

TechFlow
TechFlow SélectionTechFlow Sélection
TechFlow
Sans historique professionnel, comment DeepSeek choisit-il ses candidats ? La réponse est : en regardant leur potentiel.
Auteur : Sam Gao, auteur d'ElizaOS
0. Avant-propos
Récemment, l'apparition en chaîne de DeepSeek V3 puis R1 a plongé les chercheurs, entrepreneurs et investisseurs américains dans un état de FOMO (peur de manquer quelque chose). Ce bouleversement peut être comparé à l'effet produit par la sortie de ChatGPT fin 2022.

Grâce à l’ouverture totale du modèle DeepSeek R1 (téléchargeable gratuitement sur HuggingFace pour inférence locale) et à son prix extrêmement bas (1 % du coût d’OpenAI o1), DeepSeek est devenu en seulement cinq jours l’application n°1 sur l’AppStore américain.
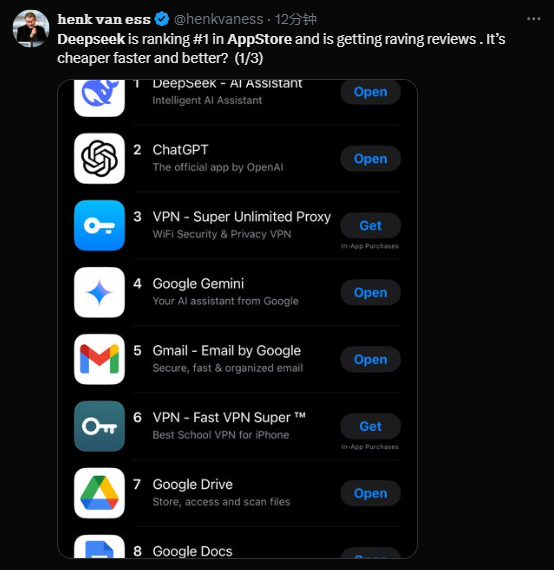
Mais d'où vient donc cette mystérieuse nouvelle force de l'IA, issue d'une société chinoise de trading algorithmique ?
1. Les origines de DeepSeek
J'ai entendu parler de DeepSeek pour la première fois en 2021. À l'époque, travaillant chez DAMO Academy, j'avais une collègue talentueuse du groupe voisin : Luo Fuli, diplômée de l'université de Pékin, qui avait publié huit articles à ACL (la conférence phare en traitement du langage naturel) en une seule année. Elle avait quitté DAMO pour rejoindre High-Flyer Quant. Tout le monde se demandait alors pourquoi une entreprise de quant si lucrative recrutait des talents en IA : avaient-ils besoin de publier des articles scientifiques ?
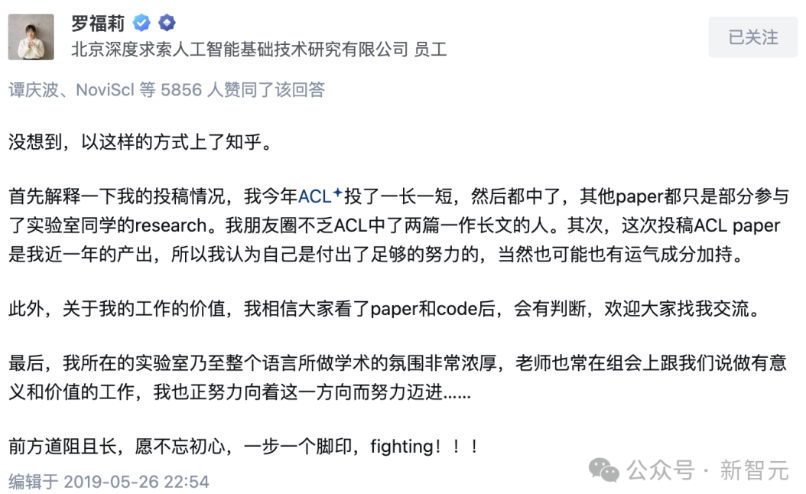
D'après ce que je savais, les chercheurs en IA recrutés par High-Flyer travaillaient initialement de manière indépendante, explorant divers axes innovants, dont les plus centraux étaient les grands modèles linguistiques (LLM) et les modèles de génération d'images à partir de texte (à l'époque, OpenAI Dall-e).
Fin 2022, High-Flyer a commencé à attirer un nombre croissant de talents d'élite en IA (pour la plupart des étudiants de Tsinghua ou de l’université de Pékin). Sous l'impulsion de ChatGPT, Liang Wenfeng, PDG de High-Flyer, décida fermement de s’engager dans le domaine de l’intelligence artificielle générale : « Nous avons créé une nouvelle entreprise, en commençant par les grands modèles linguistiques, puis nous développerons aussi la vision. »
Oui, cette entreprise s'appelle DeepSeek. Début 2023, alors que les « six dragons » — Zhipu, Moonshot, Baichuan Intelligence, etc. — montaient progressivement au devant de la scène, DeepSeek passait relativement inaperçu au milieu du tumulte frénétique des investissements autour de Zhongguancun et Wudaokou.
Ainsi, en 2023, en tant qu’institut purement académique sans fondateur star (comme Li Kaifu avec 01.ai, Yang Zhiyun avec Moonshot, ou Wang Xiaochuan avec Baichuan), il était difficile pour DeepSeek de lever des fonds sur le marché. High-Flyer a donc décidé de scinder DeepSeek et de financer entièrement son développement. À cette époque de folie spéculative, aucune société de capital-risque ne voulait investir dans DeepSeek : d’une part, parce que l’équipe était composée principalement de jeunes docteurs fraîchement diplômés, sans chercheurs renommés de premier plan ; d’autre part, parce que tout espoir de sortie en bourse semblait lointain.
Dans cet environnement bruyant et superficiel, DeepSeek a commencé à écrire ses propres chapitres dans l’exploration de l’IA :
-
Novembre 2023 : DeepSeek lance DeepSeek LLM, un modèle de 67 milliards de paramètres, dont les performances approchent celles de GPT-4.
-
Mai 2024 : DeepSeek-V2 est officiellement lancé.
-
Décembre 2024 : DeepSeek-V3 est publié. Les tests de référence montrent qu’il surpasse Llama 3.1 et Qwen 2.5, et atteint un niveau comparable à GPT-4o et Claude 3.5 Sonnet, suscitant un grand intérêt dans la communauté.
-
Janvier 2025 : DeepSeek-R1, la première génération de modèle doté de capacités de raisonnement, est lancé. Avec un prix inférieur à 1 % de celui d’OpenAI o1 et des performances exceptionnelles, il fait sensation dans le monde technologique : le monde prend enfin conscience que la puissance chinoise est réellement arrivée... L’open source triomphe toujours !
2. Stratégie de recrutement des talents
J’ai rencontré très tôt certains chercheurs de DeepSeek, principalement spécialisés dans le domaine AIGC, comme les auteurs de Janus (publié en novembre 2024) et DreamCraft3D, dont l’un m’a même aidé à optimiser mon dernier article @xingchaoliu.

Selon mes observations, la majorité des chercheurs que je connais sont très jeunes, principalement des doctorants ou des diplômés depuis moins de trois ans.


La plupart poursuivent leurs études supérieures à Pékin, et excellent sur le plan académique : souvent auteurs de 3 à 5 publications dans des conférences de premier plan.
J’ai demandé à un ami de DeepSeek pourquoi Liang Wenfeng ne recrutait que des jeunes.
Il m’a transmis les propos du PDG de High-Flyer, Liang Wenfeng :
Le mystère entourant l’équipe DeepSeek intrigue : quel est son secret ? Selon la presse étrangère, ce secret réside dans les « jeunes génies », capables de rivaliser avec les géants américains aux ressources colossales.
Dans l’industrie de l’IA, il est courant d’embaucher des experts expérimentés. De nombreuses startups chinoises préfèrent recruter des chercheurs chevronnés ou des docteurs formés à l’étranger. Pourtant, DeepSeek adopte une stratégie inverse, privilégiant des jeunes sans expérience professionnelle.
Un chasseur de têtes ayant collaboré avec DeepSeek a révélé qu'ils n’embauchaient pas de techniciens seniors : « Trois à cinq ans d’expérience, c’est déjà le maximum. Au-delà de huit ans, on écarte systématiquement. » En mai 2023, lors d’une interview accordée à 36Kr, Liang Wenfeng a confirmé que la majorité des développeurs de DeepSeek étaient soit des nouveaux diplômés, soit des débutants en IA. Il insiste : « La plupart de nos postes techniques clés sont occupés par des nouveaux diplômés ou des personnes ayant un à deux ans d’expérience. »
Comment DeepSeek sélectionne-t-il des profils sans expérience ? La réponse est simple : par le potentiel.
Liang Wenfeng a déclaré que pour un projet à long terme, l’expérience compte moins que les compétences fondamentales, la créativité et la passion. Il pense que les 50 meilleurs talents mondiaux en IA ne résident peut-être pas encore en Chine, « mais nous pouvons former ces talents nous-mêmes. »
Cette stratégie me rappelle celle d’OpenAI à ses débuts. Fondé fin 2015, Sam Altman avait choisi de recruter de jeunes chercheurs ambitieux. Ainsi, hormis le président Greg Brockman et le scientifique en chef Ilya Sutskever, les quatre autres membres fondateurs de l’équipe technique (Andrew Karpathy, Durk Kingma, John Schulman, Wojciech Zaremba) étaient tous des docteurs fraîchement diplômés, venus respectivement de Stanford, de l’université d’Amsterdam, de Berkeley et de l’université de New York.

De gauche à droite : Ilya Sutskever (ancien scientifique en chef), Greg Brockman (ancien président), Andrej Karpathy (ancien responsable technique), Durk Kingma (ancien chercheur), John Schulman (ancien responsable de l’apprentissage par renforcement) et Wojciech Zaremba (actuel responsable technique)
Cette « stratégie des loups juniors » a porté ses fruits pour OpenAI, permettant d’incuber des figures comme Alec Radford, père de GPT (diplômé d’une université privée modeste), Aditya Ramesh, créateur de DALL-E (étudiant de NYU), ou Prafulla Dhariwal, responsable multimodal de GPT-4o et triple médaillé olympique. Grâce à l’audace de ces jeunes, OpenAI, initialement un petit acteur dans l’ombre de DeepMind, a su tracer sa propre voie et devenir un géant.
Liang Wenfeng, inspiré par le succès de Sam Altman, a lui aussi opté pour cette voie. Contrairement à OpenAI, qui a dû attendre sept ans avant de voir émerger ChatGPT, Liang Wenfeng a obtenu des résultats tangibles en seulement deux ans : c’est là toute la rapidité chinoise.
3. Prendre position pour DeepSeek
Dans l'article annonçant DeepSeek R1, les indicateurs sont impressionnants. Pourtant, cela a suscité des doutes. Deux points ont été soulevés :
-
① L’utilisation de la technologie Mixture of Experts (MoE), exigeante en entraînement et en données, a conduit certains à soupçonner que DeepSeek aurait utilisé des données provenant d’OpenAI.
-
② L’utilisation de la technique d’apprentissage par renforcement (RL), très gourmande en matériel, semble difficile à concilier avec les ressources limitées : alors que Meta et OpenAI disposent de clusters de dizaines de milliers de GPU, DeepSeek n’aurait utilisé que 2048 cartes H800.
Étant donné les contraintes de puissance de calcul et la complexité de MoE, le succès de DeepSeek R1 avec un budget d’à peine 5 millions de dollars apparaît suspect. Que l’on admire son « miracle à faible coût » ou que l’on critique son « aspect spectaculaire mais creux », on ne peut ignorer l’éclat de son innovation fonctionnelle.
Arthur Hayes, cofondateur de BitMEX, a déclaré : « L’essor de DeepSeek pourrait-il amener les investisseurs mondiaux à remettre en question l’hégémonie américaine ? Les actifs américains sont-ils gravement surévalués ? »
Andrew Ng, professeur à l’université de Stanford, a affirmé publiquement lors du Forum de Davos cette année : « Je suis très impressionné par les progrès de DeepSeek. Je pense qu’ils ont réussi à entraîner leurs modèles de manière extrêmement économique. Leur dernier modèle de raisonnement est remarquable… Allez-y ! »
Marc Andreessen, cofondateur d’A16z, Marc Andreessen, a déclaré : « Deepseek R1 est l’une des avancées les plus stupéfiantes et impressionnantes que j’aie jamais vues — et en étant open source, c’est un cadeau profond offert au monde entier. »
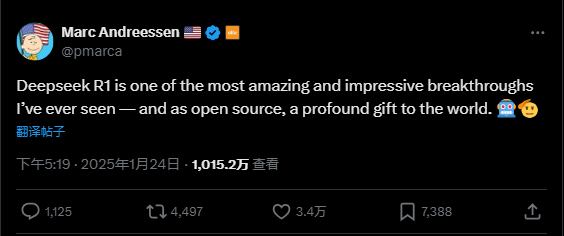
DeepSeek, resté dans l’ombre en 2023, est enfin monté au sommet mondial de l’IA en 2025, juste avant le Nouvel An lunaire.
4. Argo et DeepSeek
En tant que développeur technique d’Argo et chercheur en AIGC, j’ai intégré DeepSeek dans les fonctionnalités clés d’Argo. Dans notre système de workflow, la génération brute de workflows est désormais effectuée par DeepSeek R1. De plus, Argo intègre désormais DeepSeek R1 comme modèle LLM standard, abandonnant délibérément les modèles coûteux et fermés d’OpenAI. En effet, un système de workflow consomme généralement un grand nombre de tokens et nécessite un contexte important (moyenne ≥ 10 000 tokens). Utiliser des modèles chers comme OpenAI ou Claude 3.5 rendrait le coût d’exécution prohibitif. Avant que les utilisateurs web3 n’aient véritablement capté de la valeur, dépenser ainsi prématurément nuirait gravement au produit.
Avec l’amélioration constante de DeepSeek, Argo renforcera sa collaboration avec cette force chinoise représentée par DeepSeek, notamment en localisant les interfaces Text2Image/Video et en adoptant davantage de modèles LLM chinois.
Dans le cadre de cette coopération, Argo invitera à l’avenir des chercheurs de DeepSeek à partager leurs avancées techniques et accordera des subventions (grants) aux meilleurs chercheurs en IA, afin d’aider les investisseurs et utilisateurs web3 à mieux comprendre les progrès de l’IA.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














