

The “Chinese Tax” of Large AI Models: Why Chinese Consumes More Tokens Than English
TechFlow Selected TechFlow Selected
The “Chinese Tax” of Large AI Models: Why Chinese Consumes More Tokens Than English
When engineers smooth out the rough edges of language to gain efficiency, the wisdom that unintentionally grows in those cracks quietly vanishes.
In the first few days after the release of Opus 4.7, complaints flooded X (formerly Twitter). Some users reported exhausting their session quota in a single conversation; others noted that the cost of running the same piece of code had more than doubled compared to the previous week; and still others shared screenshots showing their $200 Max subscriptions hitting the usage cap in under two hours.
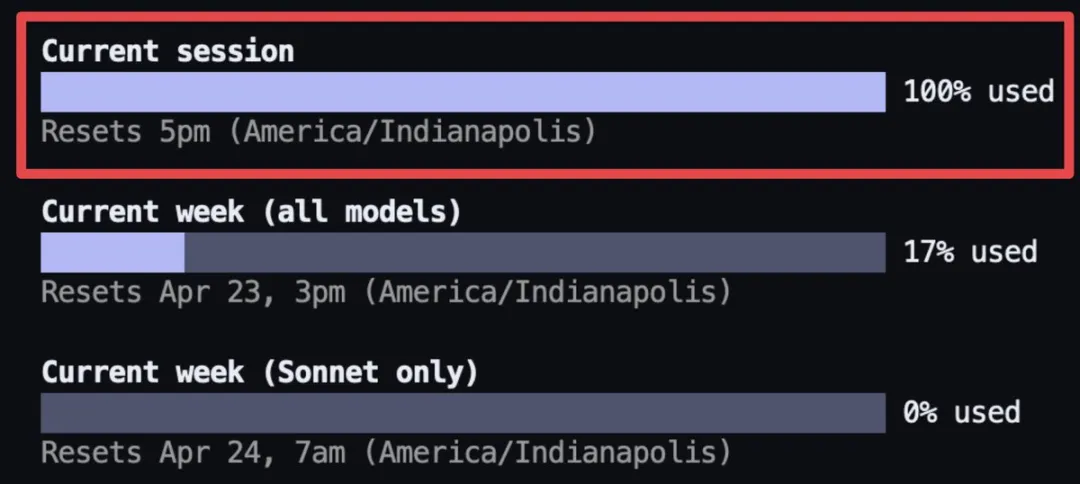
Independent developer BridgeMind acknowledged Claude as the world’s best model—but also its most expensive. His Max subscription hit the limit in under two hours, but fortunately—he’d purchased two subscriptions. | Image source: X@bridgemindai
Anthropic’s official pricing remains unchanged: $5 per million input tokens and $25 per million output tokens. However, this version introduced a new tokenizer, and Claude Code raised its default effort level from “high” to “xhigh.” Combined, these changes caused the same task to consume 2 to 2.7 times more tokens than before.
Within these discussions, I encountered two claims related to Chinese. The first was: Chinese token consumption barely increased under the new tokenizer, allowing Chinese users to avoid this price hike. The second, more intriguing claim was: Classical Chinese consumes fewer tokens than modern Mandarin—so conversing with AI in classical Chinese could reduce costs.
The first claim implies Anthropic optimized Claude specifically for Chinese, yet Anthropic’s official release documentation makes no mention of any Chinese-specific adjustments.
The second claim is even harder to explain. Classical Chinese is clearly more difficult for human readers than modern Mandarin; how, then, could a text more complex for humans be easier for AI?
So I conducted a test: feeding 22 parallel texts—including business news, technical documentation, classical Chinese, and everyday dialogues—into five tokenizers (Claude 4.6 and 4.7, GPT-4o, Qwen 3.6, and DeepSeek-V3), and recording the token count each text generated under each tokenizer for cross-comparison.

Test texts:
1. Everyday bilingual dialogues (travel, forum help requests, writing assistance)
2. Technical documentation in both languages (Python docs, Anthropic docs)
3. News in both languages (NYT political reporting, NYT business reporting, Apple’s official statements)
4. Literary excerpts in Chinese and English, including classical Chinese (e.g., “Chu Shi Biao,” “Tao Te Ching”)
After testing, both claims received partial validation—but reality proved more nuanced than rumor suggested.
The “Chinese Tax”
First, the conclusion:
1. On Claude and GPT models, Chinese has consistently been more expensive than English.
2. On Qwen and DeepSeek models, Chinese is actually cheaper than English.
3. The tokenizer upgrade behind Opus 4.7’s recent turbulence triggered inflation almost exclusively in English—Chinese token consumption remained virtually unchanged.
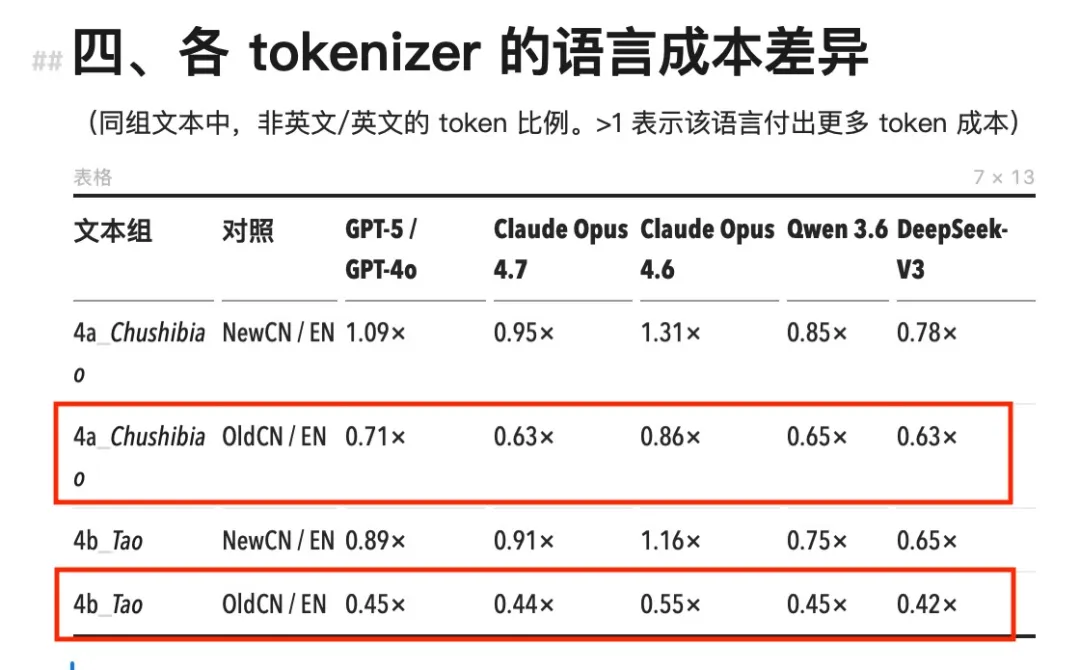
Let’s examine the numbers. All prior Claude models—including Opus 4.6, Sonnet, and Haiku—used the same tokenizer. Under this tokenizer, Chinese token consumption across the board exceeded that of equivalent English content, with Chinese-to-English (cn/en) ratios ranging from 1.11× to 1.64×.
The most extreme case occurred with NYT-style business news: the Chinese version consumed 64% more tokens than its English counterpart—effectively costing 64% more.
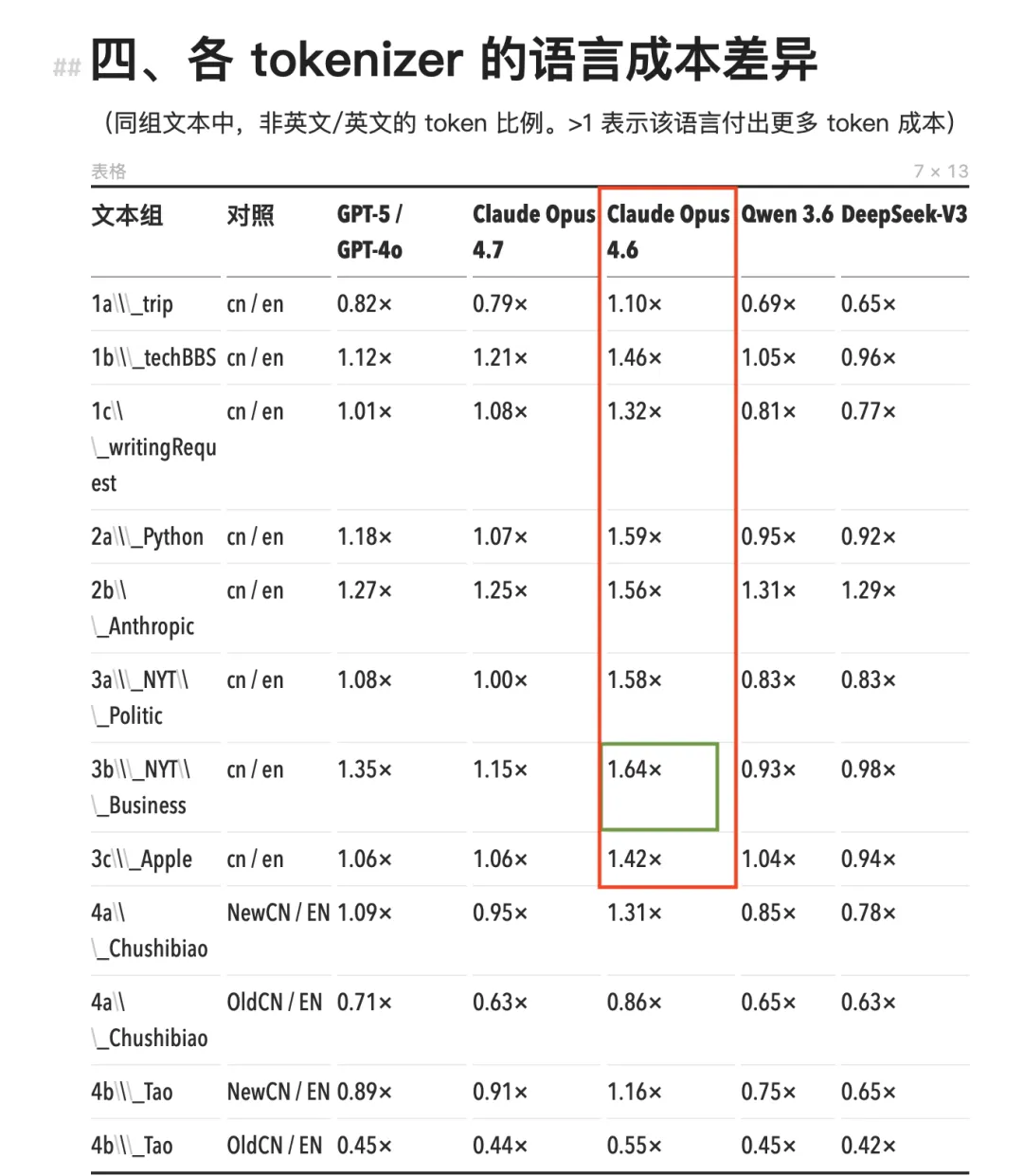
Under Opus 4.6 and earlier Claude models, Chinese token consumption significantly exceeded that of other models (red box).
The most extreme scenario appeared in NYT-style business news: the Chinese version consumed 64% more tokens (green box).
GPT-4o’s o200k tokenizer performs better, with cn/en ratios mostly between 1.0× and 1.35×—and in some cases below 1.0×. Chinese remains marginally more expensive overall, but the gap is far narrower than with Claude.
Domestic models Qwen 3.6 and DeepSeek-V3 show the opposite trend entirely. Their cn/en ratios fall widely below 1.0×—meaning identical content consumes fewer tokens in Chinese than in English. DeepSeek achieves as low as 0.65×, making the Chinese version one-third cheaper than its English counterpart.
Opus 4.7’s new tokenizer triggered inflation almost exclusively in English: English token counts rose by 1.24× to 1.63×, while Chinese remained largely at 1.000×—showing virtually no change. The billing shocks experienced by English-speaking developers at the outset truly went unnoticed by Chinese users. This may stem from the fact that Chinese had already been segmented down to the character level in the older tokenizer, leaving minimal room for further subdivision.
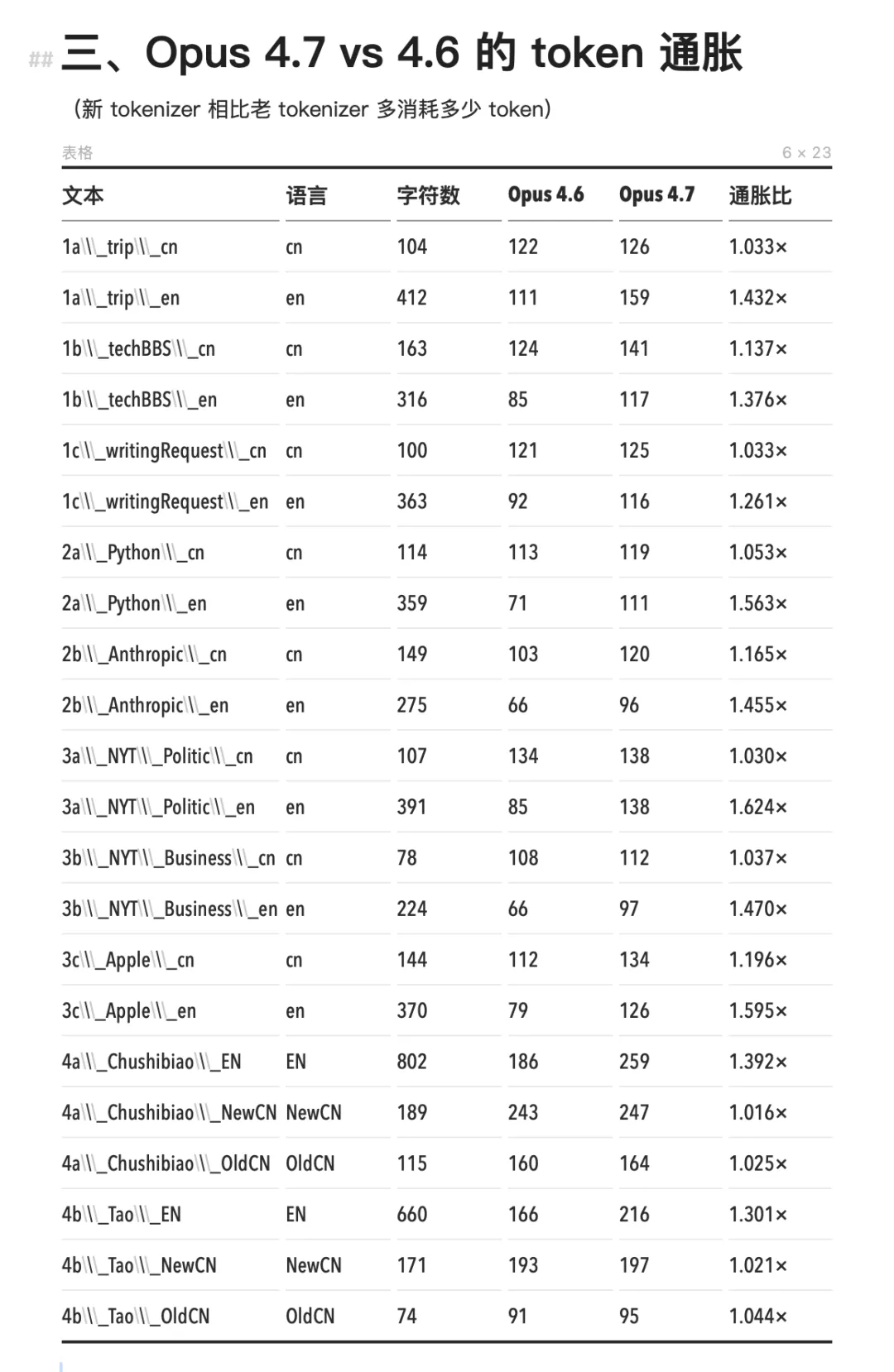
Compared to 4.6, Opus 4.7 increases token consumption for English—but leaves Chinese unchanged.
During testing, I also noticed another important detail: token consumption differences affect not just billing—they directly impact effective workspace size. With the same ~200K context window, using the older Claude tokenizer to load Chinese material yields 40% to 70% less usable content than with English.
For tasks like asking an AI to analyze a long document or summarize meeting notes, Chinese users can feed the model substantially less material—and thus provide shorter contextual references. The result? Paying more money for a smaller working space.
When viewing all four sets of data together, a natural question emerges:
Why does token count vary across languages for identical content? Why is Chinese more expensive on Claude and GPT, yet cheaper on Qwen and DeepSeek?
The answer lies in the concept repeatedly referenced above: the tokenizer.
How Many Pieces Can One Chinese Character Be Cut Into?
Before any text reaches a model, it passes through a tokenizer that slices the input into discrete tokens. Think of the tokenizer as AI’s “Lego block cutter”: you input a sentence, and it chops it into standardized blocks (tokens). The model doesn’t “see” text—it only recognizes token IDs. You pay per block used.
English tokenization aligns fairly intuitively with common sense—for example, “intelligence” is likely one token, and “information” is another. One word generally equals one billing unit.

But Chinese breaks down here. Feeding the same sentence—“人工智能正在重塑全球的信息基础设施”—into GPT-4’s cl100k tokenizer versus Qwen 2.5’s tokenizer produces completely different results.
GPT-4 essentially splits each Chinese character into its own token; Qwen instead recognizes multi-character words as single tokens—for instance, the four characters “人工智能” constitute just one token in Qwen.
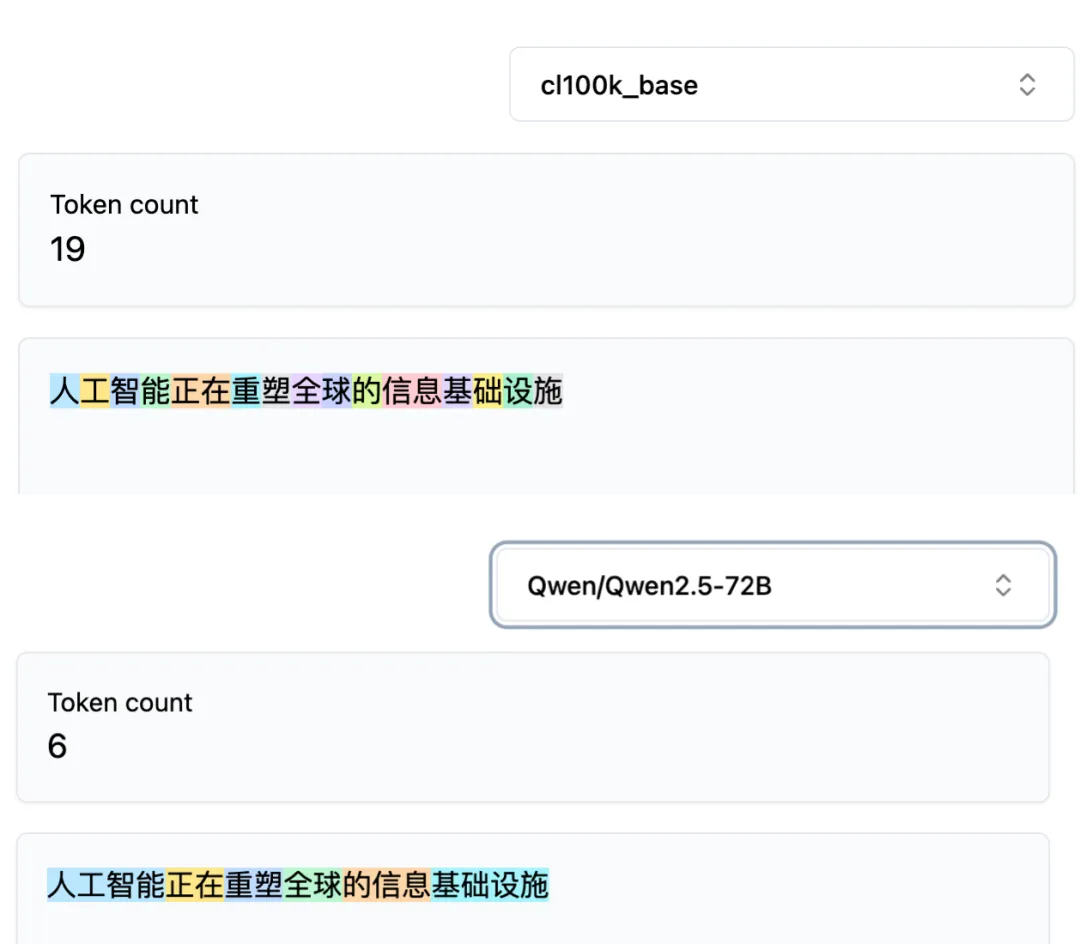
The same 16-character sentence yields 19 tokens in GPT-4 and only 6 in Qwen.
Why such divergent segmentation? The reason lies in an algorithm called BPE (Byte Pair Encoding).
BPE works by counting which character combinations appear most frequently in training data—and merging those high-frequency pairs into single tokens added to the vocabulary.
In the GPT-2 era, training data consisted overwhelmingly of English. English letter combinations (e.g., “th,” “ing,” “tion”) recurred constantly and were rapidly merged into tokens. Chinese characters appeared too infrequently in that corpus to enter the vocabulary—so they were treated as raw UTF-8 bytes. Since each Chinese character occupies three bytes in UTF-8, it became three tokens.

BPE merges based on character frequency in training data. Dominance of English text means Chinese UTF-8 bytes cannot merge into full characters.
Later, GPT-4’s expanded cl100k vocabulary began incorporating common Chinese characters, reducing most characters to 1–2 tokens—but overall efficiency still lagged behind English.
With GPT-4o’s larger o200k vocabulary, Chinese efficiency improved further—explaining why its cn/en ratio in the first dataset is lower than Claude’s.
Qwen and DeepSeek, as domestic models, incorporated large numbers of common Chinese characters and high-frequency phrases as whole-character or whole-word tokens from day one. One character = one token—doubling (or more) efficiency outright.

Illustration of segmentation differences for the same sentence across tokenizers
That’s why their cn/en ratios fall below 1.0×: Chinese characters inherently pack higher information density than English words—and when tokenizers stop artificially fragmenting them, this natural advantage manifests clearly.
Thus, the difference among the four datasets in the previous section stems not from model capability, but from how much space the tokenizer’s vocabulary reserves for Chinese.
Claude and early GPT vocabularies were built with English as the default; Chinese was retrofitted later. Qwen and DeepSeek vocabularies were designed from inception with Chinese as the default language. This foundational divergence propagates directly to token counts, billing, and context window capacity.
Is Classical Chinese Really Cheaper?
Now revisit the second claim mentioned earlier: classical Chinese consumes fewer tokens than modern Mandarin.
Data confirms this. In our test, classical Chinese samples showed cn/en ratios uniformly below 1.0× across all five tokenizers—the classical version of the same content consumed fewer tokens than its English translation.
Across all models, classical Chinese consumes fewer tokens than both modern Chinese and English.
The explanation is straightforward: classical Chinese is extremely concise. “学而不思则罔,思而不学则殆” uses only 12 characters. Its modern Mandarin translation—“只是学习而不思考就会迷惑,只是思考而不学习就会陷入困境”—more than doubles the character count, and token count rises accordingly.
Moreover, classical Chinese’s common function words (“之”, “也”, “者”, “而”, “不”) are high-frequency characters, each occupying a dedicated slot in every tokenizer’s vocabulary—not split into bytes. So classical Chinese is genuinely efficient at the encoding level.
But there’s a trap here.
Classical Chinese saves tokens at the encoding stage—but imposes no reduction on model inference load. A single character like “罔” requires the model to determine whether it means “bewildered,” “deceived,” or “nonexistent” within that context. Modern Mandarin spells out this nuance in 26 characters; classical Chinese compresses it, offloading interpretive work onto the model. Analogously, a ZIP file takes up less disk space—but decompression demands more computation.
Tokens saved, but inference cost rises—and accuracy drops. That’s not a favorable tradeoff.
This classical Chinese example made me realize: token count alone reveals surprisingly little. Yet following this line of thinking uncovered something else I’d previously overlooked.
As noted earlier, GPT-2-era tokenizers split “人” into three UTF-8 byte tokens; GPT-4’s expanded vocabulary turned common Chinese characters into one-token units; Qwen went further, encoding “人工智能” as a single token.
Intuitively, this seems like steady progress: more merging → higher efficiency → better understanding.
But is that really true? Let’s recall how humans learn Chinese characters.
Chinese is a logographic script. Over 80% of modern Chinese characters are phono-semantic compounds, composed of a semantic component (radical) and a phonetic component. Characters with the “氵” (water) radical often relate to liquids; those with “木” (wood) relate to plants; those with “火” (fire) relate to heat. Radicals serve as humanity’s most fundamental semantic cues when learning to read. Someone unfamiliar with “焱” can infer its fire-related meaning simply from seeing three stacked “火” components.
Because radicals are humanity’s most basic semantic cues, we first infer semantic categories from structure—and then refine specific meaning via context.

“Huǒhuā” (spark), “huǒyàn” (flame), “guāngyàn” (blaze): commonly found in formal writing and personal names, symbolizing brightness and intensity.
Yet in the tokenizer’s vocabulary, “焱” maps to a numeric ID—say, 38721. This ID represents merely an index position in the vocabulary; the model retrieves a vector representation for “焱” using that number.
The ID itself carries no structural information about the character. To the model, the relationship between IDs 38721 and 38722 is no different than that between 1 and 10000. Thus, the “structure of Chinese characters” becomes encapsulated. Three stacked “火” components simply don’t exist in the ID.
The model might indirectly learn that “焱,” “炎,” and “灼” co-occur in similar contexts through massive training—but that path is far more indirect than leveraging radical information directly.
So can models “see” radical-like structural cues within fragmented byte sequences—and reassemble them in subsequent computational layers? Though this approach incurs higher token counts and greater cost, might it actually yield superior semantic understanding compared to ingesting opaque, pre-merged IDs?
A 2025 paper published in MIT Press’s Computational Linguistics (“Tokenization Changes Meaning in Large Language Models: Evidence from Chinese”) addressed exactly this question.
Radicals Emerge From Fragments
Paper author David Haslett observed a historical coincidence.
In the 1990s, the Unicode Consortium assigned UTF-8 codes to Chinese characters in radical-based order. Characters sharing the same radical received adjacent UTF-8 codes. For instance, “茶” and “茎” both contain the “艹” (grass) radical—and share identical leading bytes in their UTF-8 sequences. Similarly, “河” and “海” both contain the “氵” (water) radical—and share leading bytes.
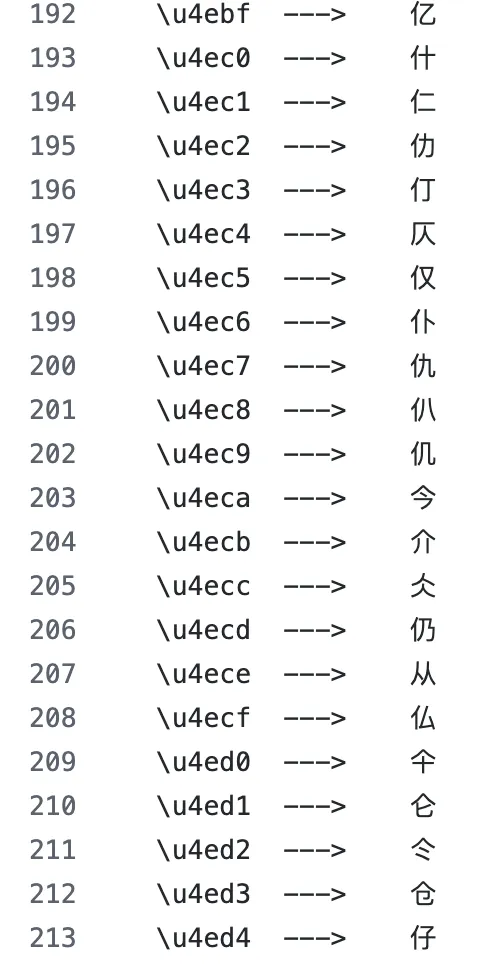
UTF-8 orders Chinese characters by radical groupings; characters sharing a radical have adjacent encodings. | Image source: GitHub
This means that when a tokenizer splits a Chinese character into three UTF-8 byte tokens, characters sharing the same radical will share the first token. During training, the model repeatedly encounters these shared byte patterns—and may learn that “characters sharing the same first token often belong to the same semantic category.” Functionally, this approximates how humans use radicals to infer meaning.
Haslett designed three experiments to verify this.
Experiment 1 asked GPT-4, GPT-4o, and Llama 3: Do “茶” and “茎” share the same semantic radical?
Experiment 2 asked models to score semantic similarity between two Chinese characters.
Experiment 3 tasked models with identifying the odd-one-out in a set of characters.
Each experiment controlled two variables: whether the two characters truly shared a radical, and whether they shared the first token under the given tokenizer. This 2×2 design allowed isolation of radical effects versus token effects.
All three experiments yielded consistent results: When characters were split into multiple tokens (e.g., under GPT-4’s older tokenizer, where 89% of characters were multi-token), models identified shared radicals more accurately. When characters were encoded as single tokens (under GPT-4o’s newer tokenizer, where only 57% remained multi-token), accuracy declined.
In other words, the earlier hypothesis held. Fragmenting characters indeed raises cost—but the fragmented byte sequences retain traces of radicals, and models genuinely learn from them. Encoding characters as whole-token IDs reduces cost, but radical information becomes buried in opaque numeric IDs—depriving the model of byte-level access to this cue.
It bears special emphasis that this finding applies strictly to fine-grained, shape-related semantic tasks—not to overall Chinese comprehension, logical reasoning, or long-text generation capabilities. Also, the experiments compared GPT-4 and GPT-4o, whose differences extend beyond tokenization to architecture, training data, and parameter count—so accuracy shifts cannot be attributed solely to token granularity adjustments.
This discovery also received engineering-side validation. A 2024 study on GPT-4o found that when its new tokenizer merged certain Chinese character combinations into long tokens, the model exhibited comprehension errors. When researchers re-split those long tokens using professional Chinese segmenters and fed the fragments back to the model, comprehension accuracy recovered.
The current mainstream consensus across the global LLM industry remains that language-optimized whole-word or whole-character tokenizers significantly boost overall model performance. Whole-character/whole-word encoding not only drastically cuts token costs and increases effective context-window information density, but also shortens sequence length, reduces inference latency, and improves long-text processing stability. The narrow-task advantages revealed in the paper cannot offset the broad performance gains across most Chinese NLP scenarios.
Yet this finding still touches on one of the hardest problems in large-scale systems: You can optimize what you’ve designed—but you cannot optimize what you don’t know you possess. The Unicode Consortium ordered encodings by radical for human search convenience. BPE splits Chinese characters into bytes because Chinese appears too infrequently in training corpora. Two unrelated engineering decisions coincidentally overlapped—creating an unplanned semantic channel.
Then, when a new generation of engineers “improves” tokenizers by merging characters into whole-token IDs, they simultaneously erase a pathway they never knew existed. Efficiency rises, cost falls—and something quietly vanishes, without even triggering an error message.
So the issue is more complex than simply “Chinese pays extra in AI.” Every tokenizer optimizes for some default—and the cost hides elsewhere.
Lin Yutang
The cost of adapting Chinese to Western technological infrastructure didn’t begin with the AI era.
In January 2025, Nelson Felix, a New York resident, posted several photos to a Facebook typewriter enthusiast group. He’d discovered a Chinese-inscribed typewriter among his wife’s grandfather’s belongings—and had no idea of its origin. Hundreds of comments poured in within hours.

Nelson Felix’s question: Is the Mingkai typewriter valuable? | Image source: Facebook
Stanford sinologist Thomas S. Mullaney recognized it instantly from the photos: it was the sole prototype of Lin Yutang’s 1947 “Mingkai Typewriter,” missing for nearly 80 years. In April that year, Felix and his wife sold the typewriter to Stanford University Libraries.
The Mingkai Typewriter confronted the same structural problem facing today’s tokenizers: How to embed Chinese efficiently into a technology infrastructure designed for Western languages.
1940s English typewriters featured 26 letter keys—one key per letter—simple and direct. Chinese has thousands of common characters; one-key-per-character was impossible. Contemporary Chinese typewriters employed massive type trays holding thousands of lead type pieces, requiring operators to manually select each character—yielding only a dozen characters per minute.

The earliest documented Chinese typewriter, invented in 1899 by American missionary Devello Z. Sheffield. | Image source: Wikipedia
Lin Yutang spent $120,000 in R&D funding—nearly bankrupting himself—to commission New York’s Carl E. Krum Company to build a Chinese typewriter with only 72 keys. Its operating principle involved splitting characters by structure: upper-shape keys selected top components, lower-shape keys selected bottom components, and candidate characters appeared in a small window dubbed the “magic eye,” selected via numeric keys. It achieved 40–50 characters per minute and supported over 8,000 common characters.

(Left) The transparent glass window is the “magic eye”; (Right) Internal structure of the Mingkai typewriter. | Image source: Facebook
Zhao Yuanren commented: “Whether Chinese or American, anyone with slight practice can master this keyboard. I believe this is precisely the typewriter we need.”
Technically, the Mingkai Typewriter was groundbreaking—but commercially, it failed.
During Lin Yutang’s demonstration to Remington executives, the machine malfunctioned, causing investors to lose interest. High manufacturing costs combined with Lin’s personal financial collapse made mass production impossible. In 1948, Lin sold the prototype and commercial rights to Mergenthaler Linotype Company, which ultimately abandoned mass production. The prototype vanished during company relocation in the 1950s, reportedly taken home by an employee to Long Island—until resurfacing in 2025.
In his book The Chinese Typewriter, Thomas Mullaney offers a nuanced judgment: the Mingkai Typewriter was “not a failure.” As a 1940s product, it indeed failed commercially. But as a human-computer interaction paradigm, it succeeded.
Lin Yutang pioneered transforming Chinese “typing” into “search-and-select”: three rows of keys combined to locate character components, with candidates displayed for selection. This is precisely the underlying logic of all modern Chinese input methods—from Cangjie and Wubi to Sogou Pinyin. All are, in essence, descendants of the Mingkai Typewriter.

The Chinese Typewriter, by Thomas S. Mullaney | Image source: Douban
This typewriter, spanning nearly eight decades, shares a hidden historical pattern with today’s tokenizer debates. Chinese has always faced one core challenge:
How to interface with infrastructure built upon the Roman alphabet.
Interestingly, this quest abounds with unplanned coincidences. The Unicode Consortium’s radical-based ordering—designed for human search convenience—overlapped with BPE’s accidental byte-level fragmentation, unexpectedly reconstructing human character recognition inside neural networks’ black boxes. And when engineers actively “reassemble” Chinese characters to eliminate the “Chinese tax” and reduce costs, that serendipitously born semantic channel closes.
History isn’t a straight-line evolutionary track—it’s a fluid substance continuously deformed under constraints.
Some capabilities are deliberately engineered; others simply survive—by accident, unremoved.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













