AI 데이터 폭증으로 '석유 위기' 발생, 콘텐츠 기업들은 이제 누워서 돈을 벌 수 있게 되었다
글: 장장
편집: 만만저우
ChatGPT의 등장과 Midjourney의 폭발적인 채택은 AI가 대규모로 활용되는 첫 번째 사례를 만들어냈으며, 이는 곧 대규모 모델(Large Model)의 보급을 의미한다.
이른바 대규모 모델이란 방대한 수의 파라미터와 복잡한 구조를 가진 머신러닝 모델을 말하며, 방대한 데이터를 처리하고 다양한 복잡한 작업을 수행할 수 있다.
01 AI 데이터 저작권 분쟁
현재의 AI 대규모 모델을 자동차에 비유한다면, 원시 데이터는 석유 원료에 해당된다. 어찌됐든 우선 AI 모델은 충분한 '원유'를 필요로 한다.
AI 기업들의 '원유' 공급원은 주로 다음과 같은 몇 가지 유형으로 나뉜다:
-
위키피디아, 블로그, 포럼, 뉴스 정보 등 인터넷상에서 공개되고 무료로 이용 가능한 데이터;
-
오래된 뉴스 매체 및 출판사;
-
대학 등의 연구기관;
-
모델을 사용하는 C단말 사용자.
현실 세계의 석유 소유권은 이미 성숙한 법적 규제가 존재하지만, AI라는 아직 미명확한 영역에서는 '원유' 채굴권이 여전히 명확하지 않아 이로 인한 분쟁이 끊이지 않고 있다.
최근 들어 여러 대형 음반사들이 AI 음악 제작 회사인 Suno와 Udio를 상대로 저작권 침해 혐의로 소송을 제기했다. 이 소송은 지난해 12월 뉴욕타임스(NYT)가 OpenAI를 상대로 제기한 소송과 유사하다.

이미지 출처: Billboard
2023년 7월, 일부 작가들이 OpenAI를 상대로 소송을 제기하며 ChatGPT가 저작권 보호를 받는 콘텐츠를 기반으로 저자의 작품 요약을 생성했다고 주장했다.
같은 해 12월에는 마이크로소프트와 OpenAI를 상대로 NYT도 유사한 저작권 침해 소송을 제기했으며, 두 회사가 자사의 콘텐츠를 사용해 AI 챗봇을 훈련시켰다고 주장했다.
또한 캘리포니아주에서는 집단 소송이 제기되었는데, OpenAI가 사용자 동의 없이 인터넷에서 개인 정보를 수집해 ChatGPT 훈련에 사용했다고 주장했다.
결국 OpenAI는 이 소송에 대해 책임을 지지 않았다. 그들은 NYT의 주장을 인정하지 않으며, NYT가 언급한 문제를 재현할 수 없다고 밝혔다. 더 중요한 점은,所谓 NYT가 제공한 데이터가 OpenAI 입장에서는 그리 중요하지 않다는 것이다.

출처:
https://openai.com/index/openai-and-journalism/
OpenAI에게 이번 사건이 준 가장 큰 교훈은 바로 데이터 공급업체와의 관계를 잘 다루고, 양측의 권리와 책임을 명확히 하는 것이었다. 그래서 최근 1년간 OpenAI가 The Atlantic, Vox Media, News Corp, Reddit, Financial Times, Le Monde, Prisa Media, Axel Springer, American Journalism Project 등 다양한 데이터 공급업체와 파트너십을 맺는 모습을 볼 수 있었다.
앞으로 OpenAI는 이러한 언론 매체들의 데이터를 정당하게 사용하게 될 것이며, 반면 이 매체들도 OpenAI의 기술을 자사 제품에 통합할 예정이다.
02 AI가 콘텐츠 플랫폼 수익화를 추진
그러나 OpenAI가 데이터 공급업체와 협력 관계를 맺게 된 근본적인 이유는 단순히 소송에 대한 두려움 때문이 아니라, 머신러닝이 직면하게 될 데이터 고갈 문제 때문이다. MIT 등의 연구진은 한 연구를 통해 머신러닝 데이터셋이 2026년 이전에 모든 '고품질 언어 데이터'를 소진할 가능성이 있다고 추정했다.
따라서 '고품질 데이터'는 OpenAI와 Google 같은 모델 제조사들에게 매우 소중한 자산이 되었으며, 콘텐츠 기업과 AI 모델 업체 간의 협력이 잦아지면서 수익 창출이 쉬워지는 시대가 열렸다.
전통 미디어 플랫폼 Shutterstock은 Meta, Alphabet, Amazon, Apple, OpenAI, Reka 등 여러 AI 기업들과 차례로 협력 관계를 맺었으며, 2023년 AI 모델에 콘텐츠 라이선스를 제공함으로써 연간 수입을 1.04억 달러까지 끌어올렸고, 2027년에는 2.5억 달러의 수입을 올릴 것으로 예상된다. Reddit는 구글에 콘텐츠 저작권을 라이선스하여 연간 최대 6천만 달러의 수익을 올리고 있으며, 애플 역시 주요 뉴스 매체들과 협력을 모색하며 최소 연간 5천만 달러 이상의 저작권료를 지불하려 하고 있다. 콘텐츠 기업이 AI 기업으로부터 받는 저작권료는 연평균 450%의 속도로 급증하고 있다.

이미지 출처: CX Scoop
지난 몇 년간 스트리밍 외의 콘텐츠 수익화는 어려웠으며, 이는 콘텐츠 산업의 오랜 골칫거리였다. 인터넷 창업 시대와 비교하면, AI의 등장은 콘텐츠 산업에 더 큰 가능성과 강한 수익 기대감을 안겨주고 있다.
03 고품질 데이터 여전히 부족
물론 어떤 콘텐츠라도 AI의 요구에 부합하는 것은 아니다.
앞서 언급한 OpenAI와 뉴욕타임스의 논쟁에서 또 다른 핵심은 데이터의 질이다. 원유에서 석유를 정제하려면 원료 자체의 질이 좋아야 하며, 동시에 정제 기술 또한 뛰어나야 한다.
OpenAI는 특별히 뉴욕타임스의 콘텐츠가 자사 모델 훈련에 어떠한 중대한 기여도 하지 않았다고 강조했다. 매년 수천만 달러를 Shutterstock에 직접 지불하는 OpenAI 입장에서, 시의성에 의존하는 뉴욕타임스와 같은 글쓰기 중심의 미디어는 AI 시대의 주인공이 아니다. AI는 더 깊이 있고 독특한 데이터를 필요로 한다.
고품질 데이터는 너무나 드물기 때문에, AI 기업들은 이제 '정제 기술'과 '원스톱 애플리케이션' 개발에도 집중하고 있다.
6월 25일, OpenAI는 실시간 분석 데이터베이스 기업 Rockset을 인수했다. 이 회사는 실시간 데이터 색인 및 조회 기능을 제공하며, OpenAI는 자사 제품에 Rockset의 기술을 통합해 데이터의 실시간 활용 가치를 높일 계획이다.

이미지 출처: DePIN Scan
Rockset 인수를 통해 OpenAI는 AI가 실시간 데이터를 더 잘 활용하고 접근할 수 있도록 할 계획이다. 이를 통해 OpenAI의 제품은 실시간 추천 시스템, 동적 데이터 기반 챗봇, 실시간 모니터링 및 알림 시스템 등 보다 복잡한 애플리케이션을 지원할 수 있게 된다.
Rocket은 OpenAI 내부의 '석유 정제 부문'으로, 일반 데이터를 곧바로 고품질 데이터로 전환한다.
04 창작자의 데이터 권리 확보는 망상인가?
인터넷 미디어 플랫폼(Facebook, Reddit 등)의 데이터는 대부분 UGC(사용자 생성 콘텐츠)에서 비롯된다. 많은 플랫폼이 AI 기업에 높은 데이터 사용료를 받는 동시에, 사용자 이용 약관에 '플랫폼이 사용자 데이터를 AI 모델 훈련에 사용할 권한을 가진다'는 조항을 조용히 추가하고 있다.
비록 이용 약관에 AI 모델 훈련 관련 권한이 명시되어 있지만, 많은 창작자들은 자신이 생산한 콘텐츠가 구체적으로 어떤 모델에 사용되고 있는지, 유료로 사용되고 있는지도 모르며, 본인이 누려야 할 권익을 전혀 얻지 못하고 있다.
올해 2월 Meta의 분기 실적 발표 컨퍼런스콜에서, 찰스버그는 Facebook과 Instagram의 사진들을 자사의 AI 생성 도구 훈련에 사용하겠다고 명확히 밝혔다.
보고에 따르면 Tumblr도 OpenAI 및 Midjourney와 비밀리에 콘텐츠 라이선스 계약을 체결했지만, 구체적인 내용은 공개하지 않았다.
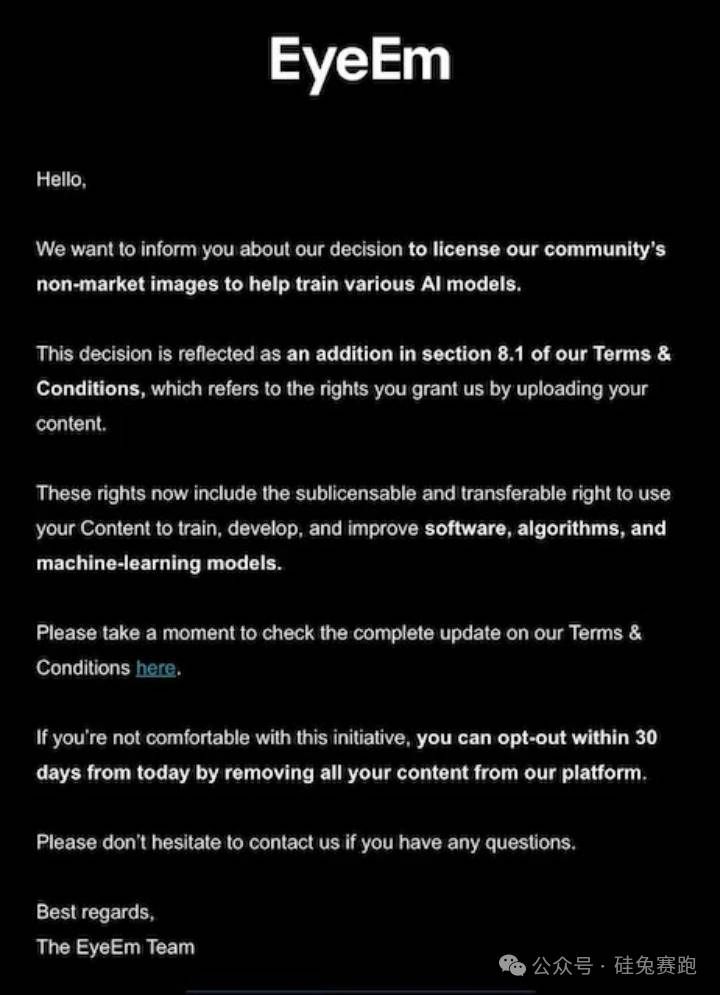
이미지 라이브러리 플랫폼 EyeEm의 창작자들은 최근 한 통지를 받았는데, 게시한 사진들이 AI 모델 훈련에 사용될 수 있다고 알려왔다. 통지문에는 사용자가 이를 거부하고 서비스를 사용하지 않을 수 있다고 언급했지만, 보상 정책에 대해서는 아직 언급하지 않았다. EyeEm의 모회사 Freepik은 로이터통신에 자사가 보유한 2억 장의 이미지 대부분을 두 군데의 대형 기술 기업에 라이선스하였으며, 이미지당 약 3센트의 가격을 책정했다고 밝혔다. CEO 호아킨 쿠엥카 아벨라(Joaquin Cuenca Abela)는 유사한 거래가 추가로 5건 진행 중이라고 언급했으나, 구매자 신원은 공개하지 않았다.
Getty Images, Adobe, Photobucket, Flickr, Reddit 등 UGC 중심의 콘텐츠 플랫폼들은 모두 유사한 문제에 직면해 있다. 거대한 데이터 수익화의 유혹 앞에서 플랫폼은 사용자의 콘텐츠 소유권을 무시하고 데이터를 묶어 AI 모델 기업에 판매하고 있는 실정이다.
이 모든 과정은 어둠 속에서 진행되며, 창작자는 아무런 반박 기회조차 없다. 심지어 많은 창작자들은 먼 훗날, 자신과 유사한 스타일의 작품이 어떤 AI 모델에서 생성되는 것을 보고서야, 자신의 작품이 어느 순간 플랫폼을 통해 AI 기업에 팔렸음을 의심하게 될지도 모른다.
창작자의 데이터 권리와 수익 보호 문제를 해결하기 위해 Web3가 좋은 선택이 될 수 있다. AI 기업들이 미국 증시에서 연일 신고점을 경신할 때, 웹3 기반의 AI 관련 암호화폐도 함께 급등하고 있다. 블록체인은 탈중앙화와 위변조 불가능한 특성 덕분에 창작자의 권리를 보호하는 데 있어 천부적인 장점이 있다.
이미지와 영상과 같은 미디어 콘텐츠는 2021년의 호황기에 이미 블록체인에 대규모로 연결되는 상용화가 이루어졌으며, 소셜 플랫폼의 UGC 콘텐츠도 조용히 블록체인에 연결되고 있다. 동시에 많은 웹3 기반 AI 모델 플랫폼들이 모델 훈련에 기여하는 일반 사용자들에게 보상을 제공하고 있는데, 데이터 소유자뿐 아니라 훈련 참여자들 모두에게 인센티브가 주어지고 있다.
AI 모델의 지수적 발전은 데이터 권리 확보에 대한 더 큰 요구를 만들고 있다. 창작자들은 스스로 질문해야 한다. 왜 내 작품이 나의 동의 없이 AI 모델 기업에 이미지당 5센트에 팔릴 수 있는가? 왜 이 모든 과정에서 나는 전혀 알지 못하며, 어떠한 수익도 얻을 수 없는가?
미디어 플랫폼이 일시적 이득을 위해 생태계를 파괴하더라도 AI 모델 기업의 데이터 불안을 해소할 수 없다. 고품질 데이터의 대량 생산을 위한 전제는 바로 데이터 권리의 확립이며, 창작자, 플랫폼, AI 모델 기업 간의 합리적인 이익 배분이어야 한다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News