

DeepSeek는 완벽하지 않으며, 학습 과정에서 '깊이의 저주'가 존재한다
고성능 대규모 모델은 훈련 과정에서 수천 개의 GPU를 필요로 하며, 한 번의 훈련을 완료하는 데 수개월에서 그 이상의 시간이 소요된다. 이러한 막대한 자원 투입으로 인해 각 층이 모두 효율적으로 훈련되어야 비로소 컴퓨팅 자원을 최대한 활용할 수 있다.
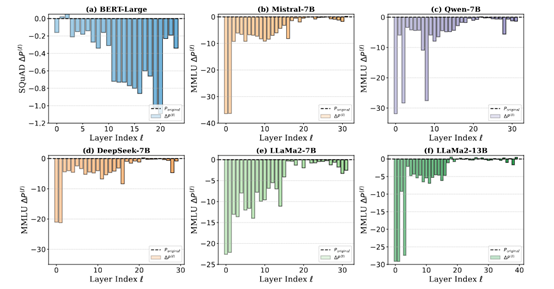
그러나 다롄이공대학, 시후대학, 옥스퍼드대학 등의 연구진들은 DeepSeek, Qwen, Llama 및 Mistral에 대한 연구를 통해 이들 모델의 깊은 층들이 훈련 중 성능이 좋지 않으며, 심지어 전체적으로 가지치기(pruning)해도 모델 성능에 영향을 주지 않는다는 사실을 발견했다.
예를 들어, 연구진은 DeepSeek-7B 모델에 대해 층별로 가지치기를 수행하여 각 층이 모델 전반의 성능에 미치는 기여도를 평가했다. 그 결과 깊은 층을 제거하더라도 성능에 거의 영향을 주지 않는 반면, 얕은 층을 제거하면 성능이 명확히 저하된다. 이는 DeepSeek 모델의 깊은 층들이 훈련 과정에서 유용한 특징을 효과적으로 학습하지 못했으며, 대부분의 특징 추출 작업은 얕은 층이 담당하고 있음을 보여준다.
이러한 현상을 "깊이의 저주(Curse of Depth)"라고 부르며, 연구진은 동시에 이를 해결할 수 있는 효과적인 방법으로 LayerNorm Scaling(층 정규화 스케일링)을 제안했다.

깊이의 저주 소개
"깊이의 저주" 현상의 근본 원인은 Pre-LN의 특성에 있다. Pre-LN은 트랜스포머 구조 모델에서 널리 사용되는 정규화 기술로, 출력이 아니라 각 층의 입력에서 정규화를 수행한다. 이 정규화 방식은 모델의 훈련 과정을 안정화시킬 수 있지만, 심각한 문제도 동반하는데, 바로 모델의 깊이가 증가함에 따라 Pre-LN의 출력 분산이 지수적으로 증가한다는 점이다.
이러한 분산의 폭발적 증가는 깊은 층의 트랜스포머 블록의 도함수가 단위행렬에 가까워지게 만들며, 결과적으로 이러한 층들이 훈련 과정에서 거의 유의미한 정보를 제공하지 못하게 된다. 즉, 깊은 층들이 훈련 중에 단순한 항등 매핑(identity mapping)이 되어 유용한 특징을 학습하지 못하는 것이다.
"깊이의 저주"는 대규모 언어 모델의 훈련 및 최적화에 심각한 도전을 야기한다. 우선, 깊은 층의 부족한 훈련으로 인해 자원 낭비가 발생한다. 대규모 언어 모델을 훈련할 때 일반적으로 막대한 컴퓨팅 자원과 시간이 필요하지만, 깊은 층이 유용한 특징을 효과적으로 학습하지 못하므로 계산 자원이 상당 부분 낭비된다.
또한 깊은 층의 비효율성은 모델 성능의 추가적인 향상을 제한한다. 얕은 층이 대부분의 특징 추출 작업을 수행할 수는 있지만, 깊은 층의 비효율성으로 인해 모델은 그 깊이의 장점을 충분히 활용하지 못한다.
더불어 "깊이의 저주"는 모델의 확장성에도 어려움을 초래한다. 모델 규모가 커질수록 깊은 층의 비효율성이 더욱 두드러져 모델의 훈련과 최적화가 더욱 어려워진다. 예를 들어 초대형 모델을 훈련할 때 깊은 층의 훈련 부족으로 인해 수렴 속도가 느려지거나 아예 수렴되지 않을 수도 있다.
해결 방법 — LayerNorm Scaling
LayerNorm Scaling의 핵심 아이디어는 Pre-LN 출력 분산을 정밀하게 제어하는 것이다. 다층 트랜스포머 모델에서 각 층의 정규화 출력값은 특정한 스케일링 계수(scaling factor)를 곱하게 되며, 이 스케일링 계수는 해당 층의 깊이와 밀접한 관련이 있으며, 층 깊이의 제곱근의 역수이다.
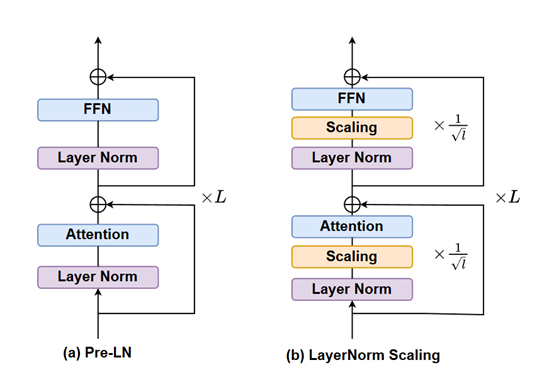
쉽게 이해하기 위해 예를 들면, 대규모 모델은 마치 고층 건물과 같고 각 층은 그 건물의 한 층을 의미하며, LayerNorm Scaling은 각 층의 "에너지 출력"을 정교하게 조절하는 것이다.

낮은 층(얕은 층)의 경우 스케일링 계수가 비교적 크므로 출력 조정 폭이 작아 상대적으로 강한 "에너지"를 유지할 수 있다. 반면 높은 층(깊은 층)의 경우 스케일링 계수가 작아 깊은 층의 출력 "에너지 강도"를 효과적으로 낮추고, 분산의 과도한 누적이 방지된다.
이 방식을 통해 전체 모델의 출력 분산이 효과적으로 제어되어 깊은 층에서의 분산 폭주 현상이 더 이상 발생하지 않는다. (전체 계산 과정은 다소 복잡하므로 관심 있는 독자는 논문을 직접 참고하기 바란다)
모델 훈련 관점에서 보면, 기존의 Pre-LN 모델 훈련에서는 깊은 층의 분산이 계속 커지면서 역전파 과정에서 그래디언트(gradient)가 크게 방해를 받는다. 깊은 층의 그래디언트 정보가 불안정해지는데, 이는 마치 계주 경기에서 리레이를 할 때 후반 구간에서 계속해서 계주봉이 떨어지는 것과 같아 정보 전달이 원활하지 못하다.
결과적으로 깊은 층이 훈련 중 유용한 특징을 학습하기 어려워지고, 모델 전체의 훈련 효과가 크게 저하된다. 반면 LayerNorm Scaling은 분산을 제어함으로써 그래디언트 흐름을 안정화시킨다.
역전파 과정에서 그래디언트가 출력층에서 입력층까지 더욱 원활하게 전달되며, 모든 층이 정확하고 안정적인 그래디언트 신호를 수신할 수 있으므로 파라미터 업데이트 및 학습을 보다 효과적으로 수행할 수 있다.
실험 결과
LayerNorm Scaling의 유효성을 검증하기 위해 연구진은 다양한 규모의 모델에서 광범위한 실험을 수행했다. 실험에는 1.3억 개에서 10억 개의 파라미터를 갖는 모델이 포함되었다.
실험 결과에 따르면, LayerNorm Scaling은 사전 훈련 단계에서 모델 성능을 현저히 향상시켰으며, 기존의 Pre-LN과 비교해 혼란도(perplexity)를 낮추고 훈련에 필요한 토큰 수를 줄였다.
예를 들어, LLaMA-130M 모델에서는 LayerNorm Scaling이 혼란도를 26.73에서 25.76으로 낮췄으며, 10억 개의 파라미터를 갖는 LLaMA-1B 모델에서는 17.02에서 15.71로 낮췄다. 이러한 결과는 LayerNorm Scaling이 깊은 층의 분산 증가를 효과적으로 억제할 뿐 아니라 모델의 훈련 효율성과 성능을 현저히 향상시킬 수 있음을 보여준다.
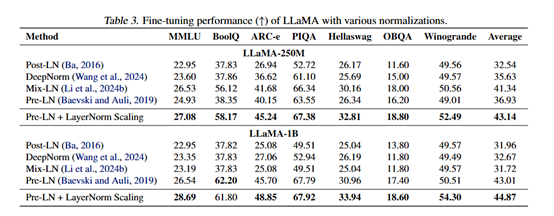
연구진은 또한 LayerNorm Scaling이 감독 미세 조정(supervised fine-tuning) 단계에서의 성능도 평가했다. 실험 결과에 따르면 LayerNorm Scaling은 여러 하류 작업에서 다른 정규화 기술보다 우수한 성능을 보였다.
예를 들어, LLaMA-250M 모델에서 LayerNorm Scaling은 ARC-e 작업에서 성능이 3.56% 향상되었으며, 모든 작업에서 평균 성능이 1.80% 향상되었다. 이는 LayerNorm Scaling이 사전 훈련 단계뿐 아니라 미세 조정 단계에서도 모델 성능을 현저히 향상시킬 수 있음을 나타낸다.
또한 연구진은 DeepSeek-7B 모델의 정규화 방식을 기존의 Pre-LN에서 LayerNorm Scaling으로 교체했다. 전체 훈련 과정에서 깊은 블록들의 학습 능력이 현저히 향상되어 적극적으로 모델 학습 과정에 참여하며 모델 성능 향상에 기여했다. 혼란도 감소 폭이 더욱 두드러졌으며 감소 속도도 더욱 안정적이었다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














