

DeepSeek n'est pas parfait, le processus d'entraînement présente un « malédiction de profondeur »
TechFlow SélectionTechFlow Sélection
DeepSeek n'est pas parfait, le processus d'entraînement présente un « malédiction de profondeur »
L'existence du « fléau de la profondeur » pose de graves défis à l'entraînement et à l'optimisation des grands modèles linguistiques.
L'entraînement de grands modèles haute performance nécessite généralement des milliers de GPU et peut prendre plusieurs mois, voire plus longtemps. Cet investissement massif en ressources exige que chaque couche du modèle soit efficacement entraînée afin d'optimiser l'utilisation de la puissance de calcul.
Cependant, des chercheurs de l'Université polytechnique de Dalian, de l'Université Westlake et de l'Université d'Oxford ont étudié DeepSeek, Qwen, Llama et Mistral et ont découvert que les couches profondes de ces modèles ne performaient pas bien durant l'entraînement, au point qu'elles pourraient être complètement élaguées sans affecter les performances du modèle.
Par exemple, les chercheurs ont effectué un élagage progressif par couche sur le modèle DeepSeek-7B afin d'évaluer la contribution de chaque couche aux performances globales. Les résultats montrent que la suppression des couches profondes a un impact négligeable sur les performances, tandis que la suppression des couches superficielles entraîne une baisse significative. Cela indique que les couches profondes de DeepSeek n'apprennent pas efficacement de caractéristiques utiles durant l'entraînement, alors que les couches superficielles assument la majeure partie de l'extraction de caractéristiques.
Ce phénomène est appelé « malédiction de la profondeur » (Curse of Depth). Les chercheurs proposent également une solution efficace : l'échelonnement de LayerNorm (LayerNorm Scaling).

Introduction à la malédiction de la profondeur
La racine du phénomène de « malédiction de la profondeur » réside dans les propriétés du Pre-LN. Le Pre-LN est une technique de normalisation largement utilisée dans les architectures de modèles Transformer, appliquée sur l'entrée de chaque couche plutôt que sur sa sortie. Bien que cette méthode stabilise l'entraînement, elle présente un problème grave : à mesure que la profondeur du modèle augmente, la variance de la sortie du Pre-LN croît de manière exponentielle.
Cette explosion de la variance fait que les dérivées des blocs Transformer profonds deviennent proches de la matrice identité, rendant ces couches presque inactives pendant l'entraînement et incapables d'apporter une information utile. Autrement dit, les couches profondes deviennent des applications identités, incapables d'apprendre des caractéristiques utiles.
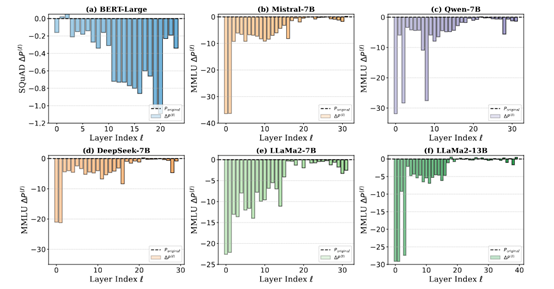
La présence de la « malédiction de la profondeur » pose de graves défis à l'entraînement et à l'optimisation des grands modèles linguistiques. Premièrement, l'entraînement insuffisant des couches profondes entraîne un gaspillage de ressources. L'entraînement de grands modèles requiert d'importantes capacités de calcul et du temps. Étant donné que les couches profondes n'apprennent pas efficacement, une grande partie de la puissance de calcul est gaspillée.
De plus, l'inefficacité des couches profondes limite l'amélioration ultérieure des performances du modèle. Bien que les couches superficielles puissent assumer la majorité de l'extraction de caractéristiques, l'inefficacité des couches profondes empêche le modèle de tirer pleinement parti de sa profondeur.
En outre, la « malédiction de la profondeur » crée des difficultés pour la scalabilité du modèle. À mesure que la taille du modèle augmente, l'inefficacité des couches profondes devient plus marquée, rendant l'entraînement et l'optimisation encore plus difficiles. Par exemple, lors de l'entraînement de modèles extrêmement volumineux, un entraînement insuffisant des couches profondes pourrait ralentir la convergence ou même empêcher la convergence du modèle.
Solution — LayerNorm Scaling
L'idée centrale de LayerNorm Scaling est le contrôle précis de la variance de sortie du Pre-LN. Dans un modèle Transformer multicouche, la sortie normalisée de chaque couche est multipliée par un facteur d'échelle spécifique. Ce facteur est étroitement lié à la profondeur de la couche actuelle et correspond à l'inverse de la racine carrée de la profondeur.
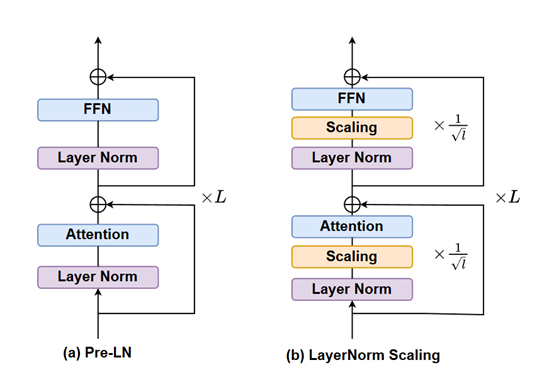
Pour illustrer simplement, un grand modèle est comme un gratte-ciel, chaque couche représentant un étage, et LayerNorm Scaling agit comme un réglage fin de la « puissance de sortie » de chaque étage.

Pour les étages inférieurs (couches superficielles), le facteur d'échelle est relativement grand, ce qui signifie que leurs sorties sont moins ajustées et conservent une « énergie » relativement forte. Pour les étages supérieurs (couches profondes), le facteur d'échelle est plus petit, réduisant ainsi efficacement l'« intensité énergétique » des couches profondes et évitant l'accumulation excessive de la variance.
Grâce à cette méthode, la variance de sortie de tout le modèle est efficacement contrôlée, empêchant l'explosion de variance dans les couches profondes. (Le processus de calcul est assez complexe ; ceux qui sont intéressés peuvent consulter directement l'article scientifique.)
D'un point de vue de l'entraînement, dans les modèles Pre-LN traditionnels, la variance croissante dans les couches profondes perturbe fortement la propagation des gradients. Ces derniers deviennent instables, comme si un témoin de relais tombait systématiquement durant les derniers tours, entravant la transmission de l'information.
Cela rend difficile pour les couches profondes d'apprendre des caractéristiques utiles, réduisant considérablement l'efficacité globale de l'entraînement. En revanche, LayerNorm Scaling stabilise le flux de gradients en contrôlant la variance.
Lors de la rétropropagation, les gradients peuvent circuler plus librement depuis la couche de sortie jusqu'à la couche d'entrée, permettant à chaque couche de recevoir un signal de gradient précis et stable, facilitant ainsi une mise à jour efficace des paramètres et un apprentissage plus performant.
Résultats expérimentaux
Pour valider l'efficacité de LayerNorm Scaling, les chercheurs ont mené de nombreuses expériences sur des modèles de différentes tailles, allant de 130 millions à 1 milliard de paramètres.
Les résultats montrent que LayerNorm Scaling améliore nettement les performances du modèle lors de la phase de pré-entraînement : comparé au Pre-LN traditionnel, il réduit la perplexité et diminue le nombre de tokens requis pour l'entraînement.
Par exemple, sur le modèle LLaMA-130M, LayerNorm Scaling fait passer la perplexité de 26,73 à 25,76. Sur le modèle LLaMA-1B (1 milliard de paramètres), elle passe de 17,02 à 15,71. Ces résultats démontrent que LayerNorm Scaling non seulement maîtrise efficacement la croissance de la variance dans les couches profondes, mais améliore aussi sensiblement l'efficacité et les performances de l'entraînement.
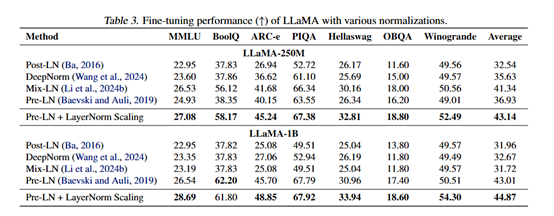
Les chercheurs ont également évalué les performances de LayerNorm Scaling lors de l'étape de réglage fin supervisé. Les expériences montrent que LayerNorm Scaling surpasse d'autres techniques de normalisation sur plusieurs tâches aval.
Par exemple, sur le modèle LLaMA-250M, LayerNorm Scaling améliore les performances de 3,56 % sur la tâche ARC-e, et le gain moyen sur toutes les tâches atteint 1,80 %. Cela confirme que LayerNorm Scaling excelle non seulement durant la pré-formation, mais améliore aussi significativement les performances lors du réglage fin.
En outre, les chercheurs ont remplacé la méthode de normalisation du modèle DeepSeek-7B, passant du Pre-LN traditionnel à LayerNorm Scaling. Tout au long de l'entraînement, la capacité d'apprentissage des blocs profonds s'est nettement améliorée, leur permettant de participer activement au processus d'apprentissage et de contribuer à l'amélioration des performances. La baisse de la perplexité est plus marquée et son rythme plus stable.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














