

DeepSeekは完璧ではなく、訓練プロセスには「深度の呪い」が存在する
TechFlow厳選深潮セレクト
DeepSeekは完璧ではなく、訓練プロセスには「深度の呪い」が存在する
「深度呪い」の存在は、大規模言語モデルの訓練および最適化に深刻な課題をもたらしている。
高性能の大規模モデルの訓練には、通常数千個のGPUを必要とし、1回の訓練に数か月からそれ以上の時間がかかる。このような膨大なリソース投入により、モデルの各層が効率的に学習することが求められ、計算リソースの最大限の活用を確保しなければならない。
しかし、大連理工大学、西湖大学、オックスフォード大学などの研究者らがDeepSeek、Qwen、LlamaおよびMistralを調査したところ、これらのモデルの深層部分は訓練中に十分な性能を発揮しておらず、モデルの性能に影響を与えることなく完全に剪定できる可能性があることがわかった。
たとえば、研究者らはDeepSeek-7Bモデルに対して層ごとの剪定を行い、各層がモデル全体の性能に与える寄与度を評価した。その結果、深層を削除しても性能への影響は極めて小さく、一方で浅層を削除すると性能が明確に低下するという傾向が示された。これは、DeepSeekモデルの深層が訓練中に有用な特徴を効果的に学習できていない一方で、浅層が大部分の特徴抽出タスクを担っていることを意味している。
この現象は「深度の呪い(Curse of Depth)」と呼ばれており、研究者らはこれに対する有効な解決策としてLayerNorm Scaling(層正規化スケーリング)を提案している。

深度の呪いについて
「深度の呪い」という現象の根本原因はPre-LNの性質にある。Pre-LNはTransformerアーキテクチャのモデルで広く使われる正規化技術であり、出力ではなく各層の入力に対して正規化を行うものである。この正規化手法はモデルの訓練プロセスを安定させる効果があるものの、深刻な問題も引き起こす。モデルの深さが増すにつれて、Pre-LNの出力分散が指数関数的に増大してしまうのである。
この分散の爆発的増大により、深層のTransformerブロックにおける勾配が単位行列に近づき、その結果、これらの層は訓練中にほとんど有効な情報を提供できなくなる。言い換えれば、深層は訓練中に恒等写像と化し、有用な特徴を学習できなくなってしまう。
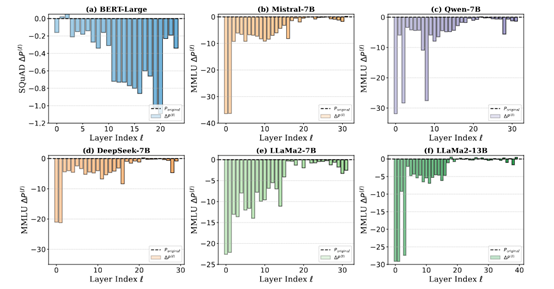
「深度の呪い」の存在は、大規模言語モデルの訓練および最適化において重大な課題をもたらす。まず、深層の不十分な学習がリソースの浪費を引き起こす。大規模言語モデルの訓練には大量の計算リソースと時間がかかるが、深層が有用な特徴を学習できていないため、計算リソースの多くが無駄になっている。
また、深層の無効性はモデル性能のさらなる向上を制限する。浅層が大部分の特徴抽出を担えているとしても、深層の無効性によってモデルはその深さによる利点を十分に活かせない。
さらに、「深度の呪い」はモデルの拡張性に対しても問題を提起する。モデル規模が大きくなるにつれ、深層の無効性はより顕著になり、モデルの訓練と最適化がますます困難になる。たとえば、超大規模モデルの訓練では、深層の学習不足によって収束速度が遅くなったり、収束できなくなったりする可能性がある。
解決法――LayerNorm Scaling
LayerNorm Scalingの核心的な考え方は、Pre-LNの出力分散を精密に制御することにある。多層構造のTransformerモデルでは、各層の層正規化出力に特定のスケーリング係数を乗算する。このスケーリング係数はその層の深さと密接に関連しており、層の深さの平方根の逆数となる。
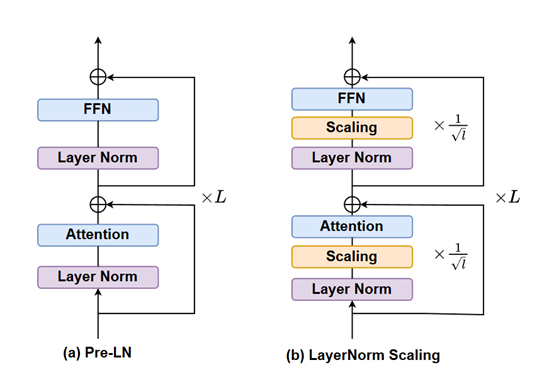
わかりやすく例えるなら、大規模モデルは高層ビルのようなもので、各層はその階層に相当する。LayerNorm Scalingとは、各階層の「エネルギー出力」を細かく調整する仕組みだと言える。

下層部(浅層)ではスケーリング係数が比較的大きく、つまり出力の調整幅が小さく、相対的に強い「エネルギー」を維持できる。一方、上層部(深層)ではスケーリング係数が小さくなり、深層の出力「エネルギー強度」が効果的に抑制され、分散の過剰蓄積が防がれる。
この方法により、モデル全体の出力分散が効果的に制御され、深層での分散爆発が生じなくなる。(計算プロセスはやや複雑なので、興味のある方は論文を直接参照されたい)
モデルの訓練の観点から見ると、従来のPre-LNモデルの訓練では、深層の分散が増大し続けることで逆伝播時の勾配に大きな干渉が生じる。深層の勾配情報が不安定になり、それはまるでリレー走行において、後半の選手がバトンを落としてしまうようなもので、情報伝達が滞る。
その結果、深層は有効な特徴を学習できず、モデル全体の訓練効果が大きく損なわれてしまう。一方、LayerNorm Scalingは分散を制御することで勾配の流れを安定させる。
逆伝播の過程で、勾配は出力層から入力層へよりスムーズに伝わるようになり、各層が正確かつ安定した勾配信号を受け取ることができ、より効果的にパラメータ更新と学習が行えるようになる。
実験結果
LayerNorm Scalingの有効性を検証するため、研究者らはさまざまな規模のモデルで広範な実験を行った。実験対象は1.3億パラメータから10億パラメータのモデルまでをカバーしている。
実験の結果、LayerNorm Scalingは事前学習段階でモデル性能を著しく向上させ、従来のPre-LNと比較してパープレキシティの低下と必要な学習トークン数の削減を実現した。
たとえば、LLaMA-130Mモデルでは、パープレキシティが26.73から25.76に低下し、10億パラメータのLLaMA-1Bモデルでは、17.02から15.71に低下した。これらの結果は、LayerNorm Scalingが深層の分散増加を効果的に抑制するだけでなく、モデルの学習効率と性能を大幅に向上させることを示している。
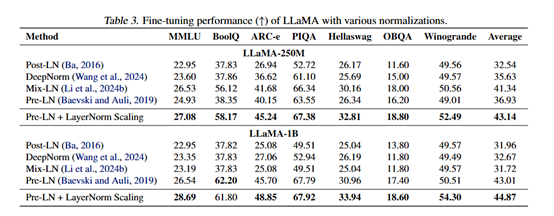
研究者らは、LayerNorm Scalingが教師あり微調整段階でどのように振る舞うかも評価した。実験の結果、LayerNorm Scalingは他の正規化技術と比べて複数の下流タスクで優れた性能を発揮した。
たとえば、LLaMA-250Mモデルでは、ARC-eタスクで3.56%の性能向上を達成し、すべてのタスクでの平均性能は1.80%向上した。これは、LayerNorm Scalingが事前学習段階で優れた成果を上げるだけでなく、微調整段階でもモデル性能を著しく向上させられることを示している。
さらに、研究者らはDeepSeek-7Bモデルの正規化手法を従来のPre-LNからLayerNorm Scalingに置き換えた。訓練全体を通じて、深層ブロックの学習能力が著しく向上し、モデルの学習プロセスに積極的に参加できるようになり、モデル性能の向上に貢献した。パープレキシティの低下幅はより顕著となり、低下のスピードもより安定した。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














