基于DeepSeek发布的技术报告,解读 DeepSeek - R1 的训练过程。
作者:江信陵,为AI发电

图片来源:由无界AI生成
DeepSeek 是如何训练其 R1 推理模型的?
本文主要基于DeepSeek发布的技术报告,解读 DeepSeek - R1 的训练过程;重点探讨了构建和提升推理模型的四种策略。
原文来自研究员 Sebastian Raschka,发表于:
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
本文会对其中R1推理模型核心训练部分进行总结。
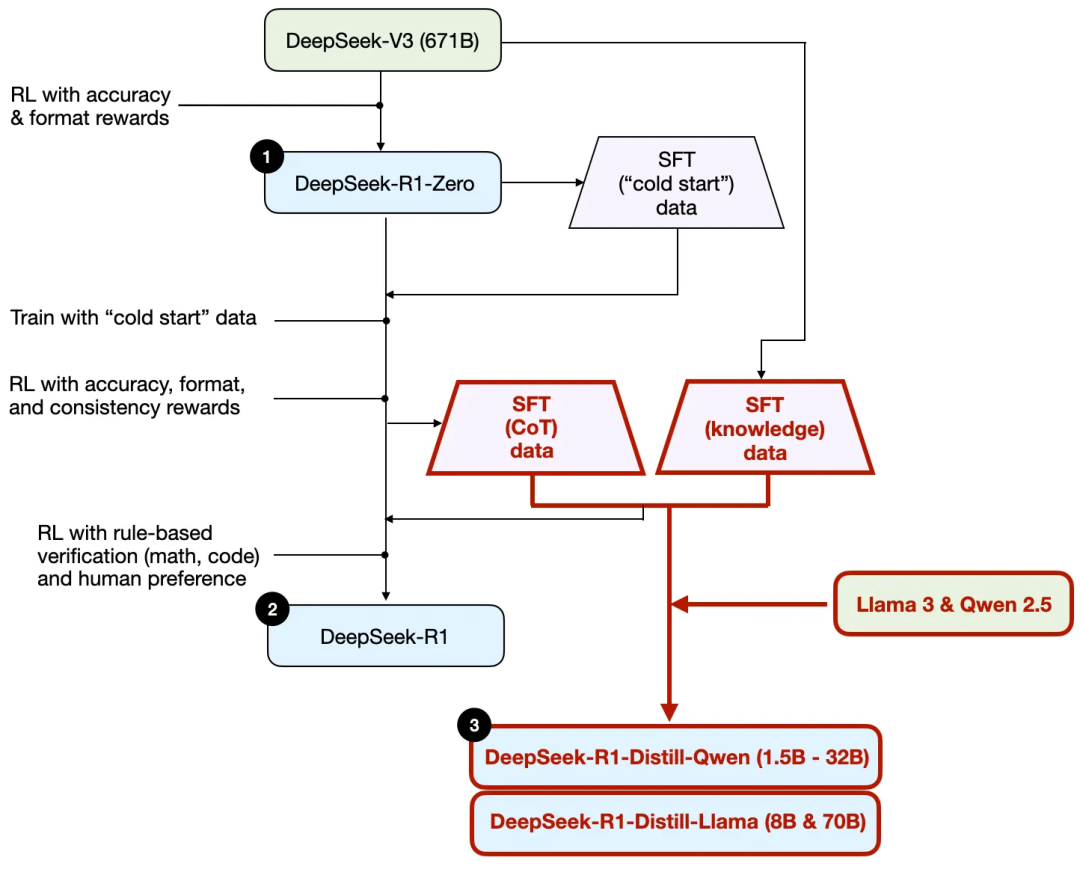
首先,基于DeepSeek发布的技术报告,以下是一张R1的训练图。
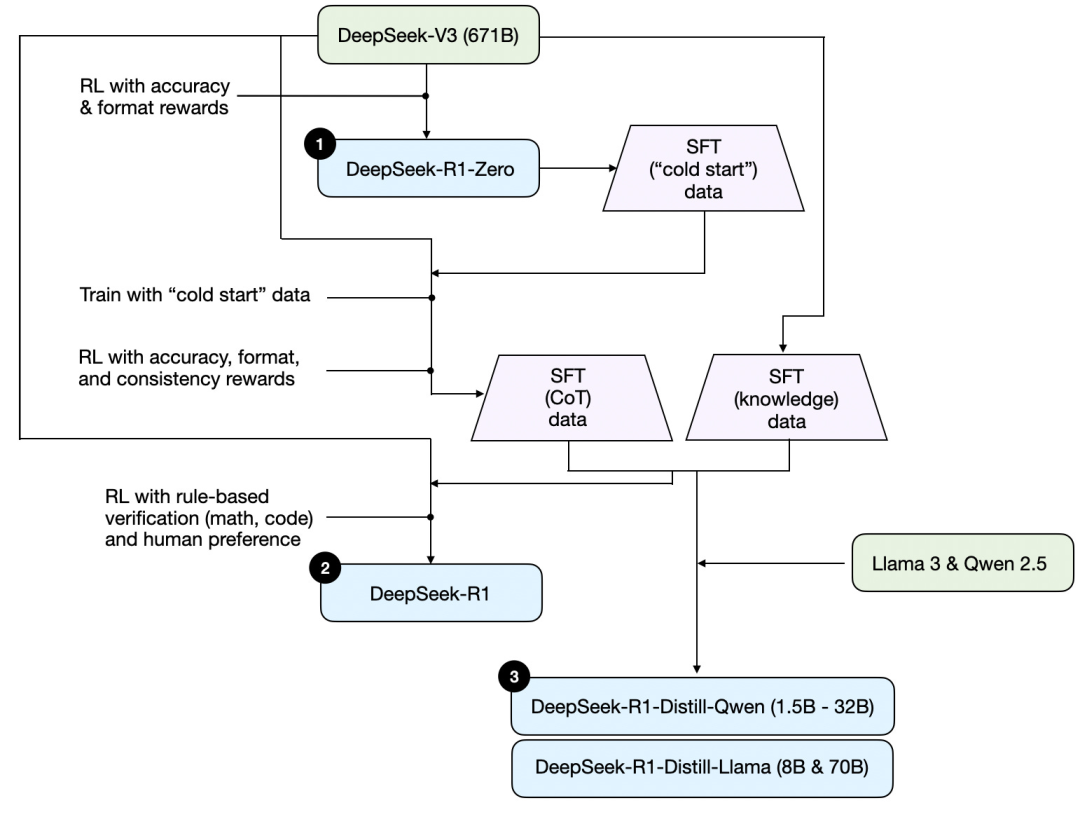
梳理一下上图所示的过程,其中:
(1) DeepSeek - R1 - Zero:该模型是基于去年 12 月发布的 DeepSeek - V3 基模。使用具有两种奖励机制的强化学习(RL)对其进行训练。这种方法被称为 “冷启动” 训练,因为它不包括监督微调(SFT)步骤,而监督微调通常是人类反馈强化学习(RLHF)的一部分。
(2) DeepSeek - R1:这是 DeepSeek 的主打推理模型,基于 DeepSeek - R1 - Zero 构建。团队通过额外的监督微调阶段和进一步的强化学习训练对其进行了优化,改进了 “冷启动” 的 R1 - Zero 模型。
(3) DeepSeek - R1 - Distill:DeepSeek 团队利用前几步生成的监督微调数据对 Qwen 和 Llama 模型进行了Fine Tuning,以增强它们的推理能力。虽然这并非传统意义上的蒸馏,但该过程涉及到利用较大的 671B的 DeepSeek - R1 模型的输出对较小的模型(Llama 8B 和 70B,以及 Qwen 1.5B - 30B)进行训练。
以下会介绍构建与提升推理模型的四种主要方法
1、推理时扩展 / Inference-time scaling
提升 LLM 推理能力(或通常意义上的任何能力)的一种方法是推理时扩展 - 在推理过程中增加计算资源,以提高输出质量。
打个粗略的比方,就像人在有更多时间思考复杂问题时,往往能给出更好的回答。同样,我们可以运用一些技术,促使 LLM 在生成答案时 “思考” 得更深入。
实现推理时扩展的一种简单方法是巧妙的提示工程 / Prompt Engineering。一个经典例子是思维链提示 / CoT Prompting,即在输入提示中加入诸如 “逐步思考” 这样的短语。这会促使模型生成中间推理步骤,而不是直接跳到最终答案,这样往往能在更复杂的问题上得出更准确的结果。(注意,对于像 “法国的首都是什么” 这类较简单的基于知识的问题,采用这种策略就没有意义,这也是判断推理模型对于给定输入查询是否适用的一个实用经验法则。)

上述思维链(CoT)方法可被视为推理时扩展,因为它通过生成更多输出tokens,增加了推理成本。
推理时扩展的另一种方法是采用投票和搜索策略。一个简单的例子是多数投票法,即让LLM生成多个答案,然后通过多数表决选出正确答案。同样,我们可以使用束搜索及其他搜索算法来生成更优的回答。
这里推荐《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters 》这篇论文。
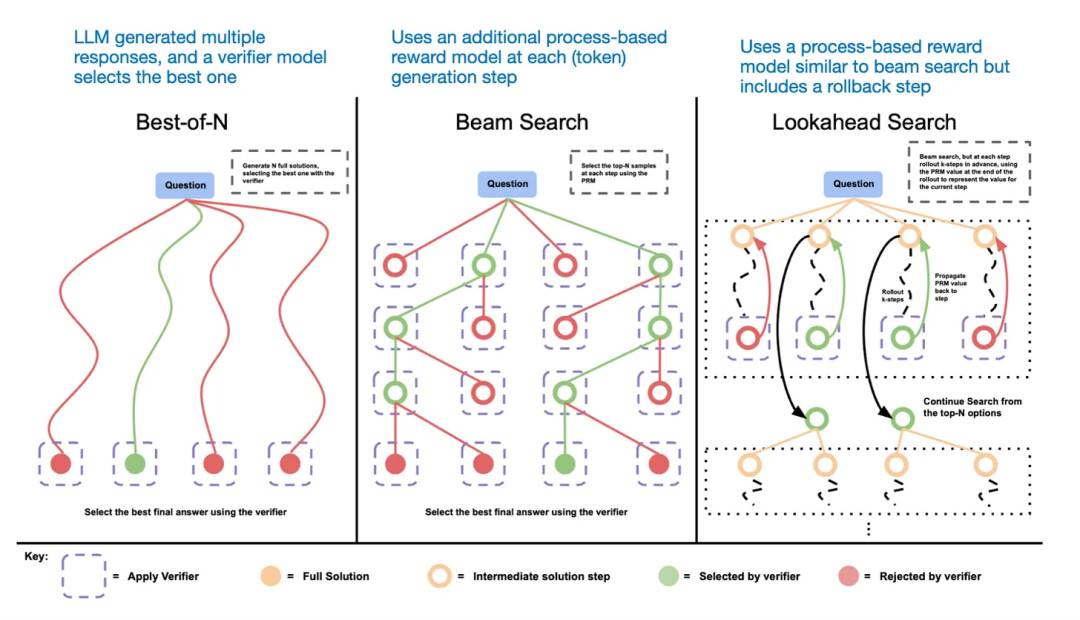
不同的基于搜索的方法依赖于基于过程奖励的模型来选择最佳答案。
DeepSeek R1技术报告称其模型并未采用推理时扩展技术。然而,这项技术通常在 LLM 之上的应用层实施,所以DeepSeek有可能在其应用程序中运用了该技术。
我推测 OpenAI 的 o1 和 o3 模型采用了推理时扩展技术,这就能解释为何与GPT - 4o这类模型相比,它们的使用成本相对较高。除了推理时扩展,o1和o3很可能是通过与DeepSeek R1类似的强化学习流程进行训练的。
2、纯强化学习 / Pure RL
DeepSeek R1论文中特别值得关注的一点,是他们发现推理能够作为一种行为从纯强化学习中涌现出来。下面我们来探讨这意味着什么。
如前文所述,DeepSeek开发了三种R1模型。第一种是DeepSeek - R1 - Zero,它构建于DeepSeek - V3基础模型之上。与典型的强化学习流程不同,通常在强化学习之前会进行监督微调(SFT),但DeepSeek - R1 - Zero完全是通过强化学习进行训练的,没有初始的监督微调/SFT阶段,如下图所示。
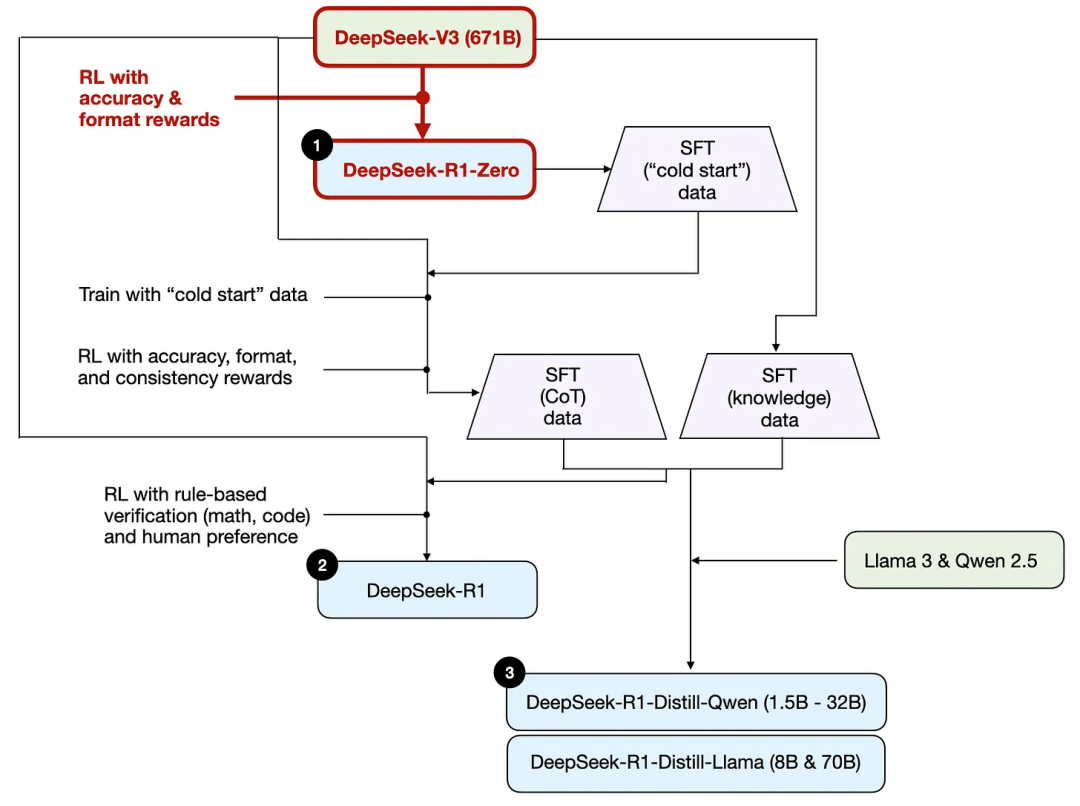
尽管如此,这种强化学习过程与常用于对LLM进行偏好微调的人类反馈强化学习(RLHF)方法类似。然而,如上文所述,DeepSeek - R1 - Zero 的关键区别在于,他们跳过了用于指令调整的监督微调(SFT)阶段。这就是为什么他们称之为 “纯” 强化学习 / Pure RL。
在奖励方面,他们没有使用基于人类偏好训练的奖励模型,而是采用了两种奖励类型:准确性奖励和格式奖励。
令人惊讶的是,这种方法足以让 LLM 演化出基本的推理技能。研究人员观察到了一个 aha moment,即模型开始在其回答中生成推理痕迹,尽管并没有对其进行明确的相关训练,如下图所示,出自 R1 技术报告。

虽然R1 - Zero并非最顶尖的推理模型,但如上图所示,它确实通过生成中间 “思考” 步骤展现出了推理能力。这证实了利用纯强化学习来开发推理模型是可行的,而且DeepSeek是首个展示(或至少是发表相关成果)这种方法的团队。
3、监督微调与强化学习(SFT + RL)
接下来看看DeepSeek的主打推理模型DeepSeek - R1的开发过程,它堪称构建推理模型的教科书。该模型在DeepSeek - R1 - Zero的基础上,融入了更多的监督微调(SFT)和强化学习(RL),以提升自身的推理性能。
需要注意的是,在强化学习之前加入监督微调阶段,这在标准的人类反馈强化学习(RLHF)流程中实属常见。OpenAI的o1很可能也是采用类似方法开发的。
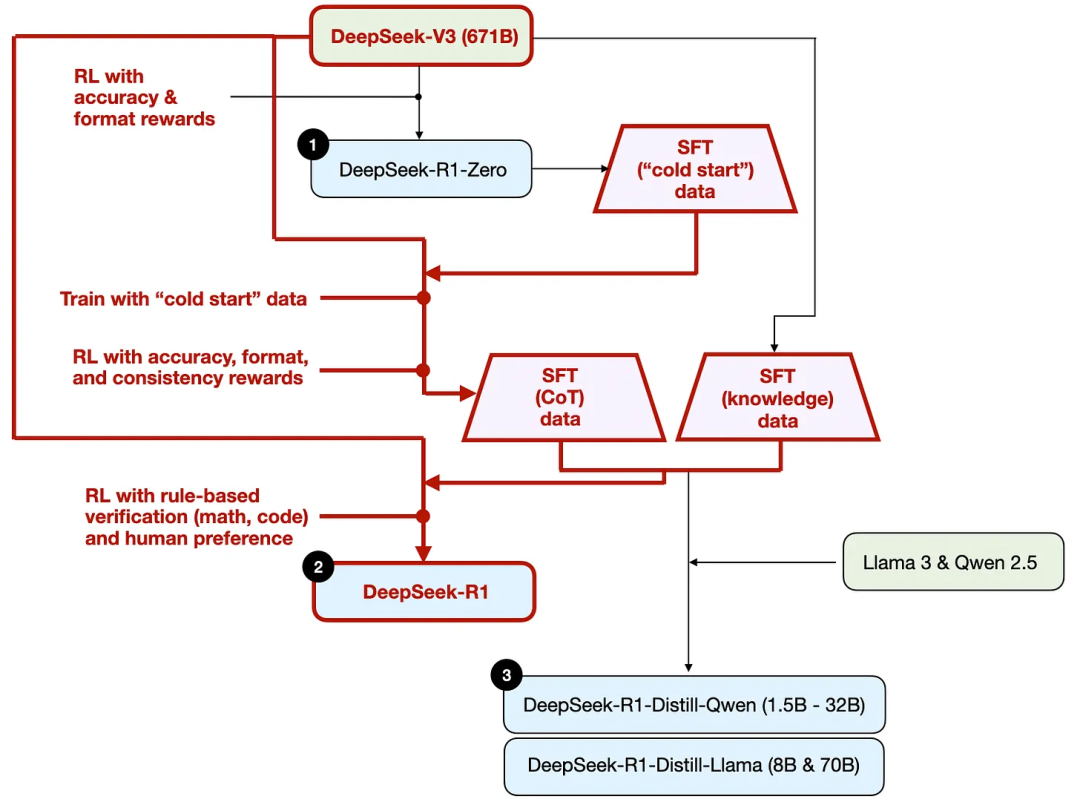
如上图所示,DeepSeek团队利用DeepSeek - R1 - Zero生成了他们所谓的“冷启动”监督微调(SFT)数据。“冷启动” 这一术语意味着,这些数据是由DeepSeek - R1 - Zero生成的,而该模型本身并未在任何监督微调数据上进行过训练。
利用这些冷启动SFT数据,DeepSeek首先通过指令微调来训练模型,随后进入另一个强化学习(RL)阶段。这个RL阶段沿用了DeepSeek - R1 - Zero的RL过程中所使用的准确性奖励和格式奖励。不过,他们新增了一致性奖励,以防止模型在回答中出现语言混用的情况,即模型在一次回答中切换多种语言。
在RL阶段之后,进入另一轮SFT数据收集。在此阶段,使用最新的模型检查点生成了60万个思维链(CoT)SFT示例(600K CoT SFT exmaples),同时利用DeepSeek - V3基础模型创建了额外20万个基于知识的SFT示例(200K knowledge based SFT examples)。
然后,这60万 + 20万个SFT样本被用于对DeepSeek - V3基础模型进行指令微调/instruction finetuning,之后再进行最后一轮RL。在这个阶段,对于数学和编程问题,他们再次使用基于规则的方法来确定准确性奖励,而对于其他类型的问题,则使用人类偏好标签。总而言之,这与常规的人类反馈强化学习(RLHF)非常相似,只是SFT数据中包含(更多)思维链示例。并且,RL除了基于人类偏好的奖励之外,还有可验证的奖励。
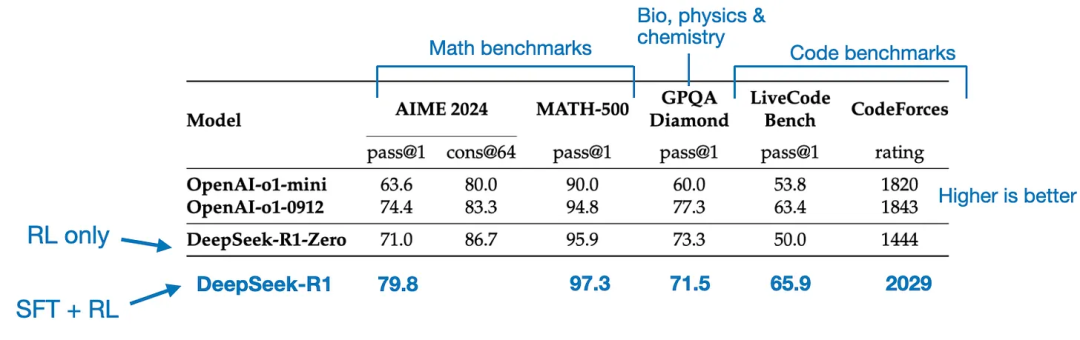
最终的模型DeepSeek - R1,由于额外的SFT和RL阶段,相比DeepSeek - R1 - Zero有显著的性能提升,如下表所示。
4、纯监督微调(SFT)与蒸馏
到目前为止,我们已经介绍了构建和改进推理模型的三种关键方法:
1/ 推理时扩展,这是一种无需对底层模型进行训练或以其他方式修改,就能提升推理能力的技术。
2/ Pure RL,如DeepSeek - R1 - Zero中所采用的纯强化学习(RL),它表明推理可以作为一种习得行为出现,无需监督微调。
3/ 监督微调(SFT)+ 强化学习(RL),由此产生了DeepSeek的推理模型DeepSeek - R1。
还剩下 - 模型 “蒸馏”。DeepSeek还发布了通过他们所谓的蒸馏过程训练的较小模型。在LLM的背景下,蒸馏并不一定遵循深度学习中使用的经典知识蒸馏方法。传统上,在知识蒸馏中,一个较小的 “学生” 模型会在较大 “教师” 模型的逻辑输出以及目标数据集上进行训练。
然而,这里的蒸馏是指在由较大的LLM生成的监督微调(SFT)数据集上,对较小的LLM进行指令微调/instruction finetuning,比如Llama 8B 和70B模型,以及Qwen 2.5B(0.5B - 32B)。具体来说,这些较大的 LLM 是DeepSeek - V3和DeepSeek - R1的一个中间检查点 / checkpoint。事实上,用于这个蒸馏过程的监督微调数据/SFT data,与上一节中描述的用于训练DeepSeek - R1的数据集是相同的。
为了阐明这个过程,我在下图中突出显示了蒸馏部分。
他们为什么要开发这些蒸馏模型?有两个关键原因:
1/ 更小的模型效率更高。这意味着它们的运行成本更低,而且还能在低端硬件上运行,对许多研究人员和爱好者来说特别有吸引力。
2/ 作为纯监督微调(SFT)的案例研究。这些蒸馏模型是一个有趣的基准,展示了在没有强化学习的情况下,纯监督微调能让模型达到何种程度。
下面的表格将这些蒸馏模型的性能与其他流行模型以及DeepSeek - R1 - Zero和DeepSeek - R1进行了对比。
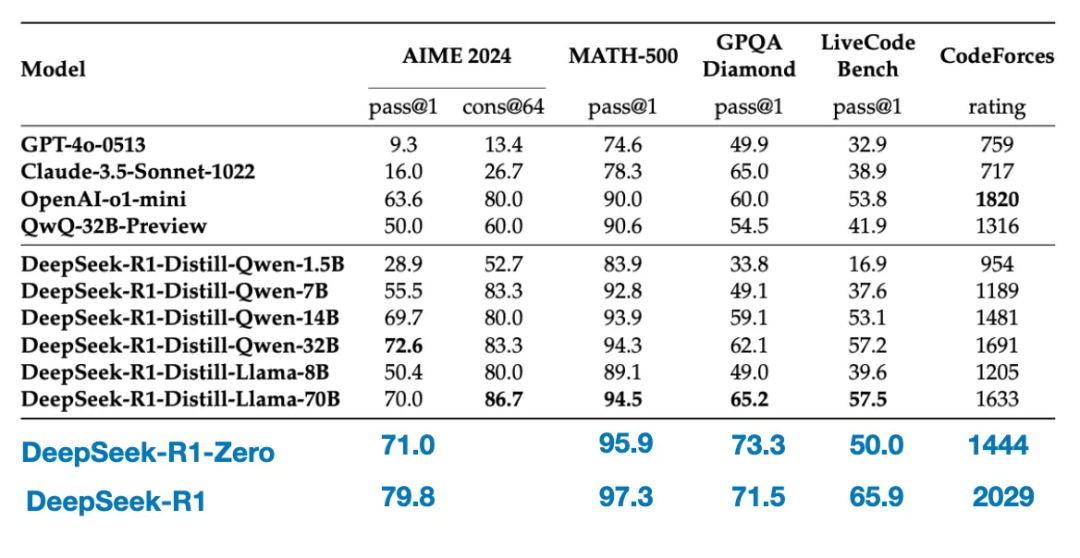
正如我们所见,尽管蒸馏模型比DeepSeek - R1小几个数量级,但它们明显比DeepSeek - R1 - Zero要强大得多,不过相对于DeepSeek - R1还是较弱。同样有趣的是,与o1 - mini相比,这些模型的表现也不错(怀疑o1 - mini本身可能是o1的类似蒸馏版本)。
还有一个有趣的对比值得一提。DeepSeek团队测试了DeepSeek - R1 - Zero中出现的突发推理行为是否也能出现在较小的模型中。为了对此进行研究,他们将DeepSeek - R1 - Zero中相同的纯强化学习方法直接应用于Qwen - 32B。
下面的表格总结了该实验的结果,其中QwQ - 32B - Preview是基于Qwen团队开发的Qwen 2.5 32B的参考推理模型。这一对比为仅靠纯强化学习是否能在比DeepSeek - R1 - Zero小得多的模型中诱导出推理能力提供了一些额外的见解。
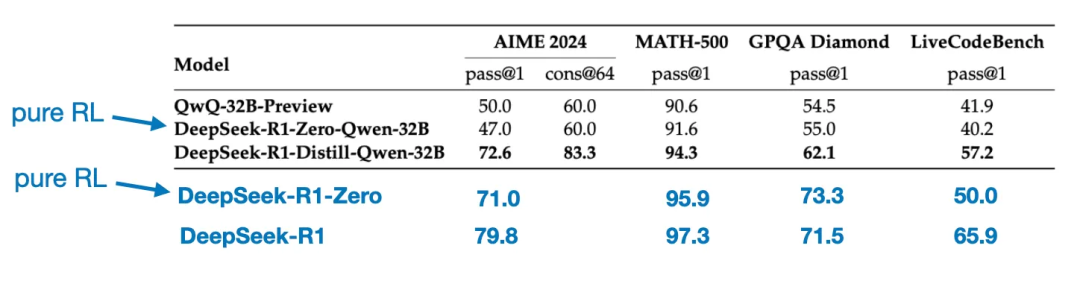
有趣的是,结果表明:对于较小的模型而言,蒸馏比纯强化学习要有效得多。这与一种观点相契合,即仅靠强化学习可能不足以在这种规模的模型中诱导出强大的推理能力,而在处理小模型时,基于高质量推理数据进行监督微调可能是一种更有效的策略。
结论
我们探讨了构建和提升推理模型的四种不同策略:
-
推理时扩展:无需额外训练,但会增加推理成本。随着用户数量或查询量的增长,大规模部署的成本会更高。不过,对于提升已有强大模型的性能而言,这仍是一种简单有效的方法。我强烈怀疑o1运用了推理时扩展,这也解释了为何与DeepSeek - R1相比,o1每生成一个token的成本更高。
-
纯强化学习 Pure RL:从研究角度来看很有趣,因为它能让我们深入了解推理作为一种涌现行为的过程。然而,在实际模型开发中,强化学习与监督微调相结合(RL + SFT)是更优选择,因为这种方式能构建出更强的推理模型。我同样强烈怀疑o1也是通过RL + SFT进行训练的。更确切地说,我认为o1起始于一个比DeepSeek - R1更弱、规模更小的基础模型,但通过RL + SFT和推理时扩展来弥补差距。
-
如上文所述,RL + SFT是构建高性能推理模型的关键方法。DeepSeek - R1为我们展示了实现这一目标的出色蓝本。
-
蒸馏:是一种颇具吸引力的方法,尤其适用于创建更小、更高效的模型。然而,其局限性在于,蒸馏无法推动创新或产生下一代推理模型。例如,蒸馏始终依赖于现有的更强模型来生成监督微调(SFT)数据。
接下来,我期待看到的一个有趣方向是将RL + SFT(方法3)与推理时扩展(方法1)相结合。这很可能就是OpenAI的o1正在做的,只不过o1可能基于一个比DeepSeek - R1更弱的基础模型,这也解释了为什么DeepSeek - R1在推理时性能出色且成本相对较低。





 个人中心
个人中心 退出登录
退出登录 ONDO0.39 3.84%
ONDO0.39 3.84%
 TRUMP5.13 1.88%
TRUMP5.13 1.88%
 SUI1.46 6.78%
SUI1.46 6.78%
 TON1.47 2.00%
TON1.47 2.00%
 TRX0.28 -0.17%
TRX0.28 -0.17%
 DOGE0.13 6.85%
DOGE0.13 6.85%
 XRP1.90 3.31%
XRP1.90 3.31%
 SOL125.31 3.46%
SOL125.31 3.46%
 BNB849.39 2.32%
BNB849.39 2.32%
 ETH2969.68 5.43%
ETH2969.68 5.43%
 BTC87230.50 1.90%
BTC87230.50 1.90%




 首页
首页 深潮精选
深潮精选 Research
Research 项目发现
项目发现 7x24h︎快讯
7x24h︎快讯 最新活动
最新活动
 分享至微信
分享至微信
 原文链接
原文链接 添加收藏
添加收藏 分享社交媒体
分享社交媒体 精选解读
精选解读
 原创
原创
 Monad 生态 Perp DEX LeverUp 代币 $LV 价格突破 $0.065,创历史新高
Monad 生态 Perp DEX LeverUp 代币 $LV 价格突破 $0.065,创历史新高





 扫码关注公众号
扫码关注公众号





