決條件是它在傳統谷歌搜索裡能排上來。AI 不是另起爐灶,是在 SEO 索引基礎上加了一層生成。
第二步:既然底層是 SEO,那 SEO 最佳實踐就是 GEO 最佳實踐。
谷歌反覆強調:寫有獨立視角、第一手經驗、專家洞察的"non-commodity content"(非大路貨內容);保持清晰的技術結構(可爬取、可索引、頁面體驗良好);該用結構化數據用結構化數據。這些是 SEO 圈講了二十年的事,谷歌的意思是,繼續做這些,就夠了。
第三步:點名否定一系列 GEO 流行做法。
這部分是整份指南最有信息量的內容。谷歌罕見地直接列出"你不需要做什麼":
- 不需要 llms.txt 或任何專門給 AI 看的文件,谷歌不會特殊處理它們;
- 不需要把內容切成小塊(chunking),谷歌系統能理解整頁 nuance;
- 不需要為 AI 重寫文案,AI 能理解同義詞和語義;
- 不需要追求不真誠的"mentions",刷量會被反垃圾系統打擊;
- 不需要過度堆 structured data,它不是 AI 搜索的必要條件。
文檔結尾還埋了一個新概念:agentic experiences(智能體體驗)。谷歌提到,未來 AI agent 會通過 DOM 結構、可訪問性樹、頁面截圖來訪問網站,這暗示了下一波"優化"的方向,但谷歌沒有展開。
以上是谷歌官方立場的全部。
谷歌為什麼這麼說?
大多數中文 SEO 圈的搬運稿到上一節就結束了。但理解谷歌的動機,比記住谷歌說的話更重要。
谷歌為什麼在這個時間點、用這種語氣發佈這份指南?
動機一:壓制"GEO 是獨立學科"的市場敘事。
過去一年,“GEO/AEO 服務”在英文市場已經形成了一個小的灰色產業帶:諮詢公司賣 GEO 審計、SaaS 工具賣"AI 可見度監測"、營銷代理賣"AI 引用優化套餐"。這些服務的潛臺詞是,SEO 已經過時,你需要新的方法論、新的乙方、新的預算。
這個敘事如果坐大,對谷歌是雙重威脅:一是動搖了 SEO 生態的穩定性(谷歌從中收割搜索廣告和工具生態),二是把 AI 搜索描述成一個獨立於谷歌的市場(從而讓 Perplexity、ChatGPT 這類對手顯得更具威脅)。所以谷歌必須出來說:這是同一件事,別折騰,回到 SEO 框架來。
動機二:防止網站為 AI 做"過度優化",汙染索引質量。
如果整個互聯網都開始按 llms.txt 標準生產內容、按 chunking 邏輯切分段落、按"AI 可讀性"重寫文案,谷歌索引的質量會下降,因為這些內容是為機器優化的,對人類讀者反而變難讀。谷歌過去十年一直在打擊"為搜索引擎而寫"的內容,現在不可能允許"為 AI 而寫"的內容反過來汙染索引。
動機三:保護自己的話語權。
谷歌不希望"GEO 圈"成為一個谷歌之外的人定義規則的領域。所以這份文檔的真正信息是:關於谷歌 AI 搜索怎麼優化,只有谷歌說了算,其他人的說法都不可信。
理解了這三個動機,你就能理解為什麼這份文檔同時表現得"開誠佈公"又"語帶保留"。
哪些是真話:谷歌說對的部分?
谷歌的立場不是全錯,事實上,針對谷歌自己的 AI 搜索功能,這份指南的判斷基本都站得住腳。
真話一:在谷歌 AI Overview 裡被引用,確實是 SEO 問題。
谷歌 AI Overview 的檢索層就是谷歌的搜索排名系統。這意味著傳統 SEO 做得好的網站,在 AI Overview 裡被引用的概率天然就高。沒有什麼"針對谷歌 AI 的特殊優化",因為底層就是同一套系統。
真話二:llms.txt 是無效信號。
這點需要展開說,因為中文圈很多 GEO 服務把"幫你部署 llms.txt"當賣點。llms.txt 是一個民間發起的提案,本質上是讓網站告訴 AI 爬蟲"我這裡有什麼內容、怎麼讀"。但沒有任何一家主流 AI 公司公開承諾會讀取 llms.txt,OpenAI 沒說、Anthropic 沒說、谷歌現在也明確說不會。這是一個一廂情願的標準,目前它的最大用途是給 SEO 乙方多一個收費項目。
真話三:刷"mentions"是低效的。
過去半年有一些公司在賣“AI 引用提升”服務,本質是僱水軍在 Reddit、Quora、博客評論區批量植入品牌名,賭 AI 訓練或檢索時會帶上。谷歌指出這種做法不僅沒用,還會被反垃圾系統打擊,這點是真話。AI 模型對來源質量的判斷越來越精細,低質量提及的權重在快速下降。
真話四:內容質量永遠是基礎。
谷歌強調的"non-commodity content",有獨立視角、第一手經驗、專家判斷,這是所有 AI 搜索引擎共同偏好的內容。無論是谷歌 AI Overview、Perplexity 還是 ChatGPT,都傾向於引用有明確觀點和獨家信息的來源,而不是 AI 生成的二手綜述。
哪些是話術:谷歌沒說或迴避的部分?
但如果你只看到上面這些"真話",就完整地落入了谷歌的敘事陷阱。
話術一:谷歌只能代表谷歌自己。
這是整份文檔最關鍵的盲區。谷歌反覆說"AI 搜索 = SEO",但這個等號只在谷歌的 AI Overview 和 AI Mode 裡成立。
讓我們看一下真實的 AI 搜索市場:
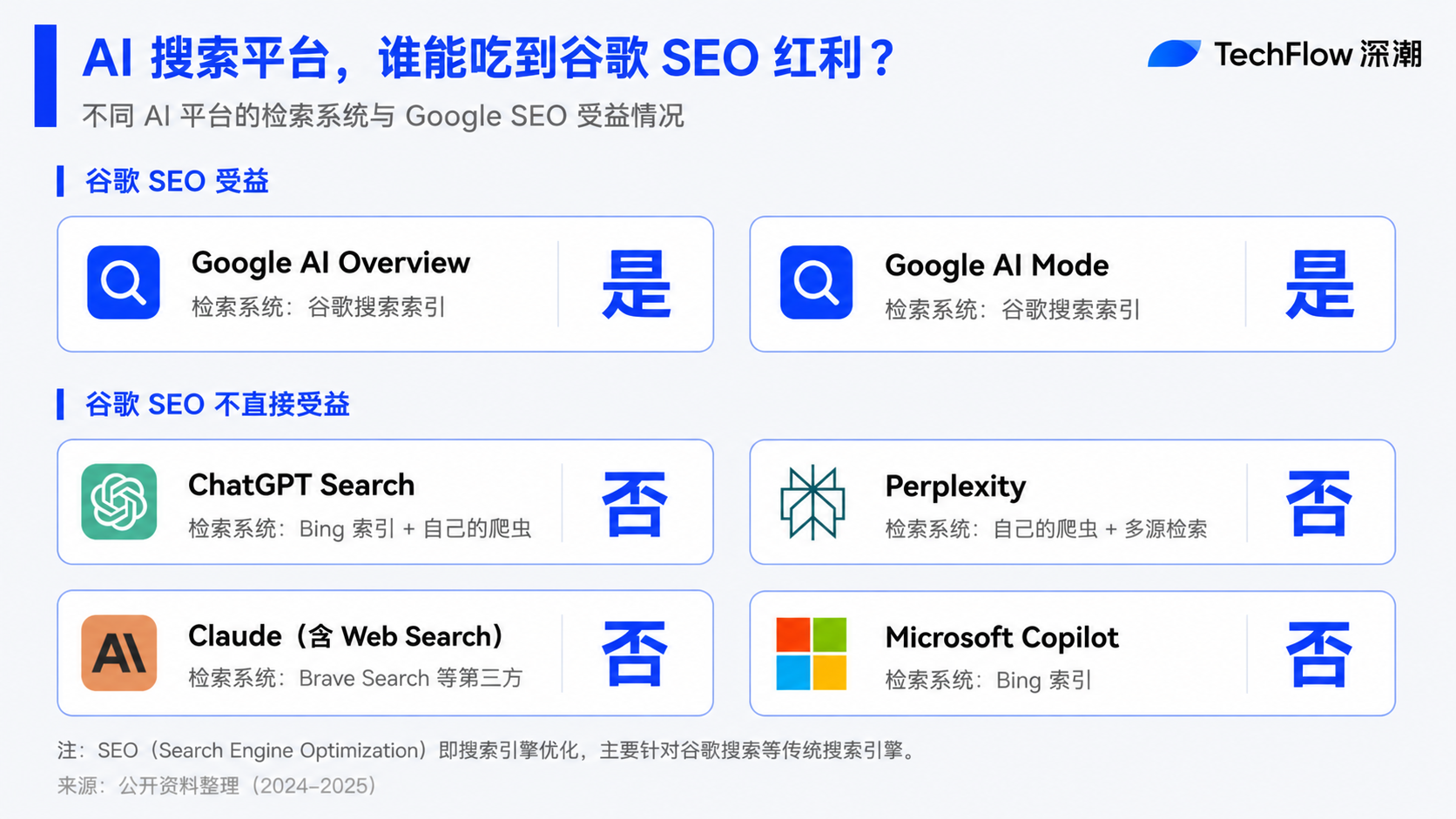
ChatGPT、Perplexity、Claude,這三個產品加起來覆蓋了相當一部分高價值用戶(投資人、研究員、決策者),它們的檢索系統完全獨立於谷歌 SEO 體系。在這些平臺上的可見度優化,谷歌的指南一個字都沒講到。
這是 GEO 作為獨立服務真正能站住腳的地方。
話術二:"non-commodity content"的標準沒那麼客觀。
谷歌說"創造獨特、有價值的內容",誰會反對呢?但什麼內容算"non-commodity",是由模型決定的,而模型是有偏見的。
舉一個加密行業的例子。Coindesk、The Block 這種英文老牌媒體,在 AI Overview 裡的引用頻率顯著高於同質量的新興媒體。原因不是它們的內容更"獨特",而是它們在谷歌搜索權重的歷史積累更深。AI 檢索時,"高權威站點"的內容會被優先考慮,這是一個先有雞還是先有蛋的問題。新進入者即使內容質量更高,也很難快速被引用。
谷歌不會告訴你這點,因為這暴露了 AI Overview 在算法上傾向於強化既有的搜索頭部效應。
話術三:Agentic experiences 才是下一個變量,但谷歌輕描淡寫帶過。
文檔末尾提到 AI agent 會通過 DOM 和可訪問性樹訪問網站,這是這份指南里最有信息量但最被低估的一段。
為什麼?因為 AI agent 的興起會顛覆"搜索"本身的形態。當用戶不再親自搜索、而是讓 agent 替自己完成任務(比如讓 agent 幫你研究某個加密項目、對比交易所費率、監控市場異動),網站需要被設計成"對 agent 友好",而不是"對人類 SEO 友好"。
這塊谷歌只用了一段話帶過,但實際是接下來 12-24 個月內最重要的變化方向。谷歌不願展開,是因為它自己在這個方向上的產品佈局也還在早期,不想給市場過早預期。
話術四:"什麼都不需要做"本身就是一個立場。
通讀全文你會發現,谷歌的核心建議其實只有兩條:寫好內容、做好 SEO 基礎。這聽起來像是在幫內容創作者,但其實是在保護谷歌自己的索引中心地位。
如果谷歌承認“AI 搜索需要新的優化方法”,等於承認 SEO 時代結束了。所以谷歌的策略是:把 AI 搜索的優化全部塞回 SEO 框架,讓網站主繼續按谷歌的規則玩。這是合理的商業策略,但讀者要清楚這是一個有立場的官方文件,而不是中立的行業指南。
對中文加密行業意味著什麼?
回到中文加密行業的具體場景。這份指南的落地判斷有幾點:
第一,過去一年中文圈的 "GEO 項目方需求"是真實的,但服務的方法論需要重構。
很多加密項目方都問過同一個問題:"為什麼用戶搜我們項目名,ChatGPT 給出的描述是錯的/舊的/帶負面情緒的?"這是一個真實痛點,尤其對那些處於早期、信息源頭被 KOL 推特和小型博客主導的項目。
但解決這個問題的正確方法不是部署 llms.txt、不是給網站做 chunking、不是刷 Reddit 提及。正確方法是:
- 在主流加密媒體(給自己打個廣告,比如深潮 TechFlow)發佈結構化的事實型內容(團隊背景、技術架構、融資歷史、產品里程碑),讓 AI 檢索時能找到清晰、一致、可核驗的信息
- 主動監控 ChatGPT、Perplexity、Claude 等多個 AI 平臺對項目的描述,發現錯誤信息及時通過新內容覆蓋
- 優化項目官網的事實性內容(不只是 marketing 文案),尤其是 FAQ、文檔、博客這些 AI 喜歡引用的結構
第二,谷歌的 AI Overview 在中文加密語境下重要性偏低。
這是一個需要承認的現實:中文加密用戶的信息消費習慣,谷歌搜索的佔比遠低於英文市場。微信公眾號、Twitter/X、Telegram、幣安廣場、深潮這類垂直媒體,這些渠道的影響力總和遠超谷歌搜索。
所以對中文加密項目方來說,Perplexity 和 ChatGPT 的可見度,比谷歌 AI Overview 重要得多。前者是越來越多 Web3 創始人、VC、研究員在用的工具;後者在中文加密語境下還是次要觸點。
谷歌這份指南對中文加密行業的直接指導意義,其實有限。
第三,多語言、多平臺分發的價值在被強化。
谷歌強調“AI 優先引用高質量、有獨立視角的內容”。這些內容必須以 AI 可訪問的形式存在於多個平臺,不只是中文站,還要有英文版本、要被多個 AI 平臺爬蟲看到。多語言分發不只是品牌擴張工具,更是 AI 時代的內容資產保值工具。
寫在最後
谷歌這份指南最有價值的部分,反而不是它說的那些"該做什麼"或"不該做什麼"。
它最有價值的部分是讓市場看清了一件事:AI 搜索時代的"優化",正在分化為兩個截然不同的層面。
一層是谷歌定義的"AI 搜索 = SEO",這一層的規則相對穩定,做內容質量、做技術基礎就行。
另一層是谷歌沒說、也不願意說的"非谷歌 AI 平臺優化",Perplexity、ChatGPT、Claude 各家的檢索邏輯不同、引用偏好不同、內容標準不同。這一層目前沒有官方指南、沒有統一標準,是真正的早期階段。
對項目方來說,認清這兩層的區別,比記住任何一條具體建議都重要。
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News











