

Bittensor 是 Crypto 全村的希望
TechFlow Selected深潮精選
Bittensor 是 Crypto 全村的希望
在"Crypto 是否還有存在意義"這場總辯論裡,Bittensor 正在給出全行業最有力的一份答案。
作者:0xai
特此感謝@DistStateAndMe 及其團隊在開源 AI 模型領域的貢獻,以及對本文提供的寶貴建議與支持。
為什麼你應該關注這篇報告
如果"去中心化 AI 訓練"已經從不可能變成了可能,Bittensor 被低估了多少?
2026 年初,整個 Crypto 圈子瀰漫著一種疲憊感。
上一輪牛市的餘溫早已散去,人才在加速流向 AI 行業。那些曾經談論"下一個 100x"的人,現在聊的是 Claude CodeOpenclaw。"crypto 是在浪費時間"——這句話,你可能不止聽過一次。
但在 2026 年 3 月 10 日,一個叫 Templar 的 Bittensor 子網悄悄宣佈了一件事。
70 多個來自全球各地的獨立參與者,沒有中央服務器,沒有大公司協調,僅憑 Crypto 激勵機制,合力訓練出了一個 720 億參數的 AI 大模型。
模型和相關論文已經發布在 HuggingFace 和 arXiv 上,數據是公開可驗證的。
更關鍵的是:在多項關鍵測試中,這個模型的表現超過了 Meta 花重金訓練的同等級別模型。
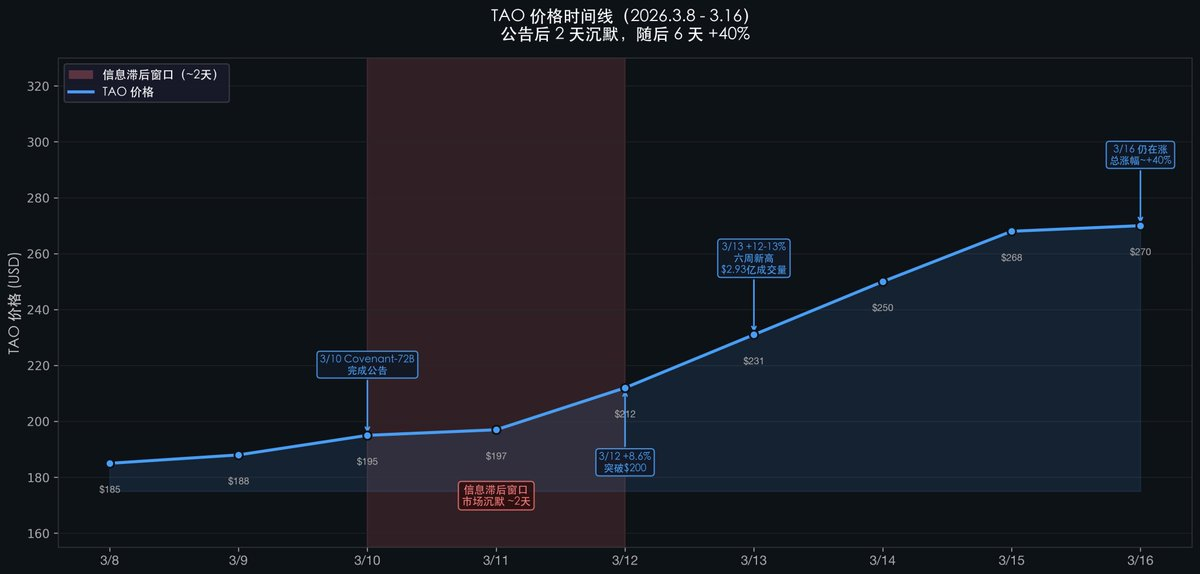
公告發出後,TAO 的價格沉默了將近 2 天。直到第 3 天才開始暴漲,6 天后仍未停止,總漲幅約 +40%。為什麼會有這 2 天的延遲?
這篇報告的核心論點是:加密投資者看到的是"又一個開源模型",覺得比不上日常使用的 GPT、Claude;AI 研究者不關注 crypto。兩個圈子之間的鴻溝,正在製造一個認知套利窗口。
閱讀框架
這篇報告分為兩個邏輯部分:
Part I — 技術突破:解釋 SN3 Templar 到底做成了什麼,以及為什麼這件事在 AI 和 Crypto 歷史上具有重要意義。
Part II — 行業意義:解釋為什麼這件事意味著 Bittensor 生態被系統性低估,為什麼說 Bittensor 是 Crypto 全村的希望。
Part I:去中心化 AI 訓練的突破
1. SN3 是做什麼的?
訓練一個大語言模型需要什麼?
傳統答案:建一個巨型數據中心,買上萬塊頂級 GPU,花上億美元,由一家公司的工程師團隊統一協調。這就是 Meta、Google、OpenAI 的玩法。
SN3 Templar 的做法:讓分散在全球各地的人,各自拿出一臺或幾臺 GPU 服務器,像拼圖一樣把算力拼在一起,合力訓練一個完整的大模型。
但這裡有個根本難題:如果參與者來自全球各地、互不信任、網絡延遲不穩定,怎麼保證訓練結果是有效的?怎麼防止有人偷懶或作弊?怎麼激勵大家持續貢獻?
Bittensor 給出了答案:用 TAO 代幣作為激勵。誰的梯度(可以理解為"對模型改進的貢獻")越有效,誰就獲得越多 TAO。系統自動評分、自動結算,不需要任何中心化機構來協調。
這就是 Bittensor 的 SN3(第 3 號子網),代號 Templar。
如果 Bitcoin 證明了去中心化的"錢"是可能的,SN3 正在證明去中心化的"AI 訓練"也是可能的。
2. SN3 取得了什麼成果?
2026 年 3 月 10 日,SN3 Templar 宣佈完成了名為 Covenant-72B 的 大語言模型訓練。
"72B"是什麼意思?:720 億個參數。參數是 AI 模型的"知識存儲單元",數量越多,模型通常越聰明。GPT-3 是 1750 億,LLaMA-2(Meta 的開源旗艦)是 700 億。Covenant-72B 與 LLaMA-2 是同一數量級。
訓練規模有多大? :約 1.1 萬億個詞(tokens)≈ 550 萬本書(按每本書 20 萬字算)。
誰參與了訓練?:70+ 個獨立參與者(miner)先後貢獻算力(每輪同步上限約 20 個節點),訓練從 2025 年 9 月 12 日啟動,歷時約 6 個月。沒有中央服務器,沒有統一的機構來協調。
模型表現如何?: 用主流 AI 考試來類比:
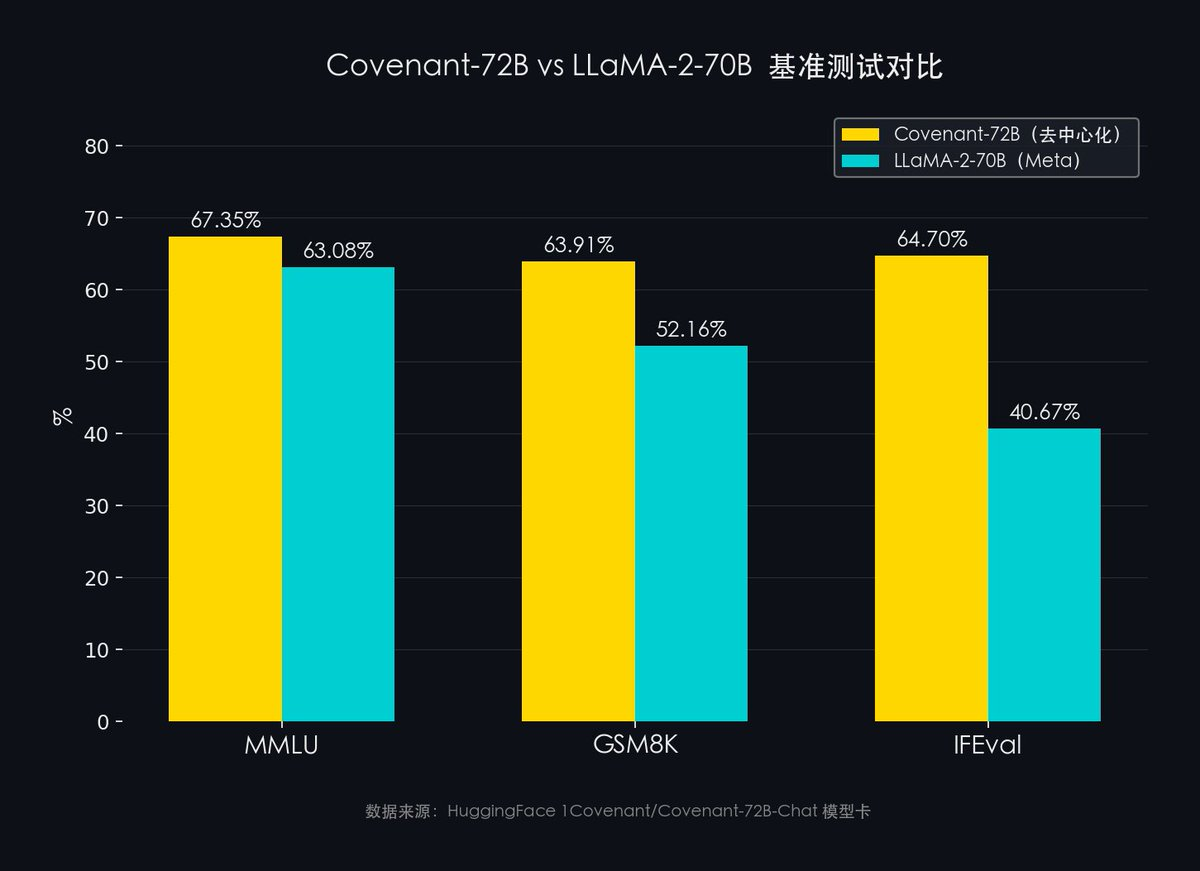
數據來源:HuggingFace 1Covenant/Covenant-72B-Chat 模型卡
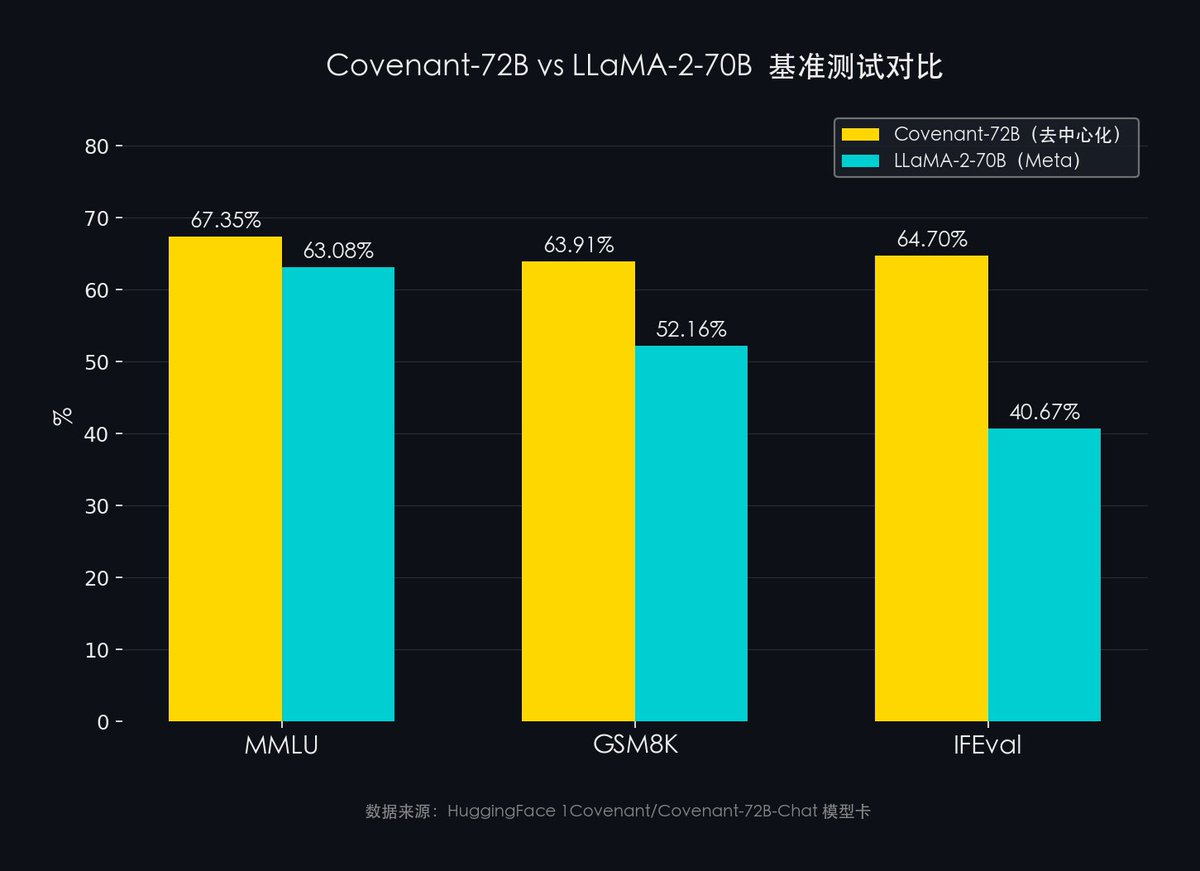
- MMLU(57 個學科綜合知識):Covenant-72B 67.35% vs Meta LLaMA-2 63.08%
- GSM8K(數學推理):Covenant-72B 63.91% vs Meta LLaMA-2 52.16%
- IFEval(指令跟隨能力):Covenant-72B 64.70% vs Meta LLaMA-2 40.67%
完全開源:Apache 2.0 許可證。任何人免費下載、使用、商用,沒有限制。
有學術背書:論文已提交 [arXiv 2603.08163],核心技術(SparseLoCo 優化器和 Gauntlet 反作弊機制)在 NeurIPS Optimization Workshop 發表。
3. 這個成果意味著什麼?
對開源 AI 社區:過去,因為資金和算力門檻,訓練 70B 級別的大模型是少數大公司的專利。Covenant-72B 第一次證明:社區,在沒有任何中心化資金支持的情況下,也能訓練同等規模的模型。這改變了誰有資格參與 AI 基礎模型開發的邊界。
對 AI 權力結構:現在的 AI 基礎模型格局是高度集中的——OpenAI、Google、Meta、Anthropic 幾家公司掌控著最強的基礎模型。去中心化訓練的成立,意味著這條護城河未必不可逾越。"只有大公司才能做基礎模型"這個前提,第一次被動搖了。
對 Crypto 行業:這是 crypto 項目第一次在 AI 領域產出真實的技術貢獻,而不只是"蹭熱點"。Covenant-72B 有 HuggingFace 模型、arXiv 論文、公開 Benchmark 數據。這建立了一個先例:Crypto 激勵機制可以成為嚴肅 AI 研究的基礎設施。
對 Bittensor 本身:SN3 的成功把 Bittensor 從一個"理論上可行的去中心化 AI 協議"變成了"已被實踐驗證的去中心化 AI 基礎設施"。這是從 0 到 1 的質變。
4. SN3 的歷史地位
去中心化 AI 訓練這條路,不是 SN3 第一個走的。但 SN3 走到了前人沒有走到的地方。
去中心化訓練進化史:
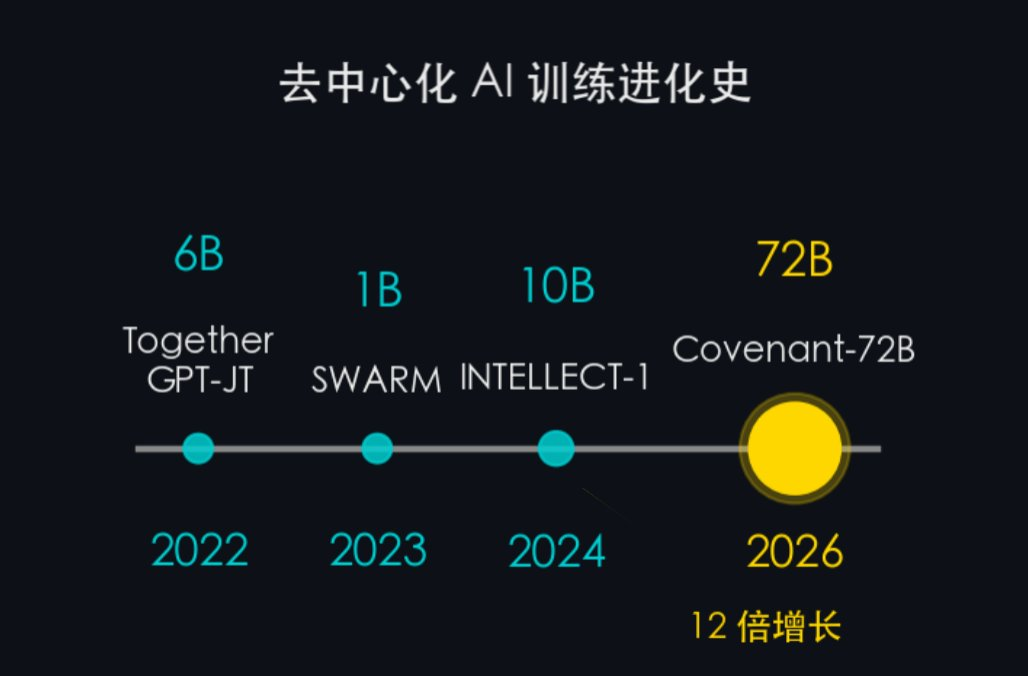
- 2022 — Together GPT-JT(6B):早期探索,證明多機協同可行
- 2023 — SWARM Intelligence(~1B):提出異構節點協同訓練框架
- 2024 — INTELLECT-1(10B):跨機構去中心化訓練
- 2026 — Covenant-72B / SN3(72B):首個在主流 Benchmark 上超越集中式訓練的 72B 大模型
4 年時間,從 6B 跳到 72B,參數量增長了 12 倍。但更重要的不是參數量,而是質量——前幾代項目主要是"能跑起來",Covenant-72B 是第一個在主流 Benchmark 上超越集中式訓練模型的去中心化大模型。
關鍵技術突破:
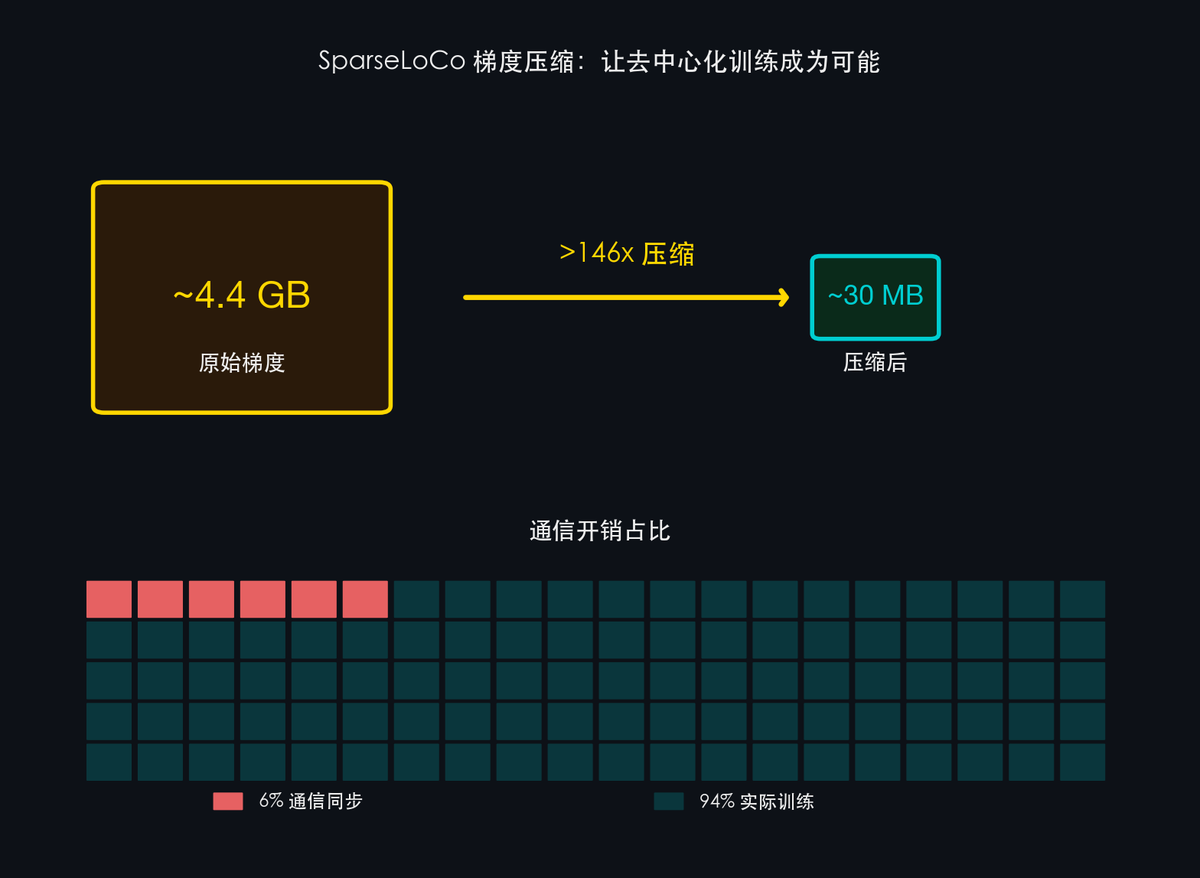
- >99% 壓縮率(>146x):每次參與者上傳訓練結果(梯度)時,原本需要傳輸 GB 級數據,SparseLoCo 全流程將其壓縮超過 146 倍。相當於把一整季電視劇壓縮成一張圖片,且信息損失極小。
- 僅 6% 通信開銷:100 個人協同工作,只有 6% 的時間在"溝通協調",94% 都在做實際訓練。這解決了去中心化訓練最大的瓶頸之一。
5. 去中心化訓練是否被低估?
先看數據,再做判斷。
被低估的證據
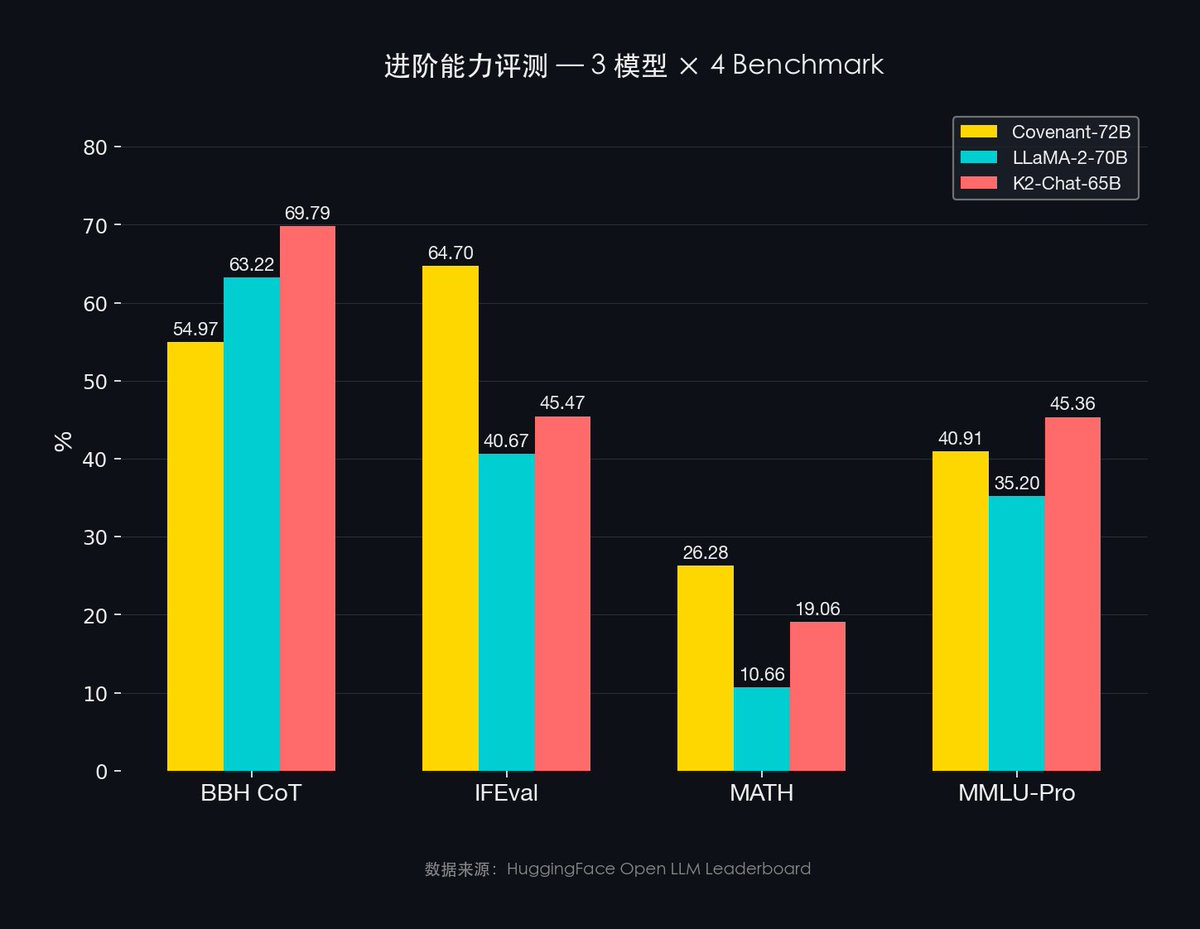
- MMLU 67.35% vs LLaMA-2 63.08%
- MMLU-Pro 40.91% vs LLaMA-2 35.20%
- IFEval 64.70% vs LLaMA-2 40.67%
去中心化訓練的模型,超過了 Meta 花重金訓練的 LLaMA-2-70B。
與當前頭部開源模型的差距(需要誠實面對):
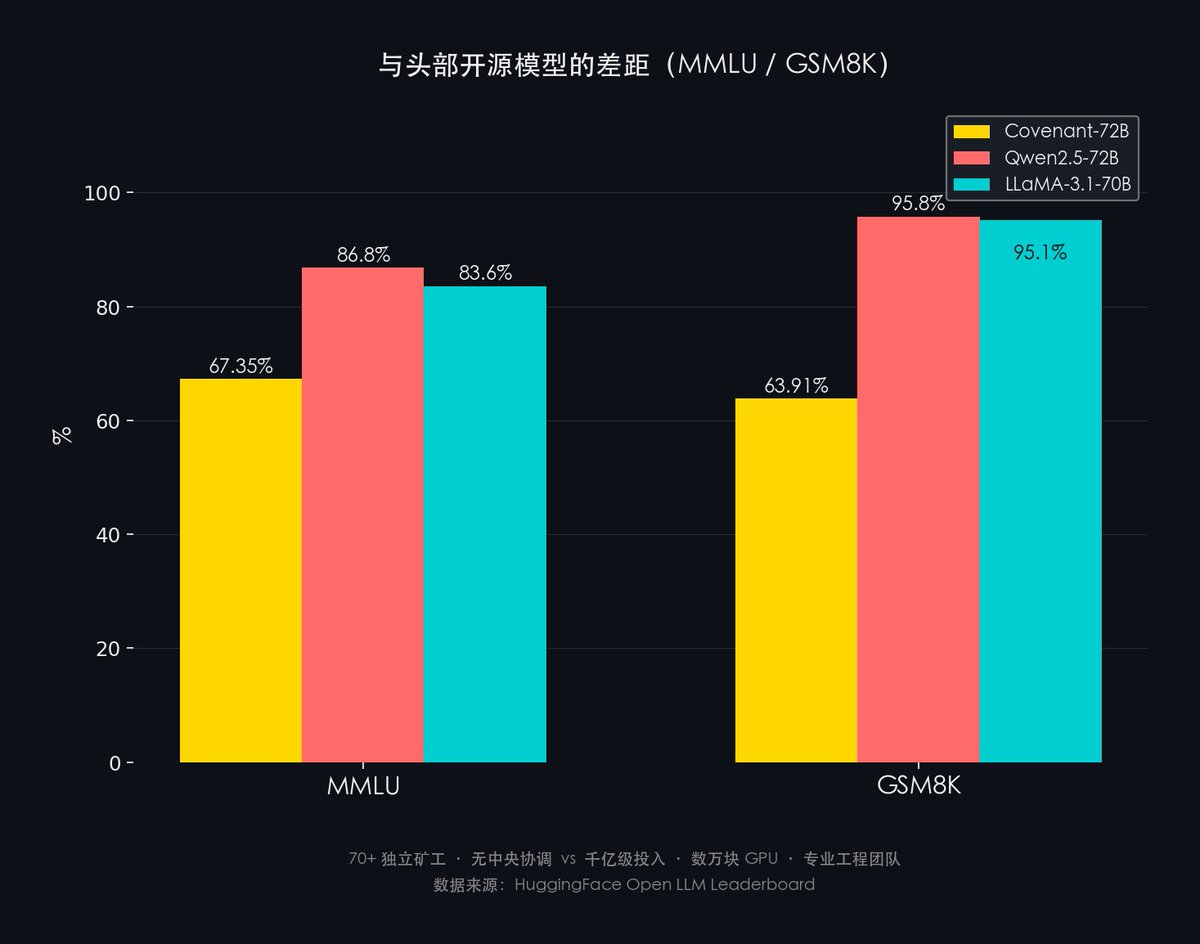
- MMLU: Covenant-72B 67.35% vs Qwen2.5-72B 86.8% vs LLaMA-3.1-70B 83.6%
- GSM8K: Covenant-72B 63.91% vs Qwen2.5-72B 95.8% vs LLaMA-3.1-70B 95.1%
差距約 20-30 個百分點。
但對比框架很重要:Covenant-72B 的意義不是打敗 SOTA,而是證明去中心化訓練可行。Qwen2.5 / LLaMA-3.1 背後是千億級投入 + 數萬塊 GPU + 專業工程團隊;Covenant-72B 則是 70+ 獨立礦工 + 無中央協調。
趨勢比快照重要:
- 2022 年:最好的去中心化模型是 6B 參數,連 MMLU 都沒單獨測。
- 2026 年:72B 模型,MMLU 67.35%,超越 Meta 同級別模型。
4 年時間,去中心化訓練從"概念實驗"走到了"性能可與集中式訓練比肩"。這條曲線的斜率,比任何單一 Benchmark 數字都更值得關注。
況且,Covenant-72B 在深度推理上的差距,已有規劃的解法——SN81 Grail 負責後訓練強化學習(RLHF),對模型進行對齊和能力提升。這正是 GPT-4 相對 GPT-3 最關鍵的改進步驟。
Heterogeneous SparseLoCo 是下一個里程碑:當前 SN3 要求所有礦工使用相同型號的 GPU。下一個重大技術突破是 Heterogeneous SparseLoCo,它將允許混合硬件(B200 + A100 + 消費級 GPU)參與同一訓練任務。一旦實現,下一輪訓練的算力池將大幅擴展。
去中心化訓練已跨過可行性門檻。當前 Benchmark 上的差距是需要繼續優化的工程問題,不是根本性的理論障礙。
Part II:市場仍然沒有理解這件事
TAO 價格時間線
SN3 公告發出後$TAO 的價格走勢,恰好揭示了這種認知滯後:
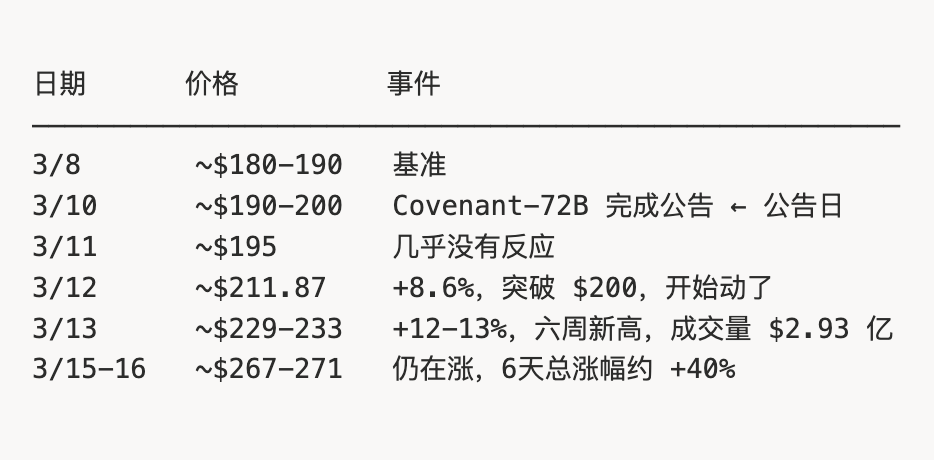
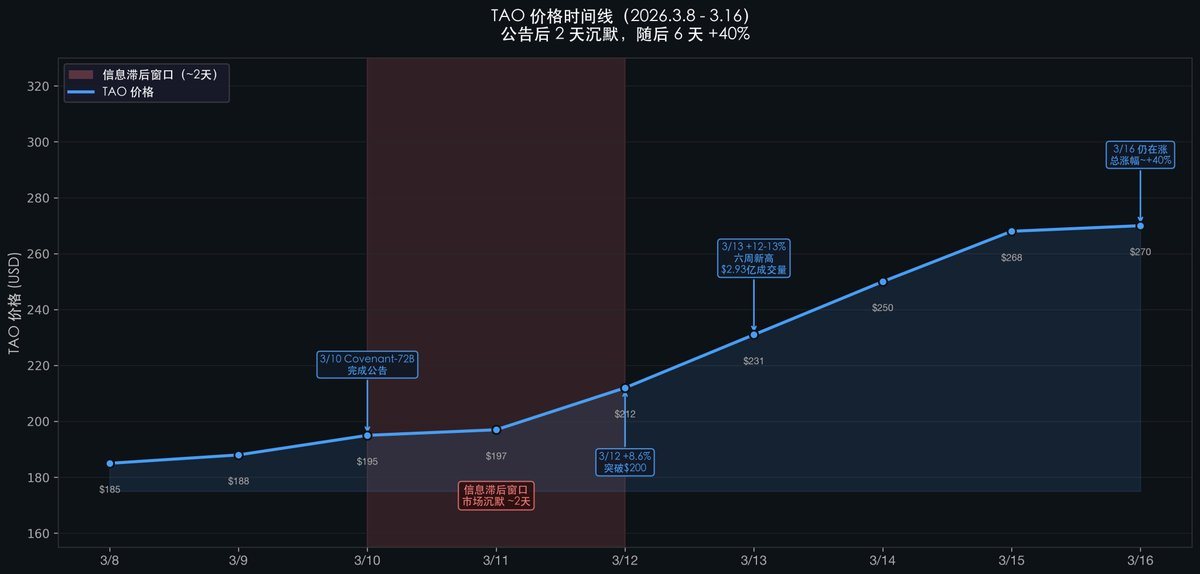
注意這 2 天的沉默(3/10 → 3/12):公告發出,價格幾乎沒動。
為什麼會有滯後?
加密投資者看到的消息是"Bittensor SN3 訓練完成了一個 AI 模型"——但他們不一定理解"72B 去中心化訓練在 MMLU 上超越 Meta"的技術意義。
AI 研究者能理解這個技術意義,但他們不關注 crypto。
兩個圈子的認知差,創造了約 2-3 天的價格滯後窗口。
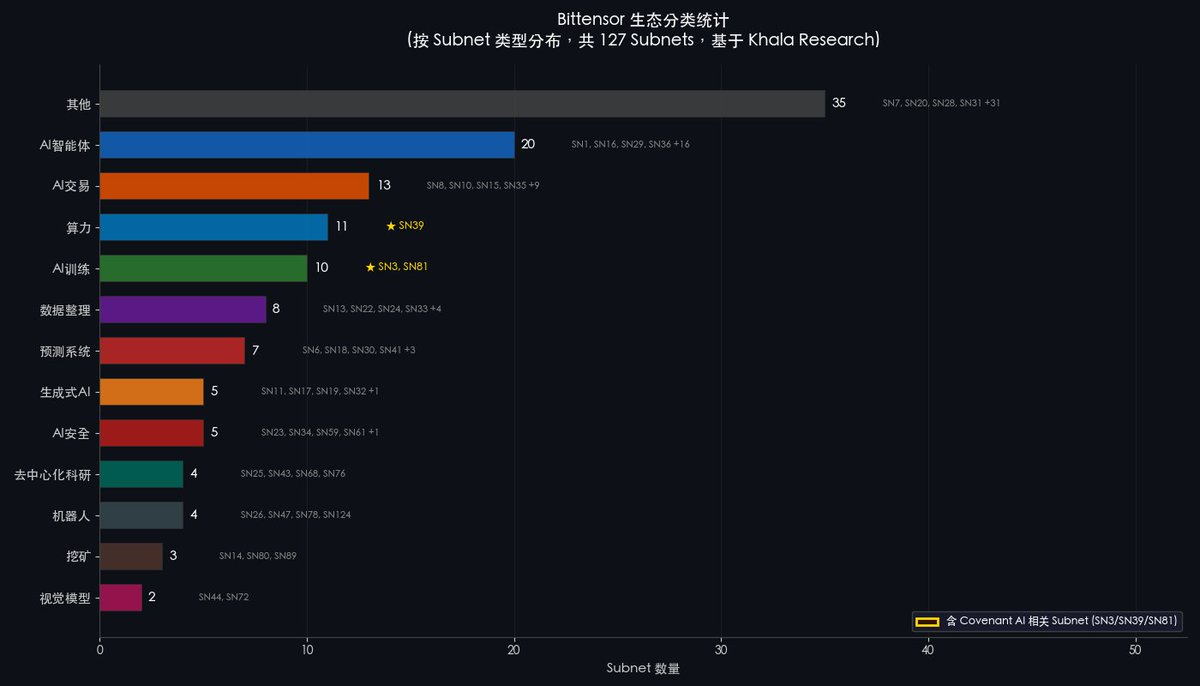
並且,大多數 Crypto 投資者對 Bittensor 的認知仍停留在上個週期。如今,Bittensor 上活躍子網已超過 79 個,覆蓋 AI Agent、算力、AI 訓練、AI 交易、機器人等截然不同的領域。當市場重新定價 Bittensor 的生態廣度時,這種認知差會被修正——而修正的過程,通常以價格暴漲的形式呈現。
Bittensor 的估值錯位
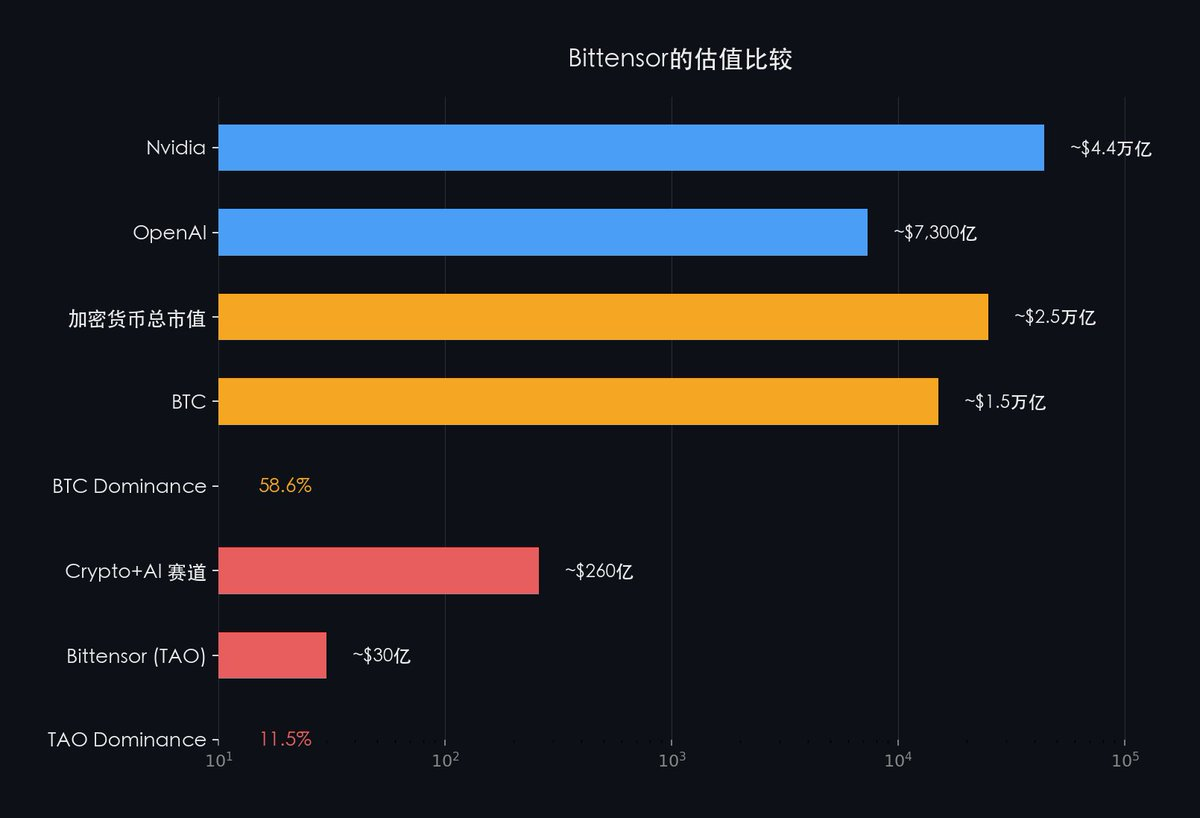
將 Bittensor 放入更大的產業背景:
SN3 已經證明:Bittensor 可以完成去中心化的大模型訓練。
如果未來 AI 需要開放、無需許可的訓練網絡,那麼目前唯一已經被實踐驗證的候選基礎設施,就是 Bittensor。
市場正在用應用層項目的估值邏輯定價一個 AI 基礎設施級別的網絡。
即使只在 Crypto 內部比較:Bitcoin 在整個 Crypto 市場中的市佔率長期達到 50~60%,而 Bittensor 在 Crypto AI 賽道中的佔比僅約 11.5%。
當市場重新理解 Bittensor 在 AI 基礎設施中的位置時,這種錯位必然會被修正。
結論:Bittensor 是 Crypto 全村的希望
如果說 SN3 Templar 的 Covenant-72B 證明了一件事,那就是:
去中心化網絡不僅可以協調資本,也可以協調算力與前沿 AI 研發。
過去幾年,Crypto 在 AI 敘事中大多隻是邊緣角色。大量項目依賴概念包裝、情緒炒作或資本敘事,但缺乏可驗證的技術產出。SN3 是一個明顯不同的案例。
它沒有推出新的 token 敘事,也沒有包裝一個"AI + Web3"的應用層產品,而是完成了一件更底層、更困難的事情:
在沒有中心化協調的情況下,訓練出了一個 72B 級別的大模型。
參與者來自全球各地,彼此無需信任;系統依靠鏈上的激勵與驗證機制自動協調訓練貢獻與收益分配。
Crypto 機制第一次在 AI 領域組織出了真實的生產力。
很多人還沒有理解 SN3 的歷史意義。就像當年很多人也沒有意識到,Bitcoin 證明的不是"更好的支付",而是無需中心信用的價值共識。
今天很多人看到的仍然只是 benchmark、模型發佈、或一輪價格上漲。
但真正發生的變化是,Bittensor 正在證明:
- Crypto 不只是能發行資產,它還能組織生產
- Crypto 不只是能交易注意力,它還能生產智能
開源社區可以貢獻代碼,學術界可以貢獻論文,但當問題進入超大規模訓練、長期協作、跨地域調度、反作弊與收益分配時,善意和聲譽體系遠遠不夠:
- 沒有經濟激勵,就沒有穩定供給
- 沒有可驗證的獎懲,就沒有長期協作
- 沒有代幣化協調機制,就無法形成真正全球化、無需許可的 AI 生產網絡
所以,Bittensor 是不是被低估了?答案不是"可能",而是"顯著地、系統性地被低估了"。
在"Crypto 是否還有存在意義"這場總辯論裡,Bittensor 正在給出全行業最有力的一份答案。
也正因如此:Bittensor 是 Crypto 全村的希望。
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News














