

DeepSeek is not perfect and suffers from a "depth curse" during the training process
TechFlow Selected TechFlow Selected
DeepSeek is not perfect and suffers from a "depth curse" during the training process
The existence of the "depth curse" poses serious challenges to the training and optimization of large language models.
High-performance large models typically require thousands of GPUs and take months or even longer to complete a single training cycle. This massive resource investment necessitates efficient training across every model layer to maximize computational resource utilization.
However, researchers from Dalian University of Technology, Westlake University, and the University of Oxford, studying DeepSeek, Qwen, Llama, and Mistral, found that the deeper layers of these models perform poorly during training and can even be completely pruned without affecting model performance.
For example, researchers conducted layer-by-layer pruning on the DeepSeek-7B model to evaluate each layer's contribution to overall performance. The results showed that removing deep layers had negligible impact on performance, whereas removing shallow layers led to a significant decline. This indicates that the deep layers of the DeepSeek model fail to effectively learn useful features during training, while shallow layers carry out most of the feature extraction tasks.
This phenomenon is known as the "Curse of Depth," and the researchers also proposed an effective solution—LayerNorm Scaling (layer normalization scaling).

Introduction to the Curse of Depth
The root of the "Curse of Depth" lies in the characteristics of Pre-LN. Pre-LN is a normalization technique widely used in Transformer-based models, where normalization is applied to the input of each layer rather than the output. While this approach stabilizes the training process, it introduces a serious issue: as model depth increases, the output variance of Pre-LN grows exponentially.
This explosive growth in variance causes the derivatives of deep Transformer blocks to approach identity matrices, rendering these layers nearly ineffective during training. In other words, the deep layers become identity mappings and fail to learn meaningful features.
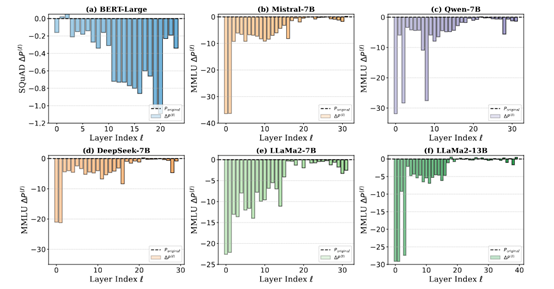
The existence of the "Curse of Depth" poses serious challenges for training and optimizing large language models. First, insufficient training of deep layers leads to resource waste. Training large language models demands substantial computational resources and time. Since deep layers fail to learn useful features effectively, computing power is largely wasted.
The ineffectiveness of deep layers also limits further improvements in model performance. Although shallow layers handle most feature extraction tasks, the inefficiency of deep layers prevents the model from fully leveraging its depth advantage.
Moreover, the "Curse of Depth" creates scalability issues. As model size increases, the ineffectiveness of deep layers becomes more pronounced, making training and optimization increasingly difficult. For instance, when training extremely large models, inadequate training of deep layers may slow convergence or even prevent convergence altogether.
Solution—LayerNorm Scaling
The core idea of LayerNorm Scaling is precise control over the output variance of Pre-LN. In a multi-layer Transformer model, the output of each layer’s normalization is multiplied by a specific scaling factor. This scaling factor is closely related to the current layer’s depth and is equal to the reciprocal of the square root of the layer index.
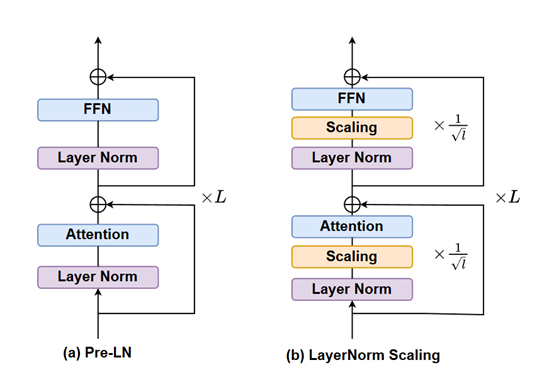
To illustrate with a simple analogy, a large model is like a tall building, with each floor representing a layer. LayerNorm Scaling fine-tunes the "energy output" of each floor.

For lower floors (shallow layers), the scaling factor is relatively large, meaning their outputs are adjusted less and maintain stronger "energy." For higher floors (deep layers), the scaling factor is smaller, effectively reducing the "energy intensity" of deep outputs and preventing excessive variance accumulation.
In this way, the overall output variance of the model is effectively controlled, eliminating the problem of variance explosion in deep layers. (The full computation process is complex; interested readers can refer directly to the paper.)
From the perspective of model training, in traditional Pre-LN models, the continuously increasing variance in deep layers significantly disrupts gradients during backpropagation. Gradient information in deep layers becomes unstable—like a relay baton frequently dropping during later stages of a race, causing disrupted information flow.
This makes it difficult for deep layers to learn useful features, greatly diminishing overall training effectiveness. LayerNorm Scaling stabilizes gradient flow by controlling variance.
During backpropagation, gradients can flow more smoothly from the output layer to the input layer. Each layer receives accurate and stable gradient signals, enabling more effective parameter updates and learning.
Experimental Results
To validate the effectiveness of LayerNorm Scaling, researchers conducted extensive experiments on models of various sizes, ranging from 130 million to 1 billion parameters.
The results showed that LayerNorm Scaling significantly improved model performance during pre-training, reducing perplexity and decreasing the number of tokens required for training compared to traditional Pre-LN.
For example, on the LLaMA-130M model, LayerNorm Scaling reduced perplexity from 26.73 to 25.76. On the 1-billion-parameter LLaMA-1B model, perplexity dropped from 17.02 to 15.71. These results demonstrate that LayerNorm Scaling not only effectively controls variance growth in deep layers but also significantly enhances training efficiency and model performance.
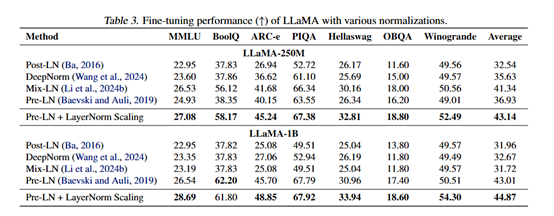
The researchers also evaluated LayerNorm Scaling during supervised fine-tuning. Experimental results showed that LayerNorm Scaling outperformed other normalization techniques across multiple downstream tasks.
For instance, on the LLaMA-250M model, LayerNorm Scaling improved performance on the ARC-e task by 3.56% and achieved an average performance improvement of 1.80% across all tasks. This indicates that LayerNorm Scaling excels not only during pre-training but also significantly boosts model performance during fine-tuning.
In addition, the researchers replaced the normalization method in the DeepSeek-7B model from traditional Pre-LN to LayerNorm Scaling. Throughout the training process, the learning capability of deep blocks was significantly enhanced, allowing them to actively participate in the learning process and contribute to performance improvements. The reduction in perplexity was more pronounced and stabilized faster.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














