

DeepSeek không phải là hoàn hảo, quá trình huấn luyện tồn tại "lời nguyền độ sâu"
Tuyển chọn TechFlowTuyển chọn TechFlow
DeepSeek không phải là hoàn hảo, quá trình huấn luyện tồn tại "lời nguyền độ sâu"
Sự tồn tại của "lời nguyền độ sâu" đặt ra thách thức nghiêm trọng đối với việc huấn luyện và tối ưu hóa các mô hình ngôn ngữ lớn.
Các mô hình lớn hiệu suất cao thường cần hàng ngàn GPU và mất hàng tháng hoặc thậm chí lâu hơn để hoàn thành một lần huấn luyện. Khoản đầu tư tài nguyên khổng lồ này khiến mỗi tầng của mô hình đều phải được huấn luyện hiệu quả, nhằm đảm bảo sử dụng tối đa năng lực tính toán.
Tuy nhiên, các nhà nghiên cứu từ Đại học Công nghệ Đại Liên, Đại học Tây Hồ và Đại học Oxford khi nghiên cứu DeepSeek, Qwen, Llama và Mistral đã phát hiện ra rằng các tầng sâu của những mô hình này trong quá trình huấn luyện hoạt động không tốt, thậm chí có thể bị cắt tỉa hoàn toàn mà không ảnh hưởng đến hiệu suất mô hình.
Ví dụ, các nhà nghiên cứu đã thực hiện việc cắt tỉa từng lớp đối với mô hình DeepSeek-7B để đánh giá mức độ đóng góp của mỗi lớp vào hiệu suất tổng thể của mô hình. Kết quả cho thấy, việc loại bỏ các lớp sâu gần như không ảnh hưởng đến hiệu suất, trong khi loại bỏ các lớp nông sẽ làm hiệu suất giảm rõ rệt. Điều này cho thấy các lớp sâu của mô hình DeepSeek không học được các đặc trưng hữu ích một cách hiệu quả trong quá trình huấn luyện, còn các lớp nông lại đảm nhiệm phần lớn nhiệm vụ trích xuất đặc trưng.
Hiện tượng này được gọi là “lời nguyền độ sâu” (Curse of Depth), đồng thời các nhà nghiên cứu cũng đề xuất một phương pháp giải quyết hiệu quả — LayerNorm Scaling (tỷ lệ chuẩn hóa theo tầng).

Giới thiệu về lời nguyền độ sâu
Nguyên nhân gốc rễ của hiện tượng “lời nguyền độ sâu” nằm ở đặc điểm của Pre-LN. Pre-LN là một kỹ thuật chuẩn hóa được sử dụng rộng rãi trong các mô hình kiến trúc Transformer, thực hiện chuẩn hóa trên đầu vào của mỗi tầng thay vì trên đầu ra. Mặc dù cách chuẩn hóa này có thể ổn định quá trình huấn luyện mô hình, nhưng cũng gây ra một vấn đề nghiêm trọng: khi độ sâu mô hình tăng lên, phương sai đầu ra của Pre-LN tăng theo cấp số nhân.
Sự bùng nổ phương sai này khiến đạo hàm của các khối Transformer ở tầng sâu gần như trở thành ma trận đơn vị, làm cho các tầng này hầu như không đóng góp thông tin hữu ích nào trong quá trình huấn luyện. Nói cách khác, các tầng sâu trong quá trình huấn luyện biến thành ánh xạ đồng nhất, không thể học được các đặc trưng hữu ích.
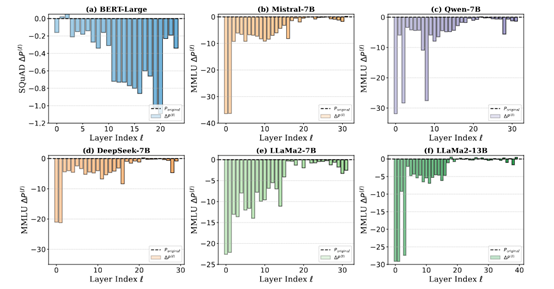
Sự tồn tại của “lời nguyền độ sâu” đặt ra thách thức nghiêm trọng cho việc huấn luyện và tối ưu hóa mô hình ngôn ngữ lớn. Trước tiên, việc huấn luyện không đủ ở các tầng sâu dẫn đến lãng phí tài nguyên. Trong quá trình huấn luyện mô hình ngôn ngữ lớn, thường cần rất nhiều tài nguyên tính toán và thời gian. Vì các tầng sâu không học được các đặc trưng hữu ích một cách hiệu quả, nên năng lực tính toán bị lãng phí đáng kể.
Tính vô hiệu của các tầng sâu hạn chế khả năng cải thiện thêm hiệu suất mô hình. Dù các tầng nông có thể đảm nhiệm phần lớn nhiệm vụ trích xuất đặc trưng, nhưng sự vô hiệu của các tầng sâu khiến mô hình không thể tận dụng lợi thế về độ sâu.
Hơn nữa, “lời nguyền độ sâu” còn gây khó khăn cho khả năng mở rộng mô hình. Khi quy mô mô hình tăng lên, tình trạng vô hiệu ở các tầng sâu càng trở nên nổi bật, khiến việc huấn luyện và tối ưu hóa mô hình ngày càng khó khăn. Ví dụ, khi huấn luyện các mô hình cực lớn, việc huấn luyện không đủ ở các tầng sâu có thể khiến tốc độ hội tụ của mô hình chậm lại, thậm chí không thể hội tụ.
Phương pháp giải quyết — LayerNorm Scaling
Tư tưởng cốt lõi của LayerNorm Scaling là kiểm soát chính xác phương sai đầu ra của Pre-LN. Trong một mô hình Transformer nhiều tầng, đầu ra của chuẩn hóa từng tầng sẽ được nhân với một hệ số thu phóng cụ thể. Hệ số này liên quan mật thiết đến độ sâu của tầng hiện tại, bằng nghịch đảo căn bậc hai của độ sâu tầng.
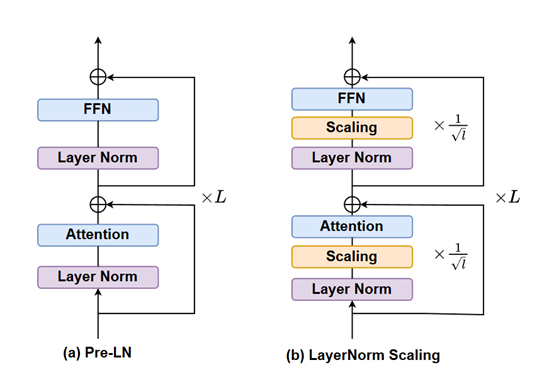
Để minh họa dễ hiểu, mô hình lớn giống như một tòa nhà cao tầng, mỗi tầng là một tầng lầu, còn LayerNorm Scaling giống như điều chỉnh tinh tế "mức năng lượng đầu ra" cho từng tầng.

Đối với các tầng thấp (tầng nông), hệ số thu phóng tương đối lớn, nghĩa là biên độ điều chỉnh đầu ra nhỏ hơn, có thể duy trì "năng lượng" tương đối mạnh; đối với các tầng cao (tầng sâu), hệ số thu phóng nhỏ hơn, do đó hiệu quả giảm "cường độ năng lượng" đầu ra ở các tầng sâu, tránh tích tụ quá mức phương sai.
Bằng cách này, phương sai đầu ra của toàn bộ mô hình được kiểm soát hiệu quả, không còn xảy ra tình trạng bùng nổ phương sai ở các tầng sâu. (Quá trình tính toán khá phức tạp, bạn đọc quan tâm có thể xem trực tiếp bài báo)
Xét từ góc độ huấn luyện mô hình, trong quá trình huấn luyện mô hình Pre-LN truyền thống, do phương sai tầng sâu không ngừng tăng, gradient trong quá trình lan truyền ngược bị ảnh hưởng lớn. Thông tin gradient ở các tầng sâu trở nên bất ổn, giống như khi chạy tiếp sức, cây gậy tiếp sức luôn rơi ở những chặng cuối, dẫn đến truyền thông tin không thông suốt.
Khiến các tầng sâu khó học được các đặc trưng hiệu quả trong quá trình huấn luyện, hiệu quả huấn luyện tổng thể của mô hình bị giảm sút nghiêm trọng. Trong khi đó, LayerNorm Scaling kiểm soát phương sai, ổn định dòng gradient.
Trong quá trình lan truyền ngược, gradient có thể truyền thuận lợi hơn từ tầng đầu ra đến tầng đầu vào của mô hình, mỗi tầng đều nhận được tín hiệu gradient chính xác và ổn định, từ đó cập nhật tham số và học tập hiệu quả hơn.
Kết quả thí nghiệm
Để kiểm chứng hiệu quả của LayerNorm Scaling, các nhà nghiên cứu đã tiến hành thử nghiệm rộng rãi trên các mô hình với quy mô khác nhau. Các thí nghiệm bao gồm các mô hình từ 130 triệu đến 1 tỷ tham số.
Kết quả thí nghiệm cho thấy, LayerNorm Scaling cải thiện đáng kể hiệu suất mô hình trong giai đoạn tiền huấn luyện, so với Pre-LN truyền thống, giảm độ khó hiểu (perplexity) và giảm số lượng token cần thiết cho huấn luyện.
Ví dụ, trên mô hình LLaMA-130M, LayerNorm Scaling giảm độ khó hiểu từ 26,73 xuống còn 25,76; trên mô hình LLaMA-1B với 1 tỷ tham số, độ khó hiểu giảm từ 17,02 xuống còn 15,71. Những kết quả này cho thấy LayerNorm Scaling không chỉ kiểm soát hiệu quả sự gia tăng phương sai ở các tầng sâu, mà còn cải thiện đáng kể hiệu quả và hiệu suất huấn luyện mô hình.
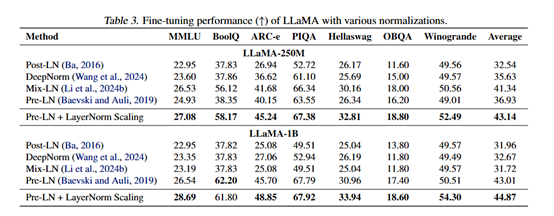
Các nhà nghiên cứu cũng đánh giá hiệu suất của LayerNorm Scaling trong giai đoạn tinh chỉnh giám sát. Kết quả thí nghiệm cho thấy LayerNorm Scaling vượt trội hơn các kỹ thuật chuẩn hóa khác trên nhiều nhiệm vụ phụ.
Ví dụ, trên mô hình LLaMA-250M, LayerNorm Scaling cải thiện hiệu suất nhiệm vụ ARC-e thêm 3,56%, hiệu suất trung bình trên tất cả các nhiệm vụ tăng 1,80%. Điều này cho thấy LayerNorm Scaling không chỉ thể hiện xuất sắc trong giai đoạn tiền huấn luyện mà còn cải thiện đáng kể hiệu suất mô hình trong giai đoạn tinh chỉnh.
Hơn nữa, các nhà nghiên cứu đã thay đổi phương pháp chuẩn hóa của mô hình DeepSeek-7B từ Pre-LN truyền thống sang LayerNorm Scaling. Trong suốt quá trình huấn luyện, khả năng học tập của các khối tầng sâu được cải thiện đáng kể, tích cực tham gia vào quá trình học của mô hình và đóng góp cho việc nâng cao hiệu suất. Mức độ giảm độ khó hiểu rõ rệt hơn và tốc độ giảm cũng ổn định hơn.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














