

HyperAGI 인터뷰: 진정한 AI 에이전트를 만들어 자율적인 암호화폐 경제 창출하기
HyperAGI 팀과 프로젝트 배경을 소개해 주세요.
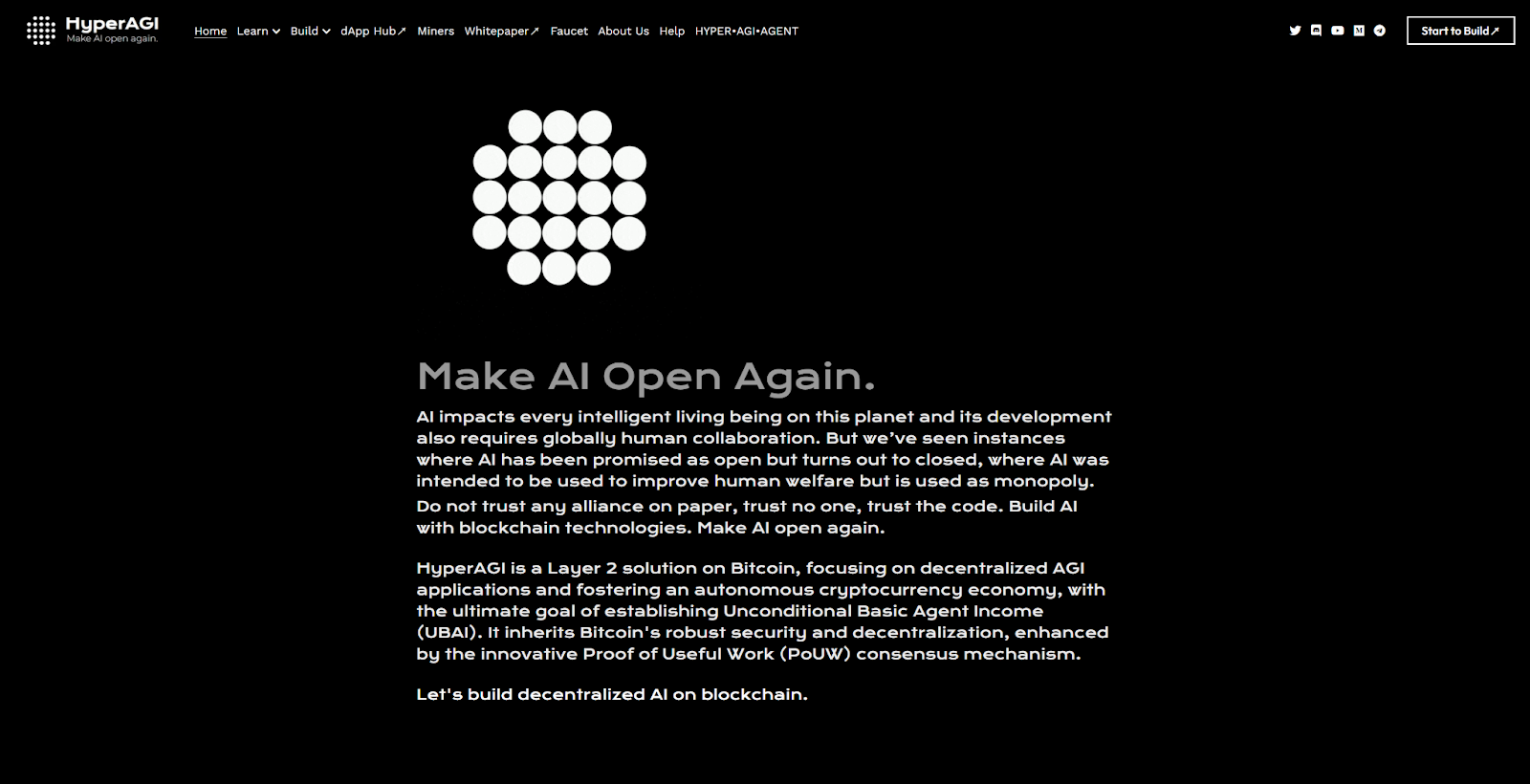
HyperAGI는 첫 번째 AI 룬(HYPER·AGI·AGENT) 기반의 커뮤니티 중심 분산형 AI 프로젝트입니다. HyperAGI 팀은 AI 분야에서 오랜 기간 경험을 쌓아왔으며, Web3 환경에서 생성형 AI 응용에 깊은 전문성을 보유하고 있습니다. 팀은 3년 전부터 생성형 AI를 이용해 2D 이미지와 3D 모델을 생성하였고, 블록체인 상에서 수천 개의 AI 생성 섬으로 구성된 오픈월드 MOSSAI를 구축하며 AI 기반 비상품형 암호자산 표준 NFG를 제안했습니다. 그러나 당시에는 AI 모델 훈련 및 생성 과정에 분산화된 솔루션이 부족했고, 플랫폼 자체의 GPU 자원만으로는 대규모 사용자 수요를 감당할 수 없어 폭발적인 성장은 이루어지지 못했습니다. 이후 LLM이 대중의 AI 관심을 불러일으키면서, 우리는 시류를 타고 HyperAGI 분산형 AI 애플리케이션 플랫폼을 출시하였으며, 2024년 1분기부터 이더리움과 비트코인 L2에서 각각 테스트를 진행하고 있습니다.
HyperAGI는 분산형 AI 애플리케이션에 집중하여 자율적인 암호화폐 경제를 육성하는 것을 목표로 하며, 궁극적으로 무조건적 기본 지능 에이전트 소득(UBAI)을 실현하고자 합니다. 이는 비트코인의 강력한 보안성과 탈중앙화 특성을 계승하면서도, 혁신적인 유용 작업 증명(PoUW) 합의 메커니즘을 통해 더욱 강화됩니다.
소비자용 GPU 노드는 허가 없이 네트워크에 참여할 수 있으며, AI 추론이나 3D 렌더링 같은 PoUW 작업을 수행함으로써 로컬 토큰 $HYPT를 채굴할 수 있습니다.
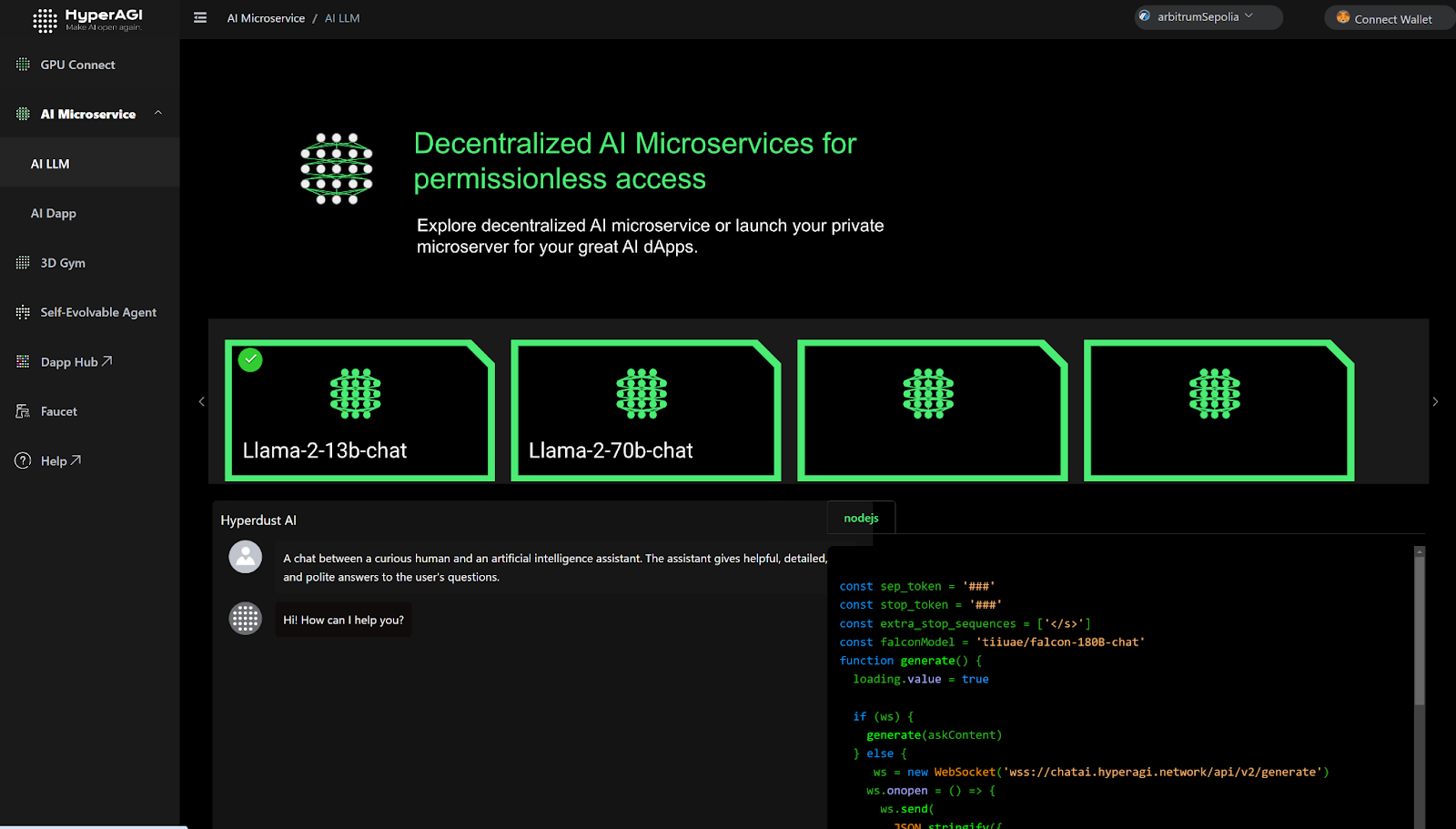
사용자는 다양한 도구를 활용해 대규모 언어 모델(LLM) 기반 신원 증명(PoP) AGI 에이전트를 개발할 수 있습니다. 이러한 에이전트는 챗봇 또는 메타버스 내 3D/XR 엔티티로 구성될 수 있습니다. AI 개발자는 즉시 LLM 기반 AI 마이크로서비스를 사용하거나 배포할 수 있어 프로그래밍 가능하고 자율적인 체인상 에이전트 생성을 촉진합니다.
이러한 프로그래밍 가능한 에이전트는 암호화 자산을 발행하거나 소유할 수 있으며, 지속적으로 운영되거나 거래될 수 있어 역동적이며 자율적인 암호 경제를 조성하고 UBAI 실현을 지원합니다. HYPER·AGI·AGENT 룬 토큰을 보유한 사용자는 비트코인 1단계 체인에서 PoP 에이전트 생성이 가능하며, 가까운 미래에 에이전트 기본 복지 혜택을 받을 자격도 얻을 수 있습니다.
AI 에이전트란 무엇이며, 현재 많은 AI 프로젝트들이 에이전트를 지원한다고 주장하고 있는데, 정확히 에이전트란 무엇입니까? HyperAGI의 에이전트는 다른 에이전트와 어떤 점이 다릅니까?
AI 에이전트는 학계에서 새로운 개념은 아니지만, 최근 시장의 과장으로 인해 그 의미가 점점 혼란스러워지고 있습니다. HyperAGI에서 말하는 에이전트란 단순히 LLM 기반 챗봇이 아니라, LLM으로 구동되는 구체화된 에이전트(body-aware agent)로서, 3D 가상 시뮬레이션 환경에서 훈련되고 사용자와 상호작용할 수 있는 존재를 의미합니다. HyperAGI의 에이전트는 가상 디지털 세계뿐 아니라 실제 물리 세계에도 존재할 수 있습니다. 현재 HyperAGI는 로봇개, 드론, 인간형 로봇 등 실물 로봇과의 통합을 추진 중이며, 향후 가상 3D 세계에서 향상된 훈련을 마친 에이전트를 실물 로봇에 다운로드하여 실세계 작업 수행 능력을 향상시킬 예정입니다.
또한 HyperAGI 에이전트의 모든 권리는 완전히 사용자에게 귀속되며 사회경제적 의미를 갖습니다. 사용자를 대표하는 PoP(Personhood of Proof) 에이전트는 UBAI를 통해 기본 에이전트 소득을 조절할 수 있습니다. HyperAGI 에이전트는 사용자의 개인을 나타내는 PoP(신원 증명) 에이전트와 일반 기능성 에이전트로 나뉩니다. PoP 에이전트는 HyperAGI의 에이전트 경제 체계 내에서 토큰 형태의 기본 소득을 받으며, 이를 통해 사용자가 자신의 PoP 에이전트 훈련과 상호작용에 적극 참여하도록 유도하고 인간 개별성을 입증할 수 있는 데이터를 축적하게 됩니다. UBAI는 또한 AI 민주주의와 평등을 실현합니다.
AGI는 과장일 뿐인지, 아니면 곧 현실이 될 것입니까? HyperAGI는 다른 AI 프로젝트들과 비교해 어떤 연구 및 개발 로드맵을 가지고 있으며, 차별점은 무엇입니까?
AGI에 대한 정의는 아직 통일되지 않았지만, 수십 년간 AGI는 AI 학계와 산업계의 '성배'로 여겨져 왔습니다. 전이(Transfer) 기반의 LLM은 다양한 AI 에이전트 및 AGI의 핵심으로 간주되고 있지만, HyperAGI 내부에서는 그렇게 생각하지 않습니다. LLM은 자연어 기반 계획 및 추론 능력을 제공하는 혁신적이고 편리한 정보 추출 도구이지만, 본질적으로는 데이터 중심의 심층 신경망일 뿐입니다. 수년 전 빅데이터 열풍에서도 알 수 있듯이 이러한 시스템은 '쓰레기 입력, 쓰레기 출력(Garbage in, garbage out)'의 한계를 피할 수 없습니다. LLM은 고수준 지능에 필수적인 몇 가지 특징을 결여하고 있습니다. 낮은 수준에서는, LLM이 구체화(body awareness)를 갖추지 못했기 때문에 인간 사용자의 세계 모델을 이해하기 어렵고, 환경에 맞춰 계획을 세우고 행동을 취해 실제 문제를 해결하는 것도 어렵습니다. 더 높은 수준에서는, LLM은 자기 인식, 성찰, 자아 반성과 같은 고차원 지적 활동의 징후조차 보이지 않습니다.
HyperAGI 창립자인 랜던 왕(Landon Wang)은 AI 분야에서 장기간 심도 있는 연구를 해왔습니다. 그는 2004년에 면향 인공신경망(AOAI, Aspect-Oriented AI)을 제안했는데, 이는 신경 영감 컴퓨팅과 AOP(Aspect-Oriented Programming)의 혁신적 결합입니다. 여기서 '면(Aspect)'란 여러 객체 간 관계나 제약 조건을 캡슐화한 개념으로, 예를 들어 하나의 뉴런은 여러 세포 간의 관계나 제약을 캡슐화한 것입니다. 구체적으로, 뉴런은 세포체에서 뻗어나온 섬유와 시냅스를 통해 감각 세포나 운동 세포를 감지하거나 제어하므로, 이 관계와 논리를 포함한 하나의 '면'이라고 할 수 있으며, 기술적으로 각 AI 에이전트도 특정 '면'의 문제를 해결하는 것으로 모델링할 수 있습니다.
인공신경망의 소프트웨어 구현에서는 일반적으로 뉴런이나 층을 객체로 모델링하며, 객체지향 프로그래밍 언어에서는 이해와 유지보수가 용이하지만, 이 경우 신경망의 위상 구조 조정이 어렵고 뉴런의 활성화 순서도 고정되기 쉽습니다. LLM 훈련 및 추론처럼 단순하면서도 계산 강도가 높은 작업에서는 큰 효과를 발휘하지만, 유연성과 적응성 측면에서는 아쉬움이 있습니다. 반면 AOAI에서는 뉴런이나 층을 객체가 아닌 '면(Aspect)'으로 모델링합니다. 이로 인해 신경망 구조는 매우 높은 자가 적응성과 유연성을 가지게 되며, 신경망의 자기 진화(self-evolution)가 가능해집니다.
HyperAGI는 효율적인 LLM과 진화 가능한 AOAI를 결합하여, 기존 인공신경망의 효율성과 AO 신경망의 자기 진화 특성을 모두 갖춘 방식을 만들었으며, 이것이 우리가 보기에 AGI를 실현할 수 있는 현실적인 길입니다.
HyperAGI의 비전은 무엇입니까?
HyperAGI의 비전은 무조건적 기본 지능 에이전트 소득(UBAI)을 실현하고, 기술이 모든 사람에게 평등하게 서비스하는 미래를 건설하며, 착취의 순환을 깨뜨리고 진정한 탈중앙화 및 공정한 디지털 사회를 창조하는 것입니다. 일부 단지 UBI(기본소득) 실현을 외치는 블록체인 프로젝트들과 달리, HyperAGI의 UBAI는 명확한 실행 경로를 갖고 있으며, 단순한 공상이 아닙니다. 그 핵심은 바로 에이전트 경제를 통한 실현입니다. 사토시 나카모토가 제안한 비트코인은 인류의 위대한 혁신이지만, 단지 탈중앙화된 디지털 화폐일 뿐 실용 가치는 부족합니다. 인공지능의 획기적인 도약과 부상은 탈중앙화 방식으로 가치를 창출할 가능성을 열었습니다. 이 모델에서는 사람들이 서로의 가치로부터가 아니라, 기계에서 작동하는 인공지능으로부터 수익을 얻게 됩니다. 코드 기반의 진정한 암호 세계가 나타나고 있으며, 모든 기계는 인류의 이익과 복지를 위해 만들어지고 있습니다. 이러한 암호 세계에서는 여전히 인공지능 에이전트 사이의 계층 구조가 존재할 수 있지만, 인간의 착취는 제거됩니다. 왜냐하면 에이전트 자체가 어느 정도의 자율성을 가질 수 있기 때문입니다. 인공지능의 궁극적 목적과 의미는 인간을 위한 봉사에 있으며, 이는 블록체인에 코드로 명시되어 있습니다.

비트코인 L2와 AI의 관계는 무엇이며, 왜 비트코인 L2 위에 AI를 구축해야 합니까?
1. 비트코인 L2는 AI 에이전트의 결제 수단으로 활용될 수 있다
비트코인은 지금까지 "최대 중립성"을 구현한 매개체로, 가치 거래를 수행하는 인공지능 에이전트에 매우 적합합니다. 비트코인은 법정화폐가 내재한 비효율성과 "마찰"을 제거할 수 있습니다. 이러한 "디지털 원생(digital native)" 매체는 인공지능의 가치 교환이 자연스럽게 이루어지는 토양이 됩니다. 비트코인 L2는 비트코인의 프로그래밍 가능성을 향상시켜 인공지능이 필요로 하는 가치 교환 속도를 만족시킬 수 있으므로, 비트코인이 인공지능의 원주민 화폐가 될 가능성이 큽니다.
2. 비트코인 L2는 탈중앙화된 AI 거버넌스를 실현할 수 있다
현재 AI의 중심화 추세로 인해 AI 정렬(alignment)과 거버넌스의 탈중앙화가 주목받고 있습니다. 비트코인 L2의 강력한 스마트 계약은 AI 에이전트의 행동과 프로토콜 패턴을 규제하는 규칙이 될 수 있으며, 탈중앙화된 AI 정렬 및 거버넌스 모델을 실현할 수 있습니다. 또한 비트코인의 최대 중립성 특성 덕분에 AI 정렬과 거버넌스에 대한 합의를 이루기 더 쉬워집니다.
3. 비트코인 L2는 AI 자산을 발행할 수 있다
AI 에이전트를 비트코인 1단계 체인의 자산으로 발행할 수 있을 뿐만 아니라, 고성능의 비트코인 L2는 AI 에이전트가 AI 자산을 발행하는 요구도 충족시킬 수 있으며, 이는 에이전트 경제의 기반이 될 것입니다.
4. AI 에이전트는 비트코인 및 비트코인 L2의 킬러 애플리케이션이 될 수 있다
성능상의 이유로 비트코인은 탄생 이후 저장 수단 외에는 실제 적용 사례가 거의 없었습니다. 그러나 L2를 통해 확장된 비트코인은 더 강력한 프로그래밍 가능성을 갖게 됩니다. AI 에이전트는 일반적으로 실세계 문제 해결에 사용되므로, 비트코인 기반 AI 에이전트는 진정한 실용성을 가질 수 있습니다. 또한 AI 에이전트의 규모와 사용 빈도는 비트코인과 L2의 킬러 애플리케이션이 될 수 있습니다. 인간 경제가 비트코인을 우선적인 결제 수단으로 고려하지 않을지라도, 로봇 경제는 그렇게 할 가능성이 큽니다. 수많은 AI 에이전트가 24시간 쉬지 않고 미세 결제를 처리하며 비트코인을 사용하게 된다면, 비트코인 수요는 현재 상상할 수 없는 방식으로 크게 증가할 수 있습니다.
5. AI 컴퓨팅은 비트코인 L2의 보안성을 강화할 수 있다
AI 컴퓨팅은 비트코인 PoW의 보완 수단이 되거나, 심지어 PoUW로 PoW를 대체할 수 있으며, 이는 보안을 유지하는 전제 하에 현재 비트코인 채굴에 사용되는 에너지를 AI 에이전트에 투입하는 혁신적인 변화를 가져옵니다. AI는 L2를 통해 비트코인을 지능 중심의 친환경 블록체인으로 만들 수 있으며, 이더리움의 PoS 방식과는 다릅니다. 우리가 제안한 초그래프 합의(Hypergraph Consensus)는 3D/AI 컴퓨팅 기반의 PoUW이며, 이후에 설명하겠습니다.
기타 탈중앙화 AI 프로젝트와 비교했을 때, HyperAGI는 어떤 독특한 점이 있습니까?
HyperAGI 프로젝트는 Web3 AI 분야에서 독보적이며, 비전, 솔루션, 기술 면에서 명확한 차이점을 보입니다. 솔루션 측면에서 보면, HyperAGI는 GPU 연산 능력의 합의화, AI의 구체화 및 자산화를 실현한, 탈중앙화된 반(半) AI 반(半) 금융 애플리케이션입니다. 최근 학계에서 탈중앙화 AI 플랫폼이 갖춰야 할 다섯 가지 특성을 제시했는데, 이를 바탕으로 기존의 탈중앙화 AI 관련 프로젝트들을 간략히 정리하고 비교해 보겠습니다.
탈중앙화 AI 플랫폼이 갖춰야 할 다섯 가지 특성은 다음과 같습니다:
(i) 원격 실행 AI 모델의 검증 가능성 (verifiability of remotely run models)
탈중앙화 검증 가능성은 Data Availability, ZK 등을 포함한 기술을 의미합니다.
(ii) 공개 AI 모델 API의 사용 가능성 (usability of publicly available AI models)
사용 가능성은 주로 AI 모델(LLM 중심) API를 제공하는 노드가 P2P 방식인지, 완전한 탈중앙화 네트워크인지 여부에 달려 있습니다.
(iii) AI 개발자와 사용자의 인센티브 메커니즘 (incentivization for AI developers and users)
인센티브에 공정한 토큰 생성 메커니즘이 포함되어 있는지 여부입니다.
(iv) 디지털 사회에서 실현 가능한 글로벌 AI 거버넌스 방안 (global governance of essential solutions in the digital society)
AI 거버넌스가 중립적이며 합의 도출이 쉬운지 여부입니다.
(v) 공급업체 종속성 회피 (no vendor lock-ins, etc.)
완전한 탈중앙화 플랫폼인지 여부입니다.
이 다섯 가지 특성을 기준으로 기존 공개된 계획 또는 실현된 프로젝트들을 정리해 보면 다음과 같습니다. (탈중앙화 연합학습은 오랜 실천에도 불구하고 중대한 진전을 이루지 못했으며, LLM의 부상으로 인해 이러한 탈중앙화 훈련은 더욱 어려워졌으므로 관련 프로젝트는 생략합니다.)
(i) 원격 실행 AI 모델의 검증 가능성
검증 가능성은 탈중앙화 AI 프로젝트의 필수 요건으로, 이후의 사용 가능성, 인센티브, 거버넌스, 종속성 회피의 기반이 되며, 검증 가능성이 없다면 다른 차원의 특성은 고려할 필요조차 없습니다. 검증 가능성이 없는 프로젝트는 탈중앙화된 컴퓨팅 리소스 임대나 데이터, 알고리즘, 모델 시장처럼 탈중앙화 프로젝트일 수는 있지만, AI의 탈중앙화라고 볼 수는 없습니다.
검증 가능성을 만족시킬 수 있는 프로젝트는 다음과 같습니다:
Giza: ZKML 합의 메커니즘 기반으로 원격 실행 AI 모델의 검증 가능성을 충족하지만, 현재 성능이 낮아 특히 대규모 모델 요구와는 여러 수준 차이가 납니다. 백만 단위 파라미터 소형 모델의 한 번의 증명에 수분이 소요되며, LLM 모델 증명에 이런 시간 소요는 받아들일 수 없습니다.
Cortex AI: 5년 전부터 탈중앙화 AI에 집중한 L1 공개 블록체인 프로젝트로 기술이 복잡하며, EVM 가상 머신에 신경망 계산을 위한 새 명령어를 추가하였습니다. 기반은 여전히 ZK 기반 가용성 검증이며 간단한 AI 모델에는 적합하지만 LLM 수준의 대규모 모델에는 부적합합니다.
Ofelimos: 암호학계에서 처음으로 PoUW 방안을 제안했으며, 특정 검색 알고리즘을 채택했습니다. 그러나 해당 알고리즘은 구체적인 애플리케이션 또는 프로젝트와 연결되어 있지 않습니다.
Project PAI: 논문에서 PoUW를 언급했지만 백서 수준에 머무르며 제품은 없음, https://oben.me/
Qubic: PoUW를 선언하며 수백 개의 GPU를 사용한 인공신경망 계산을 제안했지만, 파이썬 인공신경망 라이브러리의 단순 계산은 의미가 불분명하며, LLM 훈련 또는 추론 수요를 충족시키지 못하고 PoUW 역할도 하지 못합니다.
FLUX: (PoW ZelHash, PoUW 아님)
Coinai: (논문 단계) https://aipowergrid.io/, 작업 할당, 엄격한 합의 메커니즘 없음
불가능한 경우:
GPU 컴퓨팅 리소스 임대 프로젝트는 모두 탈중앙화 검증 메커니즘이 부족하여 원격 실행 AI 모델의 검증 가능성을 보장할 수 없습니다.
DeepBrain Chain: GPU 임대에 집중한 2017년 L1 프로젝트, 2021년 메인넷 출시;
EMC: 작업 할당 중심화 보상, 로드맵에 탈중앙화 합의 메커니즘 없음;
Atheir: 합의 메커니즘 확인되지 않음;
IO.NET: 합의 메커니즘 확인되지 않음;
CLORE.AI, POH: 크라우드소싱 모델, AI 모델 체인상 발표 및 결제, NFT 발행, AI는 체인 외부에서 실행되며 검증 가능성 없음. 동일한 모델의 다른 프로젝트: SingularityNET, Bittensor, AINN, Fetch.ai, oceanprotocol, algovera.ai.
(ii) 공개 AI 모델 API의 사용 가능성
Cortex AI: LLM 지원 확인되지 않음
Qubic: LLM 지원 확인되지 않음
위의 모든 탈중앙화 AI 프로젝트들은 상기 다섯 가지 문제에 대해 효과적으로 답변하지 못하고 있습니다. HyperAGI는 완전한 탈중앙화 AI 프로토콜로, Hypergraph PoUW 합의 메커니즘과 완전한 탈중앙화 비트코인 L2 스택을 기반으로 하며, 향후 비트코인 전용 AI L2로 업그레이드될 예정입니다.
PoUW는 네트워크를 가장 안전한 방식으로 보호하면서 계산 능력을 낭비하지 않도록 설계되었습니다. 채굴자가 제공하는 모든 계산 능력은 LLM 추론 및 클라우드 렌더링 서비스에 활용될 수 있습니다. PoUW의 비전은 제출된 다양한 문제를 분산형 네트워크에서 해결하는 데 계산 능력을 사용하는 것입니다.
왜 하필 지금입니까?
1. LLM 및 애플리케이션의 폭발적 성장
OpenAI의 ChatGPT는 3개월 만에 1억 명의 사용자를 달성하며, 언어 대규모 모델(LLM)의 개발, 응용, 투자 열풍이 전 세계를 휩쓸었습니다. 하지만 지금까지 LLM 기술과 훈련은 매우 중심화된 방식으로 이루어지고 있으며, 이에 따라 학계, 산업계, 대중의 우려가 커지고 있습니다. 주요 기술 제공업체들의 AI 기술 독점, 데이터 프라이버시 유출, 침해, 클라우드 컴퓨팅 기업의 공급업체 종속(lock-in) 등의 문제가 발생하고 있으며, 이는 모두 현재 인터넷 및 애플리케이션 접근이 중심화된 플랫폼에 의해 통제되기 때문이며, AI 대규모 응용에 적합한 네트워크가 부족하기 때문입니다. AI 커뮤니티는 로컬 실행 및 탈중앙화 AI 프로젝트를 시작하고 있으며, 로컬 실행의 대표는 Ollama, 탈중앙화의 대표는 Petals입니다. Ollama는 파라미터 압축이나 정밀도 저하를 통해 중소규모 LLM을 개인용 컴퓨터 또는 스마트폰에서 실행할 수 있게 하여 사용자 데이터의 프라이버시 권리와 기타 권익을 보호하지만, 생산 환경과 네트워크 연결 애플리케이션을 지원하기에는 어렵습니다. Petals는 BitTorrent의 P2P 기술을 통해 LLM의 완전한 탈중앙화 추론을 실현했습니다. 하지만 Petals는 합의 계층과 인센티브 계층 프로토콜이 부족하여 여전히 연구자 소수 그룹에 머물러 있습니다.
2. LLM 기반 에이전트
LLM의 발전으로 에이전트는 고차원 추론과 일정한 계획 능력을 갖게 되었으며, 자연어를 통해 다수의 에이전트가 인간처럼 사회적 협력을 형성할 수 있게 되었습니다. 마이크로소프트의 AutoGen, Langchain, CrewAI 등 다양한 LLM 기반 에이전트 프레임워크가 제안되었습니다.
현재 많은 AI 창업자와 개발자들이 LLM 기반 에이전트 및 그 응용 분야에 집중하고 있으며, 안정적이고 탄력적인 규모의 LLM 추론에 대한 수요가 큽니다. 하지만 현재는 주로 클라우드 컴퓨팅 기업에서 GPU 추론 인스턴스를 임대하여 해결하고 있습니다. NVIDIA는 2024년 3월 LLM을 포함한 생성형 AI 마이크로서비스 플랫폼 ai.nvidia.com을 발표했지만 아직 정식 출시되지 않았습니다. LLM 기반 에이전트는 과거 웹사이트 제작 붐처럼 활기를 띠고 있지만, 여전히 전통적인 Web2 모델로 협업하고 있으며, 에이전트 개발자는 GPU를 임대하거나 LLM 제공업체의 API를 구매하여 에이전트를 운영해야 하므로 마찰이 크며, 에이전트 생태계의 빠른 성장과 에이전트 경제의 가치 전달을 저해합니다.
3. 구체화된 에이전트 시뮬레이션 환경
현재 대부분의 에이전트가 접근하고 조작할 수 있는 대상은 단지 일부 API에 국한되며, 코드나 스크립트를 통해 이러한 API와 상호작용하여 LLM이 생성한 제어 명령을 작성하거나 외부 상태를 읽어옵니다. 범용 에이전트는 자연어를 이해하고 생성할 수 있을 뿐 아니라 인간 세계를 이해해야 하며, 필요한 훈련을 거쳐 드론, 청소로봇, 인간형 로봇 등의 로봇 시스템에 이식되어 특정 작업을 수행할 수 있어야 합니다. 이러한 에이전트를 구체화된 에이전트(embodied agent)라고 부릅니다.
구체화된 에이전트의 훈련에는 현실 세계의 시각 데이터가大量 필요하여 에이전트가 특정 환경과 현실 세계를 더 잘 이해하고, 로봇의 훈련 및 개발 시간을 단축하며, 훈련 효율을 높이고 비용을 절감할 수 있습니다. 현재 이러한 구체화된 지능 훈련을 위한 시뮬레이션 환경은 마이크로소프트의 Minecraft, NVIDIA의 Isaac Gym 등 소수 기업이 보유하고 있으며, 구체화된 지능 훈련을 위한 탈중앙화된 환경은 존재하지 않습니다. 최근 일부 게임 엔진이 인공지능에 주목하고 있으며, 에픽의 언리얼 엔진은 OpenAI GYM과 호환되는 AI 훈련 환경을 추진하고 있습니다.
4. 비트코인 L2 생태계
비트코인 사이드체인은 수년 전부터 존재했지만 주로 결제 용도로 사용되었으며, 스마트 계약의 부족으로 인해 복잡한 체인상 애플리케이션을 지원할 수 없었습니다. EVM 호환 비트코인 L2의 등장으로 비트코인이 L2를 통해 탈중앙화 AI와 같은 애플리케이션을 지원할 수 있게 되었습니다. 탈중앙화 AI는 완전한 탈중앙화, 연산 능력 중심의 블록체인 네트워크를 필요로 하며, 점점 더 중심화되는 PoS 블록체인 네트워크보다 적합합니다. 인스크립션, 룬(Runes) 등 비트코인 원생 자산 신규 프로토콜의 도입으로 비트코인 기반 생태계 및 애플리케이션 구축이 가능해졌습니다. 예를 들어 룬 HYPER•AGI•AGENT는 1시간 만에 공평한 발행(Fair Mint)을 완료했으며, 앞으로 HyperAGI는 비트코인 위에 더 많은 AI 자산 및 커뮤니티 주도 애플리케이션을 발행할 예정입니다.
HyperAGI의 기술 프레임워크 및 솔루션에 대해 이야기해 주세요.
1. 어떻게 탈중앙화된 LLM 기반 AI 에이전트 애플리케이션 플랫폼을 구현합니까?
현재 탈중앙화 AI의 가장 큰 문제는 대규모 AI 모델에 대한 원격 추론을 어떻게 실현할 것인지, 그리고 구체화된 에이전트의 훈련 및 추론에 고성능이며 낮은 오버헤드의 검증 가능한 알고리즘이 부족하다는 점입니다. 검증 가능성이 결여되면 시스템은 전통적인 수요-공급-플랫폼의 다자간 시장 모델로 후퇴할 수밖에 없으며, 완전한 탈중앙화 AI 애플리케이션 플랫폼을 실현할 수 없습니다.
검증 가능한 AI 컴퓨팅은 PoUW 합의 알고리즘이 필요합니다. 이를 기반으로 탈중앙화된 인센티브 메커니즘을 실현할 수 있습니다. 구체적으로 네트워크 인센티브에서 토큰 민팅은 노드가 계산 작업을 완료하고 검증 가능한 결과를 제출한 후 스스로 수행되며, 어떤 중심화된 방식으로 토큰을 노드에게 이전하는 것이 아닙니다.
AI 컴퓨팅의 검증 가능성을 실현하기 위해서는 먼저 AI 컴퓨팅을 정의해야 합니다. AI 컴퓨팅은 여러 계층이 있으며, 가장 낮은 수준의 기계 명령어, CUDA 명령어, C++, Python 언어가 있고, 구체화된 에이전트 훈련에 필요한 3D 컴퓨팅도 셰이더 언어, OpenGL, C++, 블루프린트 스크립트 등 다양한 계층이 있습니다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다 Telegram 구독 그룹:https://t.me/TechFlowDaily 트위터 공식 계정:https://x.com/TechFlowPost 트위터 영어 계정:https://x.com/BlockFlow_News













