Jensen Huang’s Full GTC Keynote: The Era of Inference Has Arrived; Revenue to Reach at Least $1 Trillion by 2027; Lobster Is the New Operating System
TechFlow Selected TechFlow Selected
Jensen Huang’s Full GTC Keynote: The Era of Inference Has Arrived; Revenue to Reach at Least $1 Trillion by 2027; Lobster Is the New Operating System
NVIDIA is developing the “Vera Rubin Space-1,” a data center computer designed for deployment in space—opening up entirely new possibilities for extending AI computing power beyond Earth.
Source: WallStreetCN
On March 16, 2026, NVIDIA’s GTC 2026 conference officially opened, with NVIDIA founder and CEO Jensen Huang delivering the keynote address.
Dubbed the “annual pilgrimage for the AI industry,” this event marked Huang’s articulation of NVIDIA’s evolution—from a “chip company” to an “AI infrastructure and factory company.” Addressing market concerns over sustained performance and growth potential, Huang detailed the foundational business logic driving future growth: the “Token Factory Economics.”

Extremely Optimistic Guidance: “At Least $1 Trillion in Demand by 2027”
Over the past two years, global AI compute demand has exploded exponentially. As large models have evolved from “perception” and “generation” to “reasoning” and “action (task execution),” compute consumption has surged dramatically. In response to intense market scrutiny regarding order visibility and revenue ceilings, Huang offered remarkably strong forward guidance.
Huang stated explicitly during his keynote:
“This time last year, I said we saw $50 billion in high-confidence demand covering Blackwell and Rubin through 2026. Right here, right now, I see at least $1 trillion in demand by 2027.”

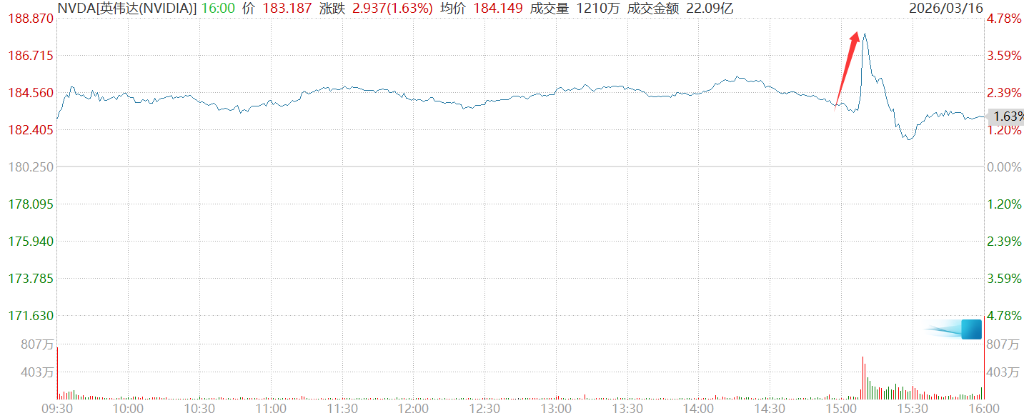
Huang’s trillion-dollar forecast briefly pushed NVIDIA’s stock up more than 4.3%.
Moreover, he added context to that figure:
“Is this reasonable? That’s exactly what I’ll explain next. In fact, supply will fall short of demand. I’m certain actual compute demand will be significantly higher.”
Huang pointed out that NVIDIA systems today have proven themselves the world’s “lowest-cost infrastructure.” Because NVIDIA hardware can run AI models across virtually every domain, its universality ensures that customers’ $1 trillion investment is fully utilized and enjoys an exceptionally long lifecycle.
Currently, 60% of NVIDIA’s business comes from the top five hyperscale cloud providers, while the remaining 40% spans sovereign clouds, enterprises, industrial applications, robotics, and edge computing.
Token Factory Economics: Per-Watt Performance Determines Commercial Viability
To justify the $1 trillion demand projection, Huang presented a new commercial framework to CEOs worldwide. He argued that future data centers are no longer file-storage warehouses—they are “factories” producing Tokens (the fundamental units generated by AI).

Huang emphasized:
“Every data center, every factory, is fundamentally power-constrained. A 1 GW (gigawatt) facility can never become a 2 GW facility—that’s governed by the laws of physics and atomic structure. Within fixed power limits, whoever achieves the highest tokens-per-watt throughput delivers the lowest production cost.”
Huang categorized future AI services into four commercial tiers:
- Free tier (high throughput, low speed)
- Mid-tier (~$3 per million tokens)
- Premium tier (~$6 per million tokens)
- High-speed tier (~$45 per million tokens)
- Ultra-high-speed tier (~$150 per million tokens)
He noted that as models grow larger and contexts lengthen, AI becomes smarter—but token generation rates decline. Huang added:
“In this Token Factory, your throughput and token generation speed directly translate into precise revenue for next year.”
Huang stressed that NVIDIA’s architecture enables customers to achieve extremely high throughput in the free tier—and simultaneously deliver a staggering 35x performance boost at the highest-value inference tier.

Vera Rubin Delivers 350x Acceleration in Two Years; Groq Fills the Ultra-Low-Latency Inference Gap
Within these physical constraints, NVIDIA unveiled Vera Rubin—the most complex AI computing system it has ever built. Huang remarked:
“When I used to talk about Hopper, I’d hold up a single chip—it was charming. But when you hear ‘Vera Rubin,’ you think of the entire system. In this 100% liquid-cooled system—where traditional cabling has been completely eliminated—a rack that previously took two days to install now takes just two hours.”
Huang explained that through end-to-end hardware-software co-design, Vera Rubin achieved extraordinary leaps in a single 1 GW data center:
“In just two years, we increased token generation rate from 22 million to 700 million tokens per second—a 350x improvement. Moore’s Law would have delivered only ~1.5x in the same period.”
To solve bandwidth bottlenecks under ultra-low-latency inference conditions (e.g., 1,000 tokens/sec), NVIDIA revealed its final integration plan for acquired company Groq: asymmetric disaggregated inference. Huang elaborated:
“These two processors are fundamentally different. The Groq chip has 500 MB of SRAM, whereas a single Rubin chip holds 288 GB of memory.”

Huang noted that NVIDIA’s Dynamo software system assigns the compute- and memory-intensive “prefill” phase to Vera Rubin, while offloading the latency-critical “decoding” phase to Groq. He also advised enterprises on compute allocation:
“If your workload is primarily high-throughput, use 100% Vera Rubin. If you have significant high-value programming-level token generation needs, allocate 25% of your data center capacity to Groq.”
Groq LP30 chips—manufactured by Samsung—are now in mass production and expected to ship in Q3. The first Vera Rubin rack is already running on Microsoft Azure cloud.
Additionally, addressing optical interconnect technology, Huang unveiled Spectrum X—the world’s first commercially available co-packaged optics (CPO) switch—and settled the “copper vs. optics” debate:
“We need more copper cable capacity, more optical chip capacity, and more CPO capacity.”
Agents End Traditional SaaS; “Salary + Tokens” Becomes Silicon Valley Standard
Beyond hardware barriers, Huang devoted substantial time to the revolution in AI software and ecosystems—particularly the explosion of Agents.
He described open-source project OpenClaw as “the most popular open-source project in human history,” noting it surpassed Linux’s 30-year achievements in just weeks. Huang declared OpenClaw is effectively the “operating system” for Agent computers.
Huang asserted:
“Every SaaS (Software-as-a-Service) company will become an AaaS (Agent-as-a-Service) company. To ensure secure deployment of agents capable of accessing sensitive data and executing code, NVIDIA introduced the enterprise-grade NeMo Claw reference design—with integrated policy engine and privacy router.”
For everyday professionals, this transformation is equally imminent. Huang painted a vivid picture of tomorrow’s workplace:
“In the future, every engineer in our company will receive an annual token budget. Their base salary may be hundreds of thousands of dollars—and I’ll add roughly half that amount in tokens to enable 10x productivity gains. This is already Silicon Valley’s new hiring leverage: How many tokens does your offer include?”
Finally, Huang teased NVIDIA’s next-generation computing architecture, Feynman—its first to support horizontal scaling for both copper and CPO. Even more evocative: NVIDIA is developing “Vera Rubin Space-1,” a space-based data center computer—opening the door to AI compute expansion beyond Earth.
Full transcript of Jensen Huang’s GTC 2026 keynote (AI-assisted translation):
Host: Welcome NVIDIA founder and CEO Jensen Huang to the stage.
Jensen Huang, Founder & CEO:
Welcome to GTC. Let me remind everyone: this is a technical conference. It’s truly exciting to see so many people lining up early—and to see all of you here.
At GTC, we focus on three pillars: technology, platforms, and ecosystems. NVIDIA currently operates three major platforms: the CUDA-X platform, the system platform, and our newest—the AI Factory platform.
Before we begin, I’d like to thank our pre-show hosts: Sarah Guo of Conviction, Alfred Lin of Sequoia Capital (NVIDIA’s first venture investor), and Gavin Baker (NVIDIA’s first major institutional investor). These three possess profound technical insight and wield enormous influence across the entire tech ecosystem. Of course, I also thank all the distinguished guests I personally invited today. Thank you to this all-star team.
I also thank all enterprises present today. NVIDIA is a platform company—built on technology, platforms, and a rich ecosystem. Today’s attendees represent nearly all participants across a $100 trillion industry. A total of 450 companies sponsored this event—we’re deeply grateful.
This conference features 1,000 technical sessions and 2,000 speakers, covering every layer of AI’s “five-layer cake” architecture—from land, power, and facilities (infrastructure), to chips, platforms, models, and finally the applications propelling the entire industry forward.
CUDA: Twenty Years of Technical Foundation
It all starts here. This year marks CUDA’s 20th anniversary.
For two decades, we’ve relentlessly advanced this architecture. CUDA is revolutionary—its SIMT (Single Instruction, Multiple Thread) paradigm lets developers write scalar code and scale it effortlessly into multithreaded applications, far simpler than prior SIMD architectures. We recently added Tiles functionality, making tensor core programming easier—and simplifying implementation of the mathematical operations essential to modern AI. Today, CUDA includes thousands of tools, compilers, frameworks, and libraries; hosts hundreds of thousands of open-source projects; and is deeply embedded in every major tech ecosystem.
This chart reveals NVIDIA’s 100% strategic logic—I’ve shown this slide since day one. The hardest—and most critical—element at the bottom is “installed base.” After twenty years, we’ve amassed hundreds of millions of CUDA-enabled GPUs and computing systems globally.
Our GPUs run on every cloud platform and serve virtually every computer OEM and industry. This massive installed base is the very flywheel accelerating everything. Installed base attracts developers; developers build new algorithms and breakthroughs; breakthroughs create new markets; new markets foster new ecosystems and attract more enterprises; and expanded ecosystems grow the installed base—this flywheel keeps spinning faster.
Downloads of NVIDIA libraries are growing at astonishing rates—huge volumes, accelerating constantly. This flywheel empowers our computing platform to support massive applications and continuous breakthroughs.
More importantly, it grants infrastructure exceptional longevity. Why? Because applications running on NVIDIA CUDA span every stage of the AI lifecycle, all data processing platforms, and scientific solvers across disciplines. Once deployed, NVIDIA GPUs deliver immense real-world value—which explains why Ampere-architecture GPUs launched six years ago are actually increasing in cloud pricing.
The root cause? Massive installed base, powerful flywheel, broad developer ecosystem. When combined with continuous software updates, compute costs keep falling. Accelerated computing delivers dramatic performance uplifts—and with long-term software maintenance and iteration, users gain not only initial performance leaps but ongoing cost reductions. We commit to supporting every GPU globally because they’re fully architecture-compatible.
We do this because the installed base is so vast—every optimization benefits millions. This dynamic combination lets NVIDIA’s architecture expand reach, accelerate growth, and continuously lower compute costs—ultimately fueling new growth. CUDA is central to it all.
From GeForce to CUDA: A 25-Year Evolution
Our journey with CUDA actually began 25 years ago.
GeForce—many of you grew up with it. GeForce was NVIDIA’s most successful marketing initiative. We started cultivating future customers before you could even afford our products—your parents became NVIDIA’s earliest users, buying our products year after year until you matured into exceptional computer scientists, becoming true customers and developers.
That’s the foundation laid by GeForce 25 years ago. Twenty-five years ago, we invented programmable shaders—a seemingly obvious yet profoundly consequential invention enabling accelerators to become programmable—the world’s first programmable accelerator, the pixel shader. Five years later, we created CUDA—our most important investment ever. With limited capital, we bet nearly all profits on extending CUDA from GeForce to every computer. We were unwavering because we believed deeply in its potential. Though early years were tough, we held firm for 13 generations—20 full years—until CUDA became ubiquitous.
Pixel shaders drove the GeForce revolution. About eight years ago, we launched RTX—a complete architectural overhaul for the modern computer graphics era. GeForce brought CUDA to the world—and that’s precisely why researchers like Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, and Andrew Ng discovered GPUs could accelerate deep learning, igniting AI’s big bang ten years ago.
Ten years ago, we decided to fuse programmable shading with two new ideas: first, hardware ray tracing—technically formidable; second, a visionary concept we foresaw a decade ago—that AI would transform computer graphics entirely. Just as GeForce brought AI to the world, AI is now reshaping how computer graphics are implemented.
Today, I’ll show you the future. Our next-generation graphics technology is called Neural Rendering—the deep fusion of 3D graphics and AI. This is DLSS 5—please watch.
Neural Rendering: Fusion of Structured Data and Generative AI
Isn’t this breathtaking? Computer graphics has been reborn.
What did we do? We combined controllable 3D graphics—the foundational truth of virtual worlds—with their structured data, then infused generative AI and probabilistic computing. One is deterministic; the other probabilistic yet highly realistic. We fused them—using structured data for precise control, while enabling real-time generation. The result: content that’s both stunning and fully controllable.
This fusion of structured information and generative AI will repeat across industry after industry. Structured data is the bedrock of trustworthy AI.
Accelerating Both Structured and Unstructured Data
Now let me walk you through a technical architecture diagram.
Structured data—familiar tools like SQL, Spark, Pandas, Velox, and major platforms including Snowflake, Databricks, Amazon EMR, Azure Fabric, and Google BigQuery—all operate on data frames. These data frames function like giant spreadsheets, holding all business-world information—the ground truth of enterprise computing.
In the AI era, we need AI to consume structured data—and accelerate it radically. Historically, accelerating structured data processing improved enterprise efficiency. In the future, AI will consume these data structures orders of magnitude faster than humans—and AI agents will make heavy use of structured databases.
Unstructured data—vector databases, PDFs, video, audio—constitutes the vast majority of the world’s data. Annually, ~90% of newly generated data is unstructured. Historically, this data was nearly unusable: we read it, stored it in file systems—and that was it. We couldn’t query or retrieve it, lacking simple indexing mechanisms; understanding meaning and context was required. Now AI can do exactly that—using multimodal perception and understanding, AI reads PDFs, comprehends their meaning, and embeds them into searchable, larger structures.
To address this, NVIDIA built two foundational libraries:
- cuDF: Accelerates data frames and structured data processing
- cuVS: Handles vector stores, semantic data, and unstructured AI data
These two platforms will become among the most critical foundational platforms going forward.
Today, we announce partnerships with multiple enterprises. IBM—the inventor of SQL—will use cuDF to accelerate its WatsonX Data platform. Dell co-developed the Dell AI Data Platform with us, integrating cuDF and cuVS, achieving major performance gains in NTT Data’s real-world deployments. On Google Cloud, we now accelerate both Vertex AI and BigQuery—and partnered with Snapchat to cut compute costs by nearly 80%.
Accelerated computing delivers threefold benefits: speed, scale, and cost. This aligns perfectly with Moore’s Law—achieving performance leaps via acceleration while continuously optimizing algorithms, ensuring everyone benefits from falling compute costs.
NVIDIA built the accelerated computing platform, hosting numerous libraries: RTX, cuDF, cuVS, and more. These libraries integrate into global cloud services and OEM ecosystems, reaching users worldwide.
Deep Collaboration with Cloud Providers
Collaboration with Major Cloud Providers
Google Cloud: We accelerate Vertex AI and BigQuery, deeply integrate with JAX/XLA, and perform exceptionally well on PyTorch—NVIDIA is the only accelerator excelling on both PyTorch and JAX/XLA. We’ve brought Base10, CrowdStrike, Puma, and Salesforce into the Google Cloud ecosystem.
AWS: We accelerate EMR, SageMaker, and Bedrock, with deep AWS integration. This year, I’m especially excited to bring OpenAI onto AWS—driving massive growth in AWS cloud consumption and helping OpenAI expand regional deployments and compute scale.
Microsoft Azure: NVIDIA’s 100 PFLOPS supercomputer was our first-built supercomputer—and the first deployed on Azure—laying the groundwork for our OpenAI collaboration. We accelerate Azure cloud services and AI Foundry, jointly expanding Azure regions, and collaborate deeply on Bing search. Notably, our **confidential computing** capability—ensuring even operators cannot access user data or models—makes NVIDIA GPUs among the world’s first to support confidential computing, enabling confidential OpenAI and Anthropic model deployments across global cloud environments. For Synopsys, we accelerate its entire EDA and CAD workflows deployed on Microsoft Azure.
Oracle: We were Oracle’s first AI customer—I’m proud to have introduced AI cloud concepts to Oracle for the first time. They’ve grown rapidly since, and we helped onboard partners including Cohere, Fireworks, and OpenAI.
CoreWeave: The world’s first AI-native cloud, purpose-built for GPU hosting and AI cloud services, with an outstanding customer base and strong growth momentum.
Palantir + Dell: A tripartite collaboration building a new AI platform based on Palantir’s Ontology Platform and AI Platform—deployable locally, air-gapped, and fully sovereign in any country, accelerating the full stack from data processing (vectorized or structured) to AI.
NVIDIA has forged unique relationships with global cloud providers—we bring customers to the cloud, creating a win-win ecosystem.
Vertical Integration, Horizontal Openness: NVIDIA’s Core Strategy
NVIDIA is the world’s first vertically integrated, horizontally open company.
This model’s necessity is simple: accelerated computing isn’t about chips or systems—it’s about application acceleration. CPUs can make computers faster overall, but that path has hit a wall. Only application- or domain-specific acceleration can sustain performance leaps and cost reductions moving forward.
That’s why NVIDIA must deeply engage library by library, domain by domain, vertical by vertical. We’re a vertically integrated computing company—there’s no alternative. We must understand applications, domains, algorithms—and deploy them anywhere: data centers, clouds, on-premises, at the edge, and in robotics.
Simultaneously, NVIDIA remains horizontally open—integrating our technology into any partner’s platform so the world can universally benefit from accelerated computing.
This year’s GTC attendee composition reflects this perfectly. Financial services represents the largest industry segment—though we hope it’s developers attending, not traders. Our ecosystem covers upstream and downstream supply chains. Whether companies founded 50, 70, or 150 years ago, last year was their best year ever. We stand at the beginning of something truly, truly momentous.
CUDA-X: Accelerated Computing Engines Across Industries
NVIDIA has deeply penetrated every vertical:
- Autonomous Driving: Broad coverage, profound impact
- Financial Services: Quantitative investing is shifting from manual feature engineering to supercomputer-driven deep learning—entering its “Transformer Moment”
- Healthcare: Its own “ChatGPT Moment” is arriving—spanning AI-assisted drug discovery, AI-agent diagnostic support, and healthcare customer service
- Industrial: The world’s largest construction wave is underway—AI factories, chip fabs, and data center factories are all materializing
- Entertainment & Gaming: Real-time AI platforms power translation, live streaming, game interaction, and intelligent shopping agents
- Robotics: Over a decade of deep R&D—three core computer architectures (training, simulation, and onboard computers) are complete; 110 robots debut at this show
- Telecom: A ~$2 trillion industry where base stations evolve from pure communication nodes to AI infrastructure platforms—Aerial platform, with deep collaborations with Nokia and T-Mobile
The core of all these domains is our CUDA-X library—the foundation of NVIDIA as an algorithm company. These libraries are our most critical assets, enabling our computing platform to deliver tangible value across industries.
One of the most important is cuDNN (CUDA Deep Neural Network library)—which revolutionized AI and ignited the modern AI big bang.
(Play CUDA-X demo video)
Everything you just saw was simulation—including physics-based solvers, AI-agent physics models, and physics-AI robot models. All simulation—no hand-animated rigs or joint bindings. This is NVIDIA’s core strength: unlocking these opportunities through deep algorithmic understanding tightly coupled with computing platforms.
AI-Native Enterprises and the New Computing Era
You just saw industry-defining giants—Walmart, L’Oréal, JPMorgan Chase, Roche, Toyota—as well as many companies you’ve never heard of—what we call AI-native enterprises. This list is enormous, including OpenAI, Anthropic, and numerous emerging firms serving diverse verticals.
Over the past two years, this sector has experienced explosive growth. Venture funding into startups reached $150 billion—humanity’s highest-ever total. More importantly, individual investment sizes jumped from millions to hundreds of millions—or even billions—of dollars. Why? For the first time in history, every such company requires massive compute resources and massive tokens. This industry creates, generates, or adds value to tokens from Anthropic, OpenAI, and others.
Just as the PC revolution, internet revolution, and mobile-cloud revolution each birthed epochal companies, this generation’s computing platform shift will similarly spawn highly influential companies—shaping the future world.
Three Historic Breakthroughs Driving This Transformation
What happened over the past two years? Three things.
First: ChatGPT—launching the generative AI era (late 2022–2023)
It doesn’t just perceive and understand—it generates unique content. I demonstrated generative AI fused with computer graphics. Generative AI fundamentally changed computing—shifting computation from retrieval to generation—profoundly impacting computer architecture, deployment, and meaning itself.
Second: Reasoning AI—exemplified by o1
Reasoning ability enables AI to self-reflect, plan, and decompose problems—breaking down incomprehensible challenges into manageable steps. o1 made generative AI trustworthy, enabling reasoning grounded in factual information. This dramatically increased input context tokens and output tokens used for thinking—significantly boosting compute requirements.
Third: Claude Code—the first agent model
It reads files, writes code, compiles, tests, evaluates, and iterates. Claude Code revolutionized software engineering—100% of NVIDIA engineers use Claude Code, Codex, or Cursor—or some combination thereof. No software engineer works without AI assistance.
This is a new inflection point—you no longer ask AI “what, where, how”—you command it to “create, execute, build,” empowering it to actively use tools, read files, decompose problems, and take action. AI has evolved from perception → generation → reasoning → now truly completing work.
Over the past two years, compute demand for reasoning has grown ~10,000x, usage ~100x. I’ve long believed compute demand surged 1 million-fold over those two years—this is everyone’s shared experience: OpenAI’s, Anthropic’s. More compute means more tokens, more revenue, smarter AI. The reasoning inflection point has arrived.
The Trillion-Dollar AI Infrastructure Era
This time last year, I stated here that we had high confidence in ~$50 billion in demand and purchase orders for Blackwell and Rubin through 2026. Today, one year later at GTC, I stand before you saying: Looking ahead to 2027, the number I see is at least $1 trillion. And I’m certain actual compute demand will far exceed that.
2025: NVIDIA’s Year of Inference
2025 is NVIDIA’s Year of Inference. We aim to ensure excellence across every stage of the AI lifecycle—not just training and post-training—but inference too—so invested infrastructure runs efficiently and sustains maximum useful life, lowering unit costs.
Meanwhile, Anthropic and Meta formally joined the NVIDIA platform—representing one-third of global AI compute demand. Open-source models now approach state-of-the-art performance and are ubiquitous.
NVIDIA is currently the world’s only platform capable of running all AI models—across language, biology, computer graphics, computer vision, speech, proteins and chemistry, robotics—on any edge or cloud, in any language. NVIDIA’s architecture is universally applicable across all these scenarios—making us the lowest-cost, highest-confidence platform.
Currently, 60% of NVIDIA’s business comes from the world’s top five hyperscale cloud providers; the remaining 40% spans regional clouds, sovereign clouds, enterprises, industrial applications, robotics, and edge computing. AI’s breadth is its resilience—this is unquestionably a new computing platform revolution.
Grace Blackwell and NVLink 72: Bold Architectural Innovation
While Hopper was still at peak, we decided to completely rearchitect the system—expanding NVLink from 8-way to NVLink 72, fully deconstructing and rebuilding the compute system. Grace Blackwell NVLink 72 was a massive technical bet—challenging for all partners—and I sincerely thank everyone.
Simultaneously, we launched NVFP4—not just ordinary FP4, but an entirely new type of tensor core and compute unit. We’ve proven NVFP4 delivers inference without precision loss—while delivering massive performance and energy-efficiency gains—and works equally well for training. Additionally, new algorithms like Dynamo and TensorRT-LLM emerged, and we even built a dedicated supercomputer—DGX Cloud—spending billions to optimize kernels.
Results prove our inference performance is remarkable. Semi Analysis data—the most comprehensive AI inference benchmark to date—shows NVIDIA leads decisively on both tokens-per-watt and cost-per-token. Moore’s Law might have given H200 a 1.5x performance boost—but we delivered 35x. Semi Analysis’ Dylan Patel even said: “Jensen sandbagged—it’s actually 50x.” He’s right.
I quote him directly: “Jensen sandbagged.”
NVIDIA’s cost-per-token is the world’s lowest—unmatched today. The reason is extreme co-design.
Take Fireworks: Before NVIDIA updated its full software and algorithm stack, average token speed was ~700 tokens/sec; after updating, it approached ~5,000 tokens/sec—a ~7x improvement. This is the power of extreme co-design.
AI Factories: From Data Centers to Token Factories
Data centers were once file storage locations—they’re now token factories. Every cloud provider and AI company will soon measure success by “token factory efficiency.”
My core thesis:
- Y-axis: Throughput—tokens per second generated under fixed power
- X-axis: Token Speed—response latency per inference; faster speeds enable larger models, longer contexts, and smarter AI
Tokens are the new commodity—once mature, they’ll be tiered in pricing:
- Free tier (high throughput, low speed)
- Mid-tier (~$3 per million tokens)
- Premium tier (~$6 per million tokens)
- High-speed tier (~$45 per million tokens)
- Ultra-high-speed tier (~$150 per million tokens)
Compared to Hopper, Grace Blackwell delivers 35x higher throughput at the highest-value tier—and introduces new tiers. Simplified modeling suggests allocating 25% power to each of four tiers yields 5x more revenue from Grace Blackwell versus Hopper.
Vera Rubin: Next-Generation AI Computing System
(Play Vera Rubin system intro video)
Vera Rubin is a complete, end-to-end optimized system designed for agentic workloads:
- Large Language Model Compute Core: NVLink 72 GPU cluster handling prefill and KV cache
- New Vera CPU: Designed for extreme single-thread performance, using LPDDR5 memory—delivering exceptional energy efficiency; the world’s only data-center CPU using LPDDR5, ideal for AI agent tool invocation
- Storage System: BlueField 4 + CX 9—a new storage platform for the AI era, adopted by 100% of the global storage industry
- CPO Spectrum X Switch: World’s first co-packaged optical Ethernet switch—now in full production
- Kyber Rack: New rack system supporting 144 GPUs in a single NVLink domain—front-end compute, back-end NVLink switching—forming one giant computer
- Rubin Ultra: Next-gen supercomputing node, vertical-insertion design, paired with Kyber racks for larger-scale NVLink interconnect
Vera Rubin is 100% liquid-cooled, installation time reduced from two days to two hours, cooled by 45°C hot water—dramatically easing data center cooling burdens. Satya (Nadella) has confirmed the first Vera Rubin rack is now live on Microsoft Azure—I’m thrilled.
Groq Integration: Pushing Inference Performance to the Extreme
We acquired the Groq team and licensed its technology. Groq is a deterministic dataflow processor—using static compilation and compiler scheduling, with abundant SRAM—optimized for single-inference workloads, delivering ultra-low latency and extremely high token generation speed.
However, Groq’s memory capacity is limited (500MB on-chip SRAM), insufficient to independently host large-model parameters and KV caches—limiting broad applicability.
The solution is Dynamo—a unified inference scheduling software. Through Dynamo, we disaggregate the inference pipeline:
- **Prefill and attention decode** happen on Vera Rubin (requiring massive compute and KV cache storage)
- **Feed-forward network decode**—i.e., token generation—happens on Groq (requiring ultra-high bandwidth and ultra-low latency)
Both connect tightly via Ethernet, reducing latency by ~half using special modes. Under Dynamo—the “AI Factory OS”—overall performance improves 35x, unlocking new inference performance tiers unreachable by NVLink 72 alone.
Groq + Vera Rubin deployment recommendations:
- If workloads are predominantly high-throughput, use 100% Vera Rubin
- If large workloads involve high-value token generation (e.g., code generation), introduce Groq—recommended ratio ~25% Groq + 75% Vera Rubin
Groq LP30 chips—manufactured by Samsung—are in mass production and scheduled to ship in Q3. Thanks to Samsung’s full cooperation.
Historic Leap in Inference Performance
Quantifying prior progress: In two years, a 1 GW AI factory’s token generation rate jumps from 22 million to 700 million tokens/sec—a 350x increase. This is the power of extreme co-design.
Technology Roadmap
- Blackwell: Currently in production—Oberon standard rack system, copper expansion to NVLink 72, optional optical expansion to NVLink 576
- Vera Rubin (current): Kyber rack, NVLink 144 (copper); Oberon rack, NVLink 72 + optical, scalable to NVLink 576; Spectrum 6—world’s first CPO switch
- Vera Rubin Ultra (upcoming): Next-gen Rubin Ultra GPU, LP35 chip (first to integrate NVFP4), delivering multi-fold performance gains
- Feynman (next-gen): New GPU, LP40 chip (co-developed by NVIDIA and Groq teams, integrating NVFP4); new CPU—Rosa (Rosalyn); BlueField 5; CX 10; Kyber rack supporting both copper and CPO expansion
The roadmap is clear: parallel advancement along copper scaling, optical scaling (scale-up), and optical scaling (scale-out)—we need all partners to ramp copper, fiber, and CPO capacity.
NVIDIA DSX: Digital Twin Platform for AI Factories
AI factories grow increasingly complex—but constituent technology suppliers historically never collaborated during design, only meeting in data centers. That’s insufficient.
So we built Omniverse—and atop it, NVIDIA DSX: a platform enabling all partners to collaboratively design and operate gigawatt-scale AI factories in the virtual world. DSX delivers:
- Rack-level mechanical, thermal, electrical, and network simulation systems
- Grid connectivity for collaborative energy-saving scheduling
- Max-Q-based dynamic power and cooling optimization within data centers
Conservatively, this system improves energy efficiency by ~2x—a massive gain at our scale. Omniverse began with Digital Earth and now hosts digital twins of all scales—we’re collaborating globally to build humanity’s largest computer.
Additionally, NVIDIA is entering space. Thor chips have passed radiation certification and are operating in satellites. We’re partnering to develop Vera Rubin Space-1 for space-based data centers. In space, only radiative cooling is possible—thermal management is the core challenge, and we’re assembling top engineers to solve it.
OpenClaw: The Operating System for the Agent Era
Peter Steinberger developed OpenClaw—a software project. It’s the most popular open-source project in human history, surpassing Linux’s 30-year achievements in just weeks.
OpenClaw is fundamentally an agentic system capable of:
- Managing resources, accessing tools, file systems, and large language models
- Executing scheduling and timed tasks
- Decomposing problems step-by-step and invoking sub-agents
- Supporting arbitrary modalities—voice, video, text, email, etc.
Described in OS terms, it truly is an operating system—the OS for agent computers. Windows made personal computing possible; OpenClaw makes personal agents possible.
Every enterprise needs its own OpenClaw strategy—just as we all need Linux strategies, HTML strategies, Kubernetes strategies.
Complete Reshaping of Enterprise IT
Pre-OpenClaw enterprise IT: Data and files enter systems, flow through tools and workflows, ultimately becoming human-facing tools. Software companies build tools; system integrators (GSIs) and consultants help enterprises use them.
Post-OpenClaw enterprise IT: Every SaaS company becomes an AaaS (Agentic-as-a-Service) company—not just providing tools, but specialized AI agents for specific domains.
But a key challenge remains: enterprise agents can access sensitive data, execute code, and communicate externally—strict governance is mandatory in enterprise environments.
To address this, we partnered with Peter to bake security into the enterprise version, launching:
- NeMo Claw (reference design): An enterprise-grade reference framework based on OpenClaw, integrating NVIDIA’s full suite of agent AI tools
- Open Shield (security layer): Integrated into OpenClaw, providing policy engine, network guardrails, and privacy routing—ensuring enterprise data security
- NeMo Cloud: Downloadable and interoperable with all SaaS enterprises’ policy engines
This is the Renaissance of enterprise IT—an industry originally valued at $2 trillion, now poised to grow into the multi-trillion-dollar range—shifting from tool provision to specialized AI agent services.
I foresee clearly: Every engineer in our company will receive an annual token budget. Their base salary may be hundreds of thousands of dollars—I’ll grant them an additional token allocation equal to roughly half their salary, enabling 10x productivity gains. “How many tokens come with your offer?” is now Silicon Valley’s hottest hiring topic.
Every enterprise will soon be both a token consumer (for engineers) and a token producer (for customers). OpenClaw’s significance is immeasurable—it’s as vital as HTML and Linux.
NVIDIA Open Model Initiative
For custom agents (Custom Claw), we provide NVIDIA’s cutting-edge in-house models:
Model Domains: Nemotron (large language models), Cosmos (world foundation model), GROOT (general-purpose humanoid robot model), Alpamayo (autonomous driving), BioNeMo (digital biology), Phys-AI (physics)
We lead in every domain—and commit to continuous iteration: Nemotron 3 → Nemotron 4, Cosmos 1 → Cosmos 2, Groq → Gen 2.
Nemotron 3 ranks among the world’s top three models in OpenClaw—state-of-the-art. Nemotron 3 Ultra will be the strongest foundation model ever—supporting sovereign AI development worldwide.
Today, we announce the Nemotron Alliance—investing billions to advance AI foundation model R&D. Alliance members include: BlackForest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam (India), Thinking Machines (Mira Murati’s lab), and more. Enterprise software companies are joining en masse—integrating NeMo Claw reference design and NVIDIA agent AI toolkits into their products.
Physical AI and Robotics
Digital agents act in the digital world—writing code, analyzing data—while Physical AI is embodied intelligence: robots.
This GTC features 110 robots—nearly every global robotics developer. NVIDIA provides three computers (training, simulation, onboard) plus full software stacks and AI models.
Autonomous driving: Its “ChatGPT Moment” has arrived. Today, we announce four new partners joining NVIDIA’s RoboTaxi Ready platform: BYD, Hyundai, Nissan, Geely—totaling 18 million vehicles annually. Adding Mercedes-Benz, Toyota, and GM, the lineup grows stronger. We also announce a major partnership with Uber—to deploy and integrate RoboTaxi Ready vehicles across multiple cities.
Industrial robotics: ABB, Universal Robotics, KUKA, and others partner with us—combining physical AI models and simulation systems to deploy robots across global manufacturing lines.
Telecom: Caterpillar and T-Mobile join this effort. Future wireless base stations won’t just be communication nodes—they’ll become NVIDIA Aerial AI RANs: intelligent edge computing platforms sensing traffic in real time, adjusting beamforming, and enhancing energy efficiency.
Special Segment: Olaf Robot Debut
(Play Disney Olaf robot demo video)
Jensen Huang: Snowman enters! Newton is running! Omniverse is running! Olaf, how are you?
Olaf: I’m so happy to see you!
Jensen Huang: Yes—because I gave you your computer—Jetson!
Olaf: What’s that?
Jensen Huang: It’s inside your belly.
Olaf: Amazing!
Jensen Huang: You learned to walk in Omniverse.
Olaf: I love walking. It’s much better than riding reindeer and gazing at beautiful skies.
Jensen Huang: That’s thanks to physics simulation—the Newton solver running on NVIDIA Warp, jointly developed with Disney and DeepMind—enabling you to adapt to the real physical world.
Olaf: That’s exactly what I was about to say.
Jensen Huang: That’s why you’re smart. I’m a snowman—not a snowball.
Jensen Huang: Can you imagine? Future Disneyland—robots like you freely strolling the park. Honestly though, I thought you’d be taller. I’ve never seen such a short snowman.
Olaf: (noncommittal)
Jensen Huang: Will you help me wrap up today’s keynote?
Olaf: Awesome!
Keynote Summary
Jensen Huang: Today, we explored these core themes:
- The Arrival of the Inference Inflection Point: Inference is now AI’s most critical workload; tokens are the new commodity; inference performance directly determines revenue
- The AI Factory Era: Data centers have evolved from file storage to token factories; every company will soon measure competitiveness by “AI Factory efficiency”
- The OpenClaw Agent Revolution: OpenClaw inaugurates the agent computing era; enterprise IT is shifting from tools to agents—every enterprise needs an OpenClaw strategy
- Physical AI and Robotics: Embodied intelligence is scaling—autonomous driving, industrial robots, and humanoid robots collectively form the next major opportunity for Physical AI
Thank you all—and enjoy GTC!
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News